あなたのコメントに関連して:
@MarcBデータベースは正規化されており、CSV文字列はUIから取得されます。 "次のユーザーのデータを取得してください:101,202,303"
この回答は、コンマで区切られた数字だけに焦点を絞っています。なぜなら、結局のところ、あなたは FIND_IN_SETについてさえ話していなかったからです。 結局のところ。
はい、あなたはあなたが望むものを達成することができます。この CREATE PROCEDUREを示す2番目のブロックを見てください。 (1,2,3)のような文字列を受け入れる2番目のパラメータ 。すぐにこの時点に戻ります。
@spraffを見る必要があるわけではありませんが、他の人は見る必要があります。使命は、 typeを取得することです !=ALL、およびpossible_keys およびキー 2番目のブロックで示したように、nullを表示しないように説明します。このトピックに関する一般的な読み物については、理解の記事を参照してください。 EXPLAINの出力
および
ここで、(1,2,3)に戻ります。 上記の参照。あなたのコメントとあなたの質問の2番目のExplain出力から、次の望ましい条件に当てはまることがわかります。
- type =range(特にALLではない)。これについては上記のドキュメントを参照してください。
- キーがnullではありません
これらは、正確には2番目のExplain出力にある条件であり、次のクエリで表示できる出力です。
explain
select * from ratings where id in (2331425, 430364, 4557546, 2696638, 4510549, 362832, 2382514, 1424071, 4672814, 291859, 1540849, 2128670, 1320803, 218006, 1827619, 3784075, 4037520, 4135373, ... use your imagination ..., ..., 4369522, 3312835);
ここで、その inには999個の値があります 条項リスト。これは、この回答
のサンプルです。 付録Dの私のものは、開いた括弧と閉じた括弧で囲まれたcsvのそのようなランダムな文字列を生成します。
また、以下の句の999要素に関する次のExplain出力に注意してください。

目的は達成されました。これは、プリペアドステートメント
(そしてそれらは concat()を使用します 続いてEXECUTE 。
インデックスが使用され、テーブルスキャン(不良を意味する)は発生しません。詳細については、範囲結合タイプ
を参照してください。 、MySQLのCost-Based Optimizer(CBO)で見つけることができる参照、この回答
に注目して、日付は付けられていますがvladrからテーブルの分析
一部、特に重要なデータ変更後。 ANALYZEは、非常に巨大なデータセットで実行するのにかなりの時間がかかる可能性があることに注意してください。時には何時間も。
SQLインジェクション攻撃:
ストアドプロシージャに渡される文字列の使用は、SQLインジェクション攻撃の攻撃ベクトルです。ユーザーが提供するデータを使用する場合は、それらを防ぐための予防措置を講じる必要があります。あなたのルーチンがあなたのシステムによって生成されたあなた自身のIDに対して適用されるなら、あなたは安全です。ただし、第2レベルのSQLインジェクション攻撃は、以前の挿入または更新でそのデータをサニタイズしなかったルーチンによってデータが配置されたときに発生することに注意してください。攻撃はデータを介して事前に実施され、後で使用されます(一種の時限爆弾)。
したがって、この回答は終了です。 ほとんどの場合。
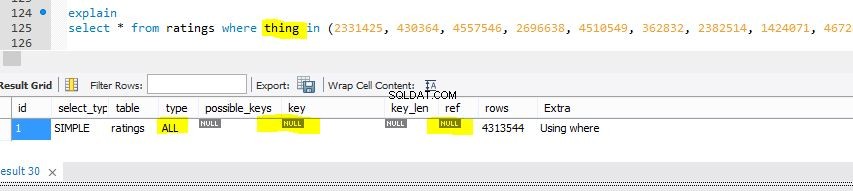
以下は、恐ろしいテーブルスキャンを示すために少し変更を加えた同じテーブルのビューです。 前のクエリのようになります(ただし、 thingsと呼ばれるインデックス付けされていない列に対して 。
現在のテーブル定義を見てください:
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
select min(id), max(id),count(*) as theCount from ratings;
+---------+---------+----------+
| min(id) | max(id) | theCount |
+---------+---------+----------+
| 1 | 5046213 | 4718592 |
+---------+---------+----------+
列thingに注意してください 以前はnull許容のint列でした。
update ratings set thing=id where id<1000000;
update ratings set thing=id where id>=1000000 and id<2000000;
update ratings set thing=id where id>=2000000 and id<3000000;
update ratings set thing=id where id>=3000000 and id<4000000;
update ratings set thing=id where id>=4000000 and id<5100000;
select count(*) from ratings where thing!=id;
-- 0 rows
ALTER TABLE ratings MODIFY COLUMN thing int not null;
-- current table definition (after above ALTER):
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
次に、TablescanであるExplain(列 things に対して) ):