パフォーマンスは、eコマース、決済システム、ゲーム、交通アプリなどの多くの消費者向け製品で非常に重要です。データベースは、現代の世界でのパフォーマンス要件を満たすために複数のメカニズムによって内部的に最適化されていますが、多くはアプリケーション開発者にも依存しています。結局のところ、アプリケーションが実行する必要のあるクエリを知っているのは開発者だけです。
リレーショナルデータベースを扱う開発者は、インデックス作成を使用したか、少なくとも聞いたことがあるでしょう。これは、データベースの世界では非常に一般的な概念です。ただし、最も重要な部分は、何にインデックスを付けるか、およびインデックスによってクエリの応答時間がどのように向上するかを理解することです。そのためには、データベーステーブルをクエリする方法を理解する必要があります。適切なインデックスを作成できるのは、クエリとデータアクセスのパターンがどのようなものかを正確に理解している場合のみです。
簡単な用語では、インデックスは、異なるメモリ内およびディスク上のデータ構造を使用して、検索キーをディスク上の対応するデータにマップします。インデックスは、検索するレコードの数を減らすことで検索を高速化するために使用されます。
ほとんどの場合、インデックスは WHEREで指定された列に作成されます データベースがそれらの列に基づいてテーブルからデータを取得およびフィルタリングするときのクエリの句。インデックスを作成しない場合、データベースはすべての行をスキャンし、一致する行を除外して結果を返します。数百万のレコードがあるため、このスキャン操作には数秒かかる場合があり、この高い応答時間により、APIとアプリケーションの速度が低下して使用できなくなります。例を見てみましょう—
MySQLをデフォルトのInnoDBデータベースエンジンで使用しますが、この記事で説明する概念は、Oracle、MSSQLなどの他のデータベースサーバーでもほぼ同じです。
index_demoというテーブルを作成します 次のスキーマを使用:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);InnoDBエンジンを使用していることを確認するにはどうすればよいですか?
次のコマンドを実行します:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;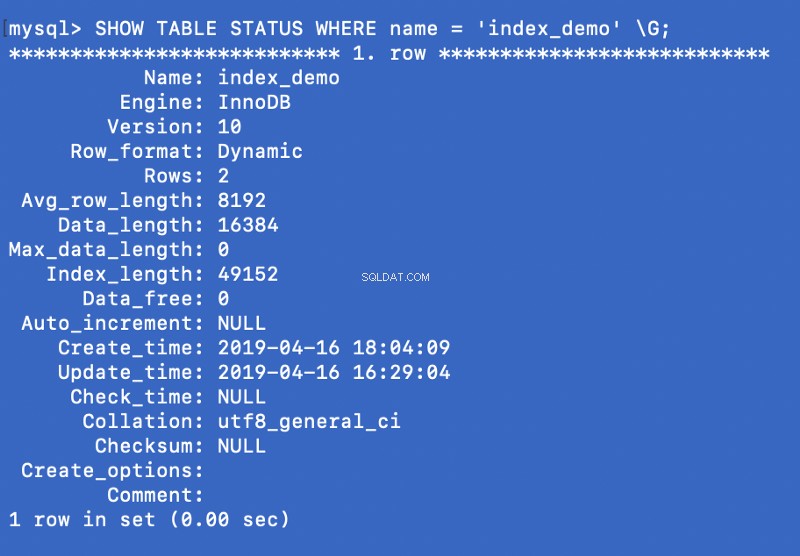
エンジン 上のスクリーンショットの列は、テーブルの作成に使用されるエンジンを表しています。ここでInnoDB 使用されます。
次に、テーブルにランダムなデータを挿入します。5行のテーブルは次のようになります。
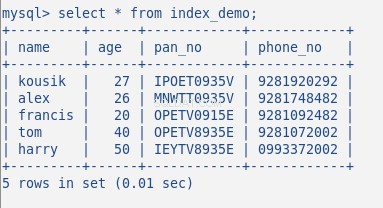
このテーブルには今までインデックスを作成していません。次のコマンドでこれを確認しましょう: SHOW INDEX 。 0件の結果を返します。

この時点で、単純な SELECTを実行すると クエリ。ユーザー定義のインデックスがないため、クエリはテーブル全体をスキャンして結果を見つけます。
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN クエリエンジンがクエリの実行を計画する方法を示します。上のスクリーンショットでは、行が表示されています。 列は5を返します &possible_keys nullを返します 。 possible_keys このクエリで使用できるすべての利用可能なインデックスが存在することを表します。 キー 列は、このクエリで使用可能なすべてのインデックスのうち、実際に使用されるインデックスを表します。
主キー:
上記のクエリは非常に非効率的です。このクエリを最適化しましょう。 phone_noを作成します 列aPRIMARY KEY 同じ電話番号を持つ2人のユーザーがシステムに存在できないと仮定します。主キーを作成するときは、次の点に注意してください。
- 主キーは、アプリケーションの多くの重要なクエリの一部である必要があります。
- 主キーは、テーブルの各行を一意に識別する制約です。複数の列が主キーの一部である場合、その組み合わせは行ごとに一意である必要があります。
- 主キーはnull以外である必要があります。 null可能なフィールドを主キーにしないでください。 ANSI SQL規格では、主キーは互いに比較可能である必要があり、特定の行の主キー列の値が他の行と同じであるか、小さいか、等しいかを確実に判断できる必要があります。
NULL以降 SQL標準で未定義の値を意味し、NULLを決定論的に比較することはできません 他の値を使用するため、論理的にNULL許可されていません。 - 理想的な主キーの種類は、
INTのような数字である必要があります またはBIGINT整数の比較が高速であるため、インデックスのトラバースは非常に高速になります。
多くの場合、 idを定義します AUTO INCREMENTとしてのフィールド テーブルでそれを主キーとして使用しますが、主キーの選択は開発者によって異なります。
主キーを自分で作成しない場合はどうなりますか?
主キーを自分で作成する必要はありません。主キーを定義していない場合、InnoDBは設計上すべてのテーブルに主キーを持っている必要があるため、InnoDBは暗黙的に主キーを作成します。したがって、後でそのテーブルの主キーを作成すると、InnoDBは以前に自動定義された主キーを削除します。
現在、主キーが定義されていないため、デフォルトで作成されたInnoDBを見てみましょう。
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED ユーザーが使用できないが、MySQLによって完全に管理されているすべてのインデックスを表示します。
ここでは、MySQLが DB_ROW_ID に複合インデックスを定義していることがわかります(複合インデックスについては後で説明します)。 、 DB_TRX_ID 、 DB_ROLL_PTR 、&テーブルで定義されているすべての列。ユーザー定義の主キーがない場合、このインデックスはレコードを一意に検索するために使用されます。
keyという用語は & index keyは同じ意味で使用されます 列の動作に課せられる制約を意味します。この場合、制約は、主キーが各行を一意に識別するnull不可のフィールドであるということです。一方、 index は、テーブル全体のデータ検索を容易にする特別なデータ構造です。
phone_noにプライマリインデックスを作成しましょう 作成したインデックスを調べます:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
CREATE INDEXに注意してください プライマリインデックスの作成には使用できませんが、 ALTER TABLE 使用されます。

上のスクリーンショットでは、1つのプライマリインデックスが列 phone_noに作成されていることがわかります。 。次の画像の列は次のように説明されています:
テーブル :インデックスが作成されるテーブル。
Non_unique :値が1の場合、インデックスは一意ではありません。値が0の場合、インデックスは一意です。
Key_name :作成されたインデックスの名前。プライマリインデックスの名前は常にPRIMARYです。 MySQLでは、インデックスの作成中にインデックス名を指定したかどうかに関係なく。
Seq_in_index :インデックス内の列のシーケンス番号。複数の列がインデックスの一部である場合、シーケンス番号は、インデックス作成時の列の順序に基づいて割り当てられます。シーケンス番号は1から始まります。
照合 :インデックスで列がどのようにソートされるか。 A 昇順を意味し、 D 降順を意味し、 NULL ソートされていないことを意味します。
カーディナリティ :インデックス内の一意の値の推定数。カーディナリティが高いほど、クエリオプティマイザがクエリのインデックスを選択する可能性が高くなります。
Sub_part :インデックスプレフィックス。 NULLです 列全体にインデックスが付けられている場合。それ以外の場合は、列が部分的にインデックス付けされている場合のインデックス付けされたバイト数を示します。部分インデックスは後で定義します。
パック :キーのパック方法を示します。 NULL そうでない場合。
Null :はい 列にNULLが含まれている可能性がある場合 値を指定し、そうでない場合は空白にします。
Index_type :このインデックスに使用されるインデックスデータ構造を示します。考えられる候補は次のとおりです— BTREE 、 HASH 、 RTREE 、または FULLTEXT 。
コメント :独自の列に記載されていないインデックスに関する情報。
Index_comment : COMMENTでインデックスを作成したときに指定したインデックスのコメント 属性。
次に、このインデックスによって、特定の phone_noで検索される行数が減少するかどうかを確認しましょう。 WHEREで クエリの句。
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
このスナップショットでは、 rowsに注意してください。 列が1を返しました のみ、possible_keys & key どちらもPRIMARYを返します 。つまり、基本的には、 PRIMARYという名前のプライマリインデックスを使用することを意味します。 (名前は主キーの作成時に自動的に割り当てられます)、クエリオプティマイザはレコードに直接移動してフェッチします。とても効率的です。これはまさにインデックスの目的です—余分なスペースを犠牲にして検索範囲を最小化するためです。
クラスター化インデックス:
クラスター化されたインデックス 同じ表スペースまたは同じディスク・ファイル内のデータと同じ場所に配置されます。クラスタ化インデックスはB-Treeであると見なすことができます インデックスとデータが一緒に存在するため、リーフノードがディスク上の実際のデータブロックであるインデックス。この種のインデックスは、インデックスキーの論理的な順序に従って、ディスク上のデータを物理的に整理します。
物理的には、データは数千または数百万のディスク/データブロックにまたがってディスク上に編成されます。クラスタ化されたインデックスの場合、すべてのディスクブロックが伝染的に保存されることは必須ではありません。物理データブロックは、必要に応じてOSによって常にあちこちに移動されます。データベースシステムは、物理データスペースの管理方法を完全に制御することはできませんが、データブロック内では、インデックスキーの論理的な順序でレコードを保存または管理できます。次の簡略図で説明しています:
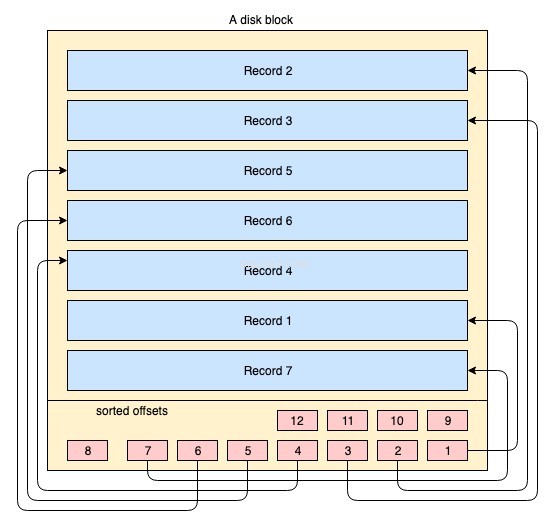
- 黄色の大きな長方形はディスクブロック/データブロックを表します
- 青色の長方形は、そのブロック内の行として保存されたデータを表します
- フッター領域は、特定のキーの並べ替えられた順序で赤い色の小さな長方形が存在するブロックのインデックスを表します。これらの小さなブロックは、レコードのオフセットを指す一種のポインタにすぎません。
レコードは、任意の順序でディスクブロックに保存されます。新しいレコードが追加されるたびに、それらは次に使用可能なスペースに追加されます。既存のレコードが更新されるたびに、OSは、そのレコードが同じ位置に収まるか、新しい位置をそのレコードに割り当てる必要があるかを判断します。
したがって、レコードの位置はOSによって完全に処理され、2つのレコードの順序の間に明確な関係は存在しません。キーの論理的な順序でレコードをフェッチするために、ディスクページにはフッターにインデックスセクションが含まれ、インデックスにはキーの順序でオフセットポインタのリストが含まれます。レコードが変更または作成されるたびに、インデックスが調整されます。
このように、実際に物理レコードを特定の順序で整理する必要はありません。小さなインデックスセクションがその順序で維持され、レコードの取得または維持が非常に簡単になります。
クラスター化インデックスの利点:
この関連データの順序付けまたはコロケーションにより、実際にはクラスター化インデックスが高速になります。データがディスクからフェッチされると、ディスクIOシステムがデータをブロック単位で読み書きするため、データを含む完全なブロックがシステムによって読み取られます。したがって、範囲クエリの場合、併置されたデータがメモリにバッファリングされる可能性があります。次のクエリを実行するとします:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
クエリが実行されると、データブロックがメモリにフェッチされます。データブロックにphone_noが含まれているとします 9010000000の範囲 9030000000へ 。したがって、クエリで要求した範囲は、ブロックに存在するデータのサブセットにすぎません。次のクエリを実行して、範囲内のすべての電話番号を取得する場合、たとえば 9015000000から 9019000000へ 、ディスクからこれ以上ブロックをフェッチする必要はありません。完全なデータは、現在のデータブロック、つまり clustered_indexにあります。 同じデータブロック内で可能な限り関連データを収集することにより、ディスクIOの数を減らします。このディスクIOの低下により、パフォーマンスが向上します。
したがって、主キーについてよく考えており、クエリが主キーに基づいている場合、パフォーマンスは非常に高速になります。
クラスター化インデックスの制約:
クラスター化されたインデックスはデータの物理的な編成に影響を与えるため、テーブルごとに1つのクラスター化されたインデックスしか存在できません。
主キーとクラスター化インデックスの関係:
MySQLのInnoDBを使用して、クラスター化インデックスを手動で作成することはできません。 MySQLがあなたに代わってそれを選択します。しかし、それはどのように選択しますか?次の抜粋はMySQLドキュメントからのものです:
PRIMARY KEYを定義する場合 テーブル上で、InnoDBクラスタ化されたインデックスとして使用します。作成する各テーブルの主キーを定義します。論理的に一意でnull以外の列または列のセットがない場合は、値が自動的に入力される新しい自動インクリメント列を追加します。
PRIMARY KEYを定義しない場合 テーブルの場合、MySQLは最初のUNIQUEを見つけます すべてのキー列がNOTNULLであるインデックス およびInnoDBクラスタ化されたインデックスとして使用します。
テーブルにPRIMARYKEYがない場合 または適切なUNIQUEインデックス、InnoDBGEN_CLUST_INDEXという名前の非表示のクラスター化インデックスを内部的に生成します 行ID値を含む合成列。行は、InnoDBというIDで並べ替えられます そのようなテーブルの行に割り当てます。行IDは6バイトのフィールドであり、新しい行が挿入されると単調に増加します。したがって、行IDで並べ替えられた行は、物理的に挿入順になります。
つまり、MySQL InnoDBエンジンは、パフォーマンスを向上させるために、実際にはプライマリインデックスをクラスター化インデックスとして管理するため、プライマリキーとディスク上の実際のレコードは一緒にクラスター化されます。
主キー(クラスター化)インデックスの構造:
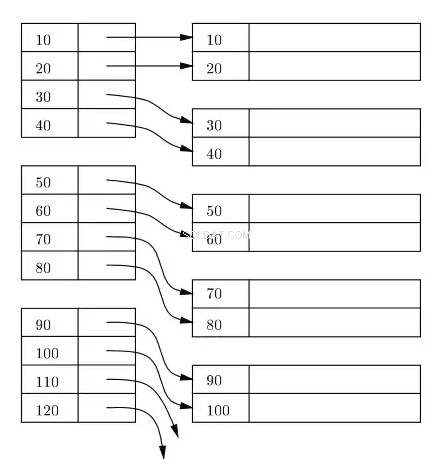
インデックスは通常、ディスク上およびメモリ内にB +ツリーとして維持され、インデックスはディスク上のブロックに格納されます。これらのブロックはインデックスブロックと呼ばれます。インデックスブロックのエントリは、常にインデックス/検索キーで並べ替えられます。インデックスのリーフインデックスブロックには、行ロケーターが含まれています。プライマリインデックスの場合、行ロケーターは、行が存在するディスク上のデータブロックの対応する物理的な場所の仮想アドレスを参照し、インデックスキーに従って並べ替えられます。
次の図で、左側の長方形はリーフレベルのインデックスブロックを表し、右側の長方形はデータブロックを表します。論理的には、データブロックは並べ替えられた順序で配置されているように見えますが、すでに説明したように、実際の物理的な場所はあちこちに散らばっている可能性があります。
非主キーに主インデックスを作成することは可能ですか?
>MySQLでは、プライマリインデックスが自動的に作成され、MySQLがプライマリインデックスを選択する方法についてはすでに説明しました。ただし、データベースの世界では、実際には主キー列にインデックスを作成する必要はありません。主キー列にインデックスを作成することもできます。ただし、主キーで作成された場合、すべてのキーエントリはインデックス内で一意ですが、それ以外の場合は、主キーにも重複したキーが含まれる可能性があります。
主キーを削除することはできますか?
主キーを削除することができます。主キーを削除すると、関連するクラスター化されたインデックスとその列の一意性プロパティが失われます。
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"プライマリインデックスの利点:
- プライマリインデックスベースの範囲クエリは非常に効率的です。プライマリインデックスがクラスター化され、レコードが物理的に順序付けられているため、データベースがディスクから読み取ったディスクブロックにクエリに属するすべてのデータが含まれている可能性があります。したがって、データの局所性はプライマリインデックスによって提供できます。
- 主キーを利用するクエリはすべて非常に高速です。
プライマリインデックスのデメリット:
- プライマリインデックスには仮想アドレス空間を介したデータブロックアドレスへの直接参照が含まれ、ディスクブロックはインデックスキーの順序で物理的に編成されるため、OSが
DMLによりディスクページを分割するたびにINSERTのような操作 /UPDATE/DELETE、プライマリインデックスも更新する必要があります。したがって、DML操作は、プライマリインデックスのパフォーマンスにいくらかの圧力をかけます。
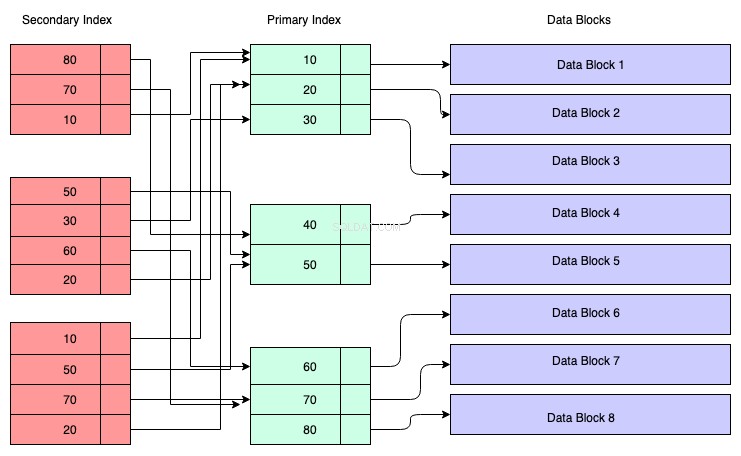
セカンダリインデックス:
クラスタ化されたインデックス以外のインデックスは、セカンダリインデックスと呼ばれます。セカンダリインデックスは、プライマリインデックスとは異なり、物理的なストレージの場所に影響を与えません。
いつセカンダリインデックスが必要ですか?
アプリケーションには、主キーを使用してデータベースにクエリを実行しないユースケースがいくつかある場合があります。この例では、 phone_no は主キーですが、 pan_noを使用してデータベースにクエリを実行する必要がある場合があります 、または name 。このような場合、このようなクエリの頻度が非常に高い場合は、これらの列にセカンダリインデックスが必要です。
MySQLでセカンダリインデックスを作成する方法
次のコマンドは、 nameにセカンダリインデックスを作成します index_demoの列 テーブル。
CREATE INDEX secondary_idx_1 ON index_demo (name);
セカンダリインデックスの構造:
次の図で、赤い色の長方形はセカンダリインデックスブロックを表しています。セカンダリインデックスもB+ツリーで維持され、インデックスが作成されたキーに従って並べ替えられます。リーフノードには、プライマリインデックスの対応するデータのキーのコピーが含まれています。
したがって、理解するために、そうではありませんが、セカンダリインデックスがプライマリキーのアドレスを参照していると想定できます。セカンダリインデックスを介してデータを取得するということは、2つのB+ツリーをトラバースする必要があることを意味します。1つはセカンダリインデックスB+ツリー自体であり、もう1つはプライマリインデックスB+ツリーです。
セカンダリインデックスの利点:
論理的には、必要な数のセカンダリインデックスを作成できます。しかし実際には、各インデックスには独自のペナルティがあるため、実際に必要なインデックスの数には真剣な思考プロセスが必要です。
セカンダリインデックスのデメリット:
DMLを使用 DELETEのような操作 / INSERT 、主キー列のコピーを削除/挿入できるように、セカンダリインデックスも更新する必要があります。このような場合、セカンダリインデックスが多数存在すると、問題が発生する可能性があります。
また、主キーが URLのように非常に大きい場合 、セカンダリインデックスには主キー列の値のコピーが含まれているため、ストレージの観点から非効率になる可能性があります。二次キーが多いほど、主キー列の値の重複コピーの数が増えるため、主キーが大きい場合はストレージが増えます。また、主キー自体がキーを格納するため、ストレージへの複合効果は非常に高くなります。
プライマリインデックスを削除する前の考慮事項:
MySQLでは、主キーを削除することで主インデックスを削除できます。セカンダリインデックスがプライマリインデックスに依存することはすでに見てきました。したがって、プライマリインデックスを削除する場合は、MySQLが自動調整する新しいプライマリインデックスキーのコピーを含むように、すべてのセカンダリインデックスを更新する必要があります。
複数のセカンダリインデックスが存在する場合、このプロセスはコストがかかります。また、他のテーブルには主キーへの外部キー参照がある場合があるため、主キーを削除する前にそれらの外部キー参照を削除する必要があります。
主キーが削除されると、MySQLは自動的に別の主キーを内部で作成しますが、これはコストのかかる操作です。
一意キーインデックス:
主キーと同様に、一意キーも1つの違いでレコードを一意に識別できます。つまり、一意キー列に nullを含めることができます。 値。
他のデータベースサーバーとは異なり、MySQLでは一意のキー列に nullをいくつでも含めることができます 可能な限りの値。 SQL標準では、 null 未定義の値を意味します。したがって、MySQLに nullを1つだけ含める必要がある場合 一意キー列の値の場合、すべてのnull値が同じであると想定する必要があります。
ただし、 null であるため、論理的には正しくありません。 未定義を意味します—そして未定義の値は互いに比較することができません。それは nullの性質です 。すべてのnullの場合、MySQLはアサートできないため sは同じ意味で、複数の nullを許可します 列の値。
次のコマンドは、MySQLで一意のキーインデックスを作成する方法を示しています。
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
複合インデックス:
MySQLでは、最大16列の複数の列にインデックスを定義できます。このインデックスは、複数列/複合/複合インデックスと呼ばれます。
4つの列にインデックスが定義されているとします— col1 、 col2 、 col3 、 col4 。複合インデックスを使用すると、 col1で検索機能を利用できます。 、(col1、col2) 、(col1、col2、col3) 、(col1、col2、col3、col4) 。したがって、インデックス付きの列の左側のプレフィックスを使用できますが、中央から列を省略して、次のように使用することはできません— (col1、col3) または(col1、col2、col4) またはcol3 またはcol4 など。これらは無効な組み合わせです。
次のコマンドは、テーブルに2つの複合インデックスを作成します。
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
WHEREを含むクエリがある場合 複数の列に句を指定する場合は、複合インデックスの列の順序で句を記述します。インデックスはそのクエリに役立ちます。実際、複合インデックスの列を決定する際に、システムのさまざまなユースケースを分析し、ほとんどのユースケースに役立つ列の順序を考え出すことができます。
複合インデックスは、 JOINで役立ちます & SELECT クエリも。例:次の SELECT * クエリ、 compose_index_2 使用されます。

複数のインデックスが定義されている場合、MySQLクエリオプティマイザはそのインデックスを選択して、最大数の行を削除するか、効率を高めるためにできるだけ少ない行をスキャンします。
複合インデックスを使用する理由?関心のある列に複数のセカンダリインデックスを定義してみませんか?
MySQLは、UNIONを除いて、クエリごとにテーブルごとに1つのインデックスのみを使用します。 (UNIONでは、各論理クエリが個別に実行され、結果がマージされます。)したがって、複数の列に複数のインデックスを定義しても、それらがクエリの一部であっても、それらのインデックスが使用されるとは限りません。
MySQLは、MySQLがシステムでデータがどのように見えるかを推測するのに役立つインデックス統計と呼ばれるものを維持しています。インデックス統計は一般化されていますが、このメタデータに基づいて、MySQLは現在のクエリに適切なインデックスを決定します。
複合インデックスで使用される列は連結され、それらの連結されたキーはB+ツリーを使用してソートされた順序で格納されます。検索を実行すると、検索キーの連結が複合インデックスの連結と照合されます。次に、検索キーの順序と複合インデックス列の順序に不一致がある場合、そのインデックスは使用できません。
この例では、次のレコードの場合、複合インデックスキーは pan_noを連結することによって形成されます。 、 name 、 age — HJKXS9086Wkousik28 。
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090複合インデックスが必要かどうかを識別する方法:
- ユースケースに従って、最初にクエリを分析します。多くのクエリで特定のフィールドが一緒に表示されている場合は、複合インデックスの作成を検討してください。
-
col1でインデックスを作成する場合 &(col1の複合インデックス 、col2)、複合インデックスのみが適切である必要があります。col1複合インデックス自体はインデックスの左側のプレフィックスであるため、単独で提供できます。 - カーディナリティを考慮してください。複合インデックスで使用される列のカーディナリティが高い場合は、複合インデックスの候補として適しています。
カバーインデックス:
カバーリングインデックスは、クエリで指定されたすべての列がインデックスのどこかに存在する特殊な種類の複合インデックスです。したがって、クエリオプティマイザは、データを取得するためにデータベースにアクセスする必要はありません。むしろ、インデックス自体から結果を取得します。例:(pan_no、name、age)に複合インデックスをすでに定義しています 、ここで次のクエリを検討してください:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
SELECTに記載されている列 & WHERE 句は複合インデックスの一部です。したがって、この場合、実際に ageの値を取得できます。 複合インデックス自体からの列。 EXPLAINが何であるか見てみましょう このクエリに対してコマンドが表示されます:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';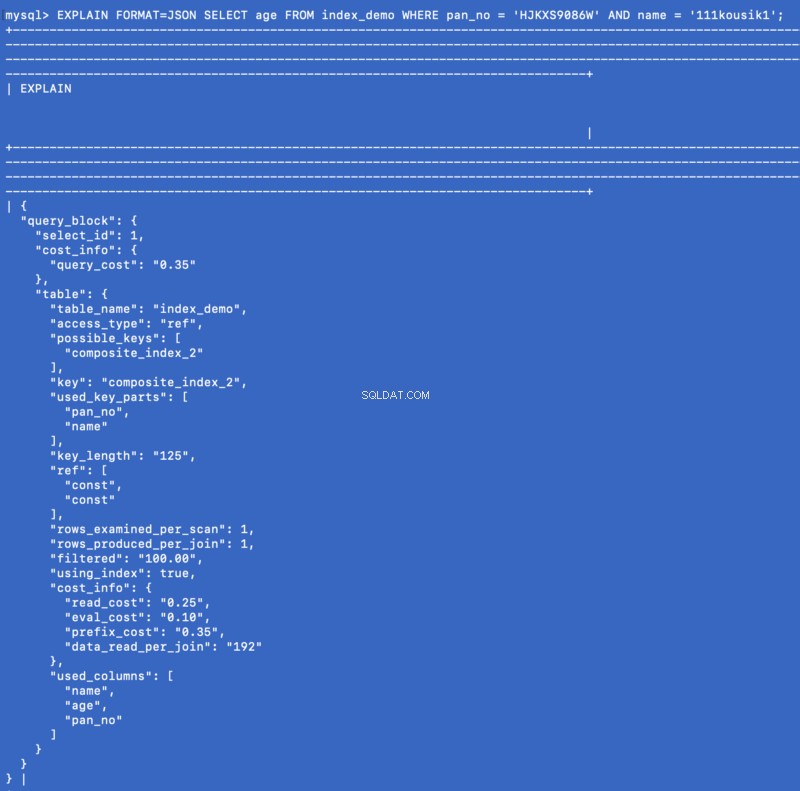
上記の応答では、キーが存在することに注意してください— using_index これはtrueに設定されています これは、カバーインデックスがクエリへの回答に使用されたことを意味します。
実稼働環境でカバーするインデックスがどれだけ高く評価されているかはわかりませんが、クエリが適切な場合に最適化するのは良いようです。
部分インデックス:
インデックスはスペースを犠牲にしてクエリを高速化することはすでに知っています。インデックスが多いほど、ストレージ要件も高くなります。すでにsecondary_idx_1というインデックスを作成しています 列name 。列name 任意の長さの大きな値を含めることができます。また、インデックスでは、行ロケーターまたは行ポインターのメタデータに独自のサイズがあります。したがって、全体として、インデックスはストレージとメモリの負荷が高くなる可能性があります。
MySQLでは、データの最初の数バイトにもインデックスを作成できます。例:次のコマンドは、nameの最初の4バイトにインデックスを作成します。この方法ではメモリのオーバーヘッドがある程度削減されますが、この例では最初の4バイトが多くの名前に共通している可能性があるため、インデックスで多くの行を削除することはできません。通常、この種のプレフィックスインデックスは、 CHARでサポートされています。 、 VARCHAR 、 BINARY 、 VARBINARY 列のタイプ。
CREATE INDEX secondary_index_1 ON index_demo (name(4));インデックスを定義すると、内部で何が起こりますか?
SHOW EXTENDEDを実行してみましょう もう一度コマンド:
SHOW EXTENDED INDEXES FROM index_demo;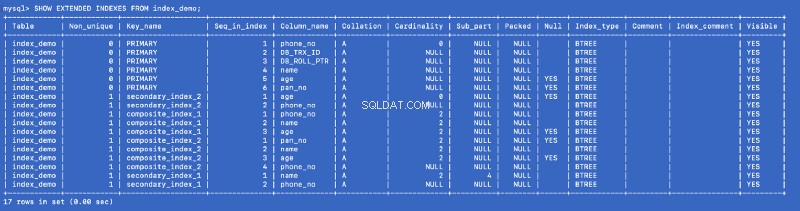
Secondary_index_1を定義しました name 、ただし、MySQLは( name に複合インデックスを作成しました 、 phone_no )ここで phone_no 主キー列です。 secondsary_index_2を作成しました age &MySQLは( age に複合インデックスを作成しました 、 phone_no )。 compose_index_2を作成しました on( pan_no 、 name 、 age )&MySQLは( pan_noに複合インデックスを作成しました 、 name 、 age 、 phone_no )。複合インデックスcomposite_index_1 すでにphone_noがあります その一部として。
したがって、作成するインデックスが何であれ、バックグラウンドのMySQLは、主キーを指すバッキング複合インデックスを作成します。これは、主キーがMySQLインデックス作成の世界で第一級市民であることを意味します。 It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html