私がよく目にするパフォーマンスの問題は、ユーザーが文字列の一部を次のようなクエリと照合する必要がある場合です。
... WHERE SomeColumn LIKE N'%SomePortion%';
先頭にワイルドカードがある場合、この述語は「非SARGable」です。これは、SomeColumnのインデックスに対してシークを使用しても、関連する行が見つからないことを示すための空想的な方法です。 。
私たちが手に負えない解決策の1つは、全文検索です。ただし、これは複雑なソリューションであり、検索パターンが完全な単語で構成されているか、ストップワードを使用していないかなどが必要です。これは、説明に「soft」(または「softer」や「softly」などの他の派生語)という単語が含まれている行を探している場合は役立ちますが、含まれている可能性のある文字列を探している場合は役に立ちません。単語内(または、「X45-B」を含むすべての製品SKUやシーケンス「7RA」を含むすべてのナンバープレートなど、まったく単語ではありません)。
SQL Serverが文字列のすべての可能な部分について何らかの形で知っていた場合はどうなりますか?私の思考プロセスはtrigramに沿っています /trigraph PostgreSQLで。基本的な概念は、エンジンが部分文字列に対してポイントスタイルのルックアップを実行する機能を備えていることです。つまり、テーブル全体をスキャンしてすべての完全な値を解析する必要はありません。
彼らが使用する具体的な例は、catという単語です。 。完全な単語に加えて、それは部分に分解することができます:c 、ca 、およびat (aは省略します およびt 定義上、末尾の部分文字列は2文字より短くすることはできません)。 SQL Serverでは、それほど複雑である必要はありません。 catのすべてのサブストリングを含むデータ構造を構築することを考えると、実際に必要なのはトリグラムの半分だけです。 、必要なのは次の値だけです:
- 猫
- at
- t
cは必要ありません またはca 、LIKE '%ca%'を検索している人は誰でも LIKE 'ca%'を使用すると、値1を簡単に見つけることができます。 代わりは。同様に、LIKE '%at%'を検索する人 またはLIKE '%a%' これらの3つの値に対してのみ末尾のワイルドカードを使用して、一致する値を見つけることができます(例:LIKE 'at%' 値2が見つかり、LIKE 'a%' また、値1内のサブストリングを見つける必要なしに、値2も見つけます。これは、本当の苦痛が生じる場所です。
したがって、SQL Serverにはこのようなものが組み込まれていないので、このようなトリグラムを生成するにはどうすればよいですか?
個別のフラグメントテーブル
ここでは「トリグラム」の参照を停止します。これは、PostgreSQLの機能と実際には類似していないためです。基本的に、これから行うことは、元の文字列のすべての「フラグメント」を使用して別のテーブルを作成することです。 (つまり、cat たとえば、これらの3つの行を含む新しいテーブルがあり、LIKE '%pattern%' 検索は、その新しいテーブルに対してLIKE 'pattern%'として送信されます。 述語。)
提案したソリューションがどのように機能するかを示す前に、このソリューションをLIKE '%wildcard%'のすべてのケースで使用する必要はないことを明確にしておきます。 検索は遅いです。ソースデータをフラグメントに「分解」する方法のため、実際には、製品の説明やセッションの要約などの大きな文字列ではなく、アドレスや名前などの小さな文字列に制限される可能性があります。>
catよりも実用的な例 Sales.Customerを確認することです WideWorldImportersサンプルデータベースのテーブル。アドレス行があります(両方ともnvarchar(60) )、DeliveryAddressLine2列に貴重な住所情報が表示されます (理由は不明)。 Hudecovaという名前の通りに住んでいる人を探している人がいるかもしれません。 、したがって、次のような検索を実行します:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ ご想像のとおり、SQL Serverは、これら2つの行を見つけるためにスキャンを実行する必要があります。これは単純なはずです。ただし、テーブルが複雑なため、この簡単なクエリでは非常に厄介な実行プランが生成されます(スキャンが強調表示され、残りのI / Oに対する警告が表示されます):
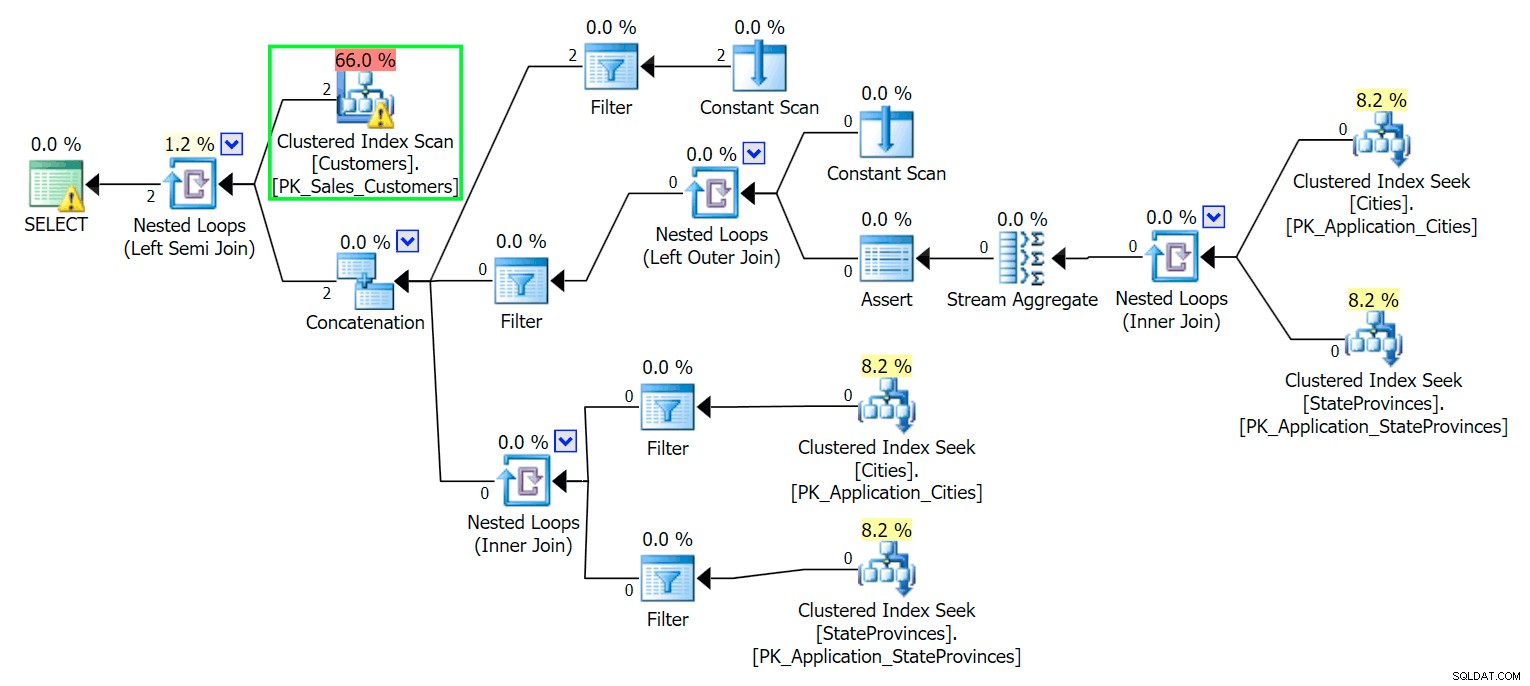
Blecch。私たちの生活をシンプルに保ち、たくさんの赤いニシンを追いかけないようにするために、列のサブセットを使用して新しいテーブルを作成し、最初に同じ2つの行を上から挿入します。
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
ここで、メインテーブルに対して実行したのと同じクエリを実行すると、開始点として見るのがはるかに合理的なものになります。 DeliveryAddressLine2を使用してインデックスを追加した場合、これは何をしてもスキャンになります。 主要なキー列として、インデックスがクエリの列をカバーしているかどうかに応じてキールックアップを使用して、インデックススキャンを取得する可能性があります。そのまま、クラスター化されたインデックススキャンを取得します:
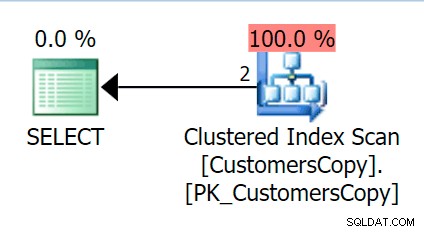
次に、これらのアドレス値をフラグメントに「分解」する関数を作成しましょう。 1846 Hudecova Crescentを期待します たとえば、次のフラグメントのセットを作成します。
- 1846 Hudecova Crescent
- 846フデコバクレセント
- 46フデコバクレセント
- 6 Hudecova Crescent
- Hudecova Crescent
- Hudecova Crescent
- udecova Crescent
- デコバクレセント
- ecova Crescent
- cova Crescent
- ova Crescent
- va Crescent
- 三日月
- クレセント
- クレセント
- rescent
- escent
- 香り
- セント
- ent
- nt
- t
この出力を生成する関数を作成するのは非常に簡単です。入力の長さ全体にわたって各文字をステップスルーするために使用できる再帰CTEが必要です。
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list 次に、すべてのアドレスフラグメントと、それらが属する顧客を格納するテーブルを作成しましょう。
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
次に、次のようにデータを入力できます:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
2つの値の場合、これにより42行が挿入されます(1つのアドレスは20文字で、もう1つのアドレスは22文字です)。これで、クエリは次のようになります。
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; これははるかに優れた計画です。2つのクラスター化されたインデックス*シーク*とネストされたループが結合します:
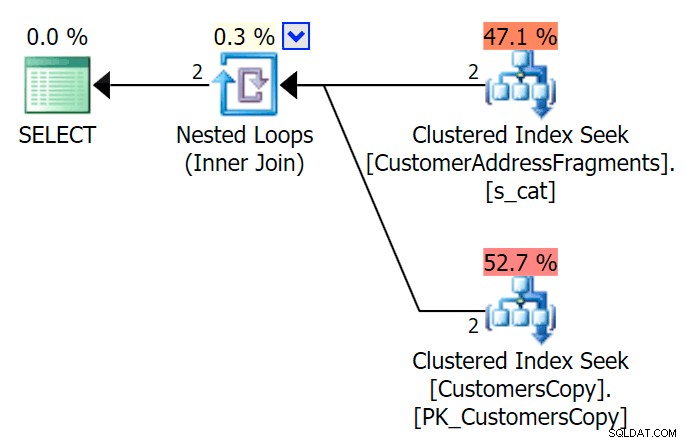
EXISTSを使用して、これを別の方法で行うこともできます :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); これがその計画です。表面的にはより高価であるように見えます–CustomersCopyテーブルをスキャンすることを選択します。これがより優れたクエリアプローチである理由はすぐにわかります:
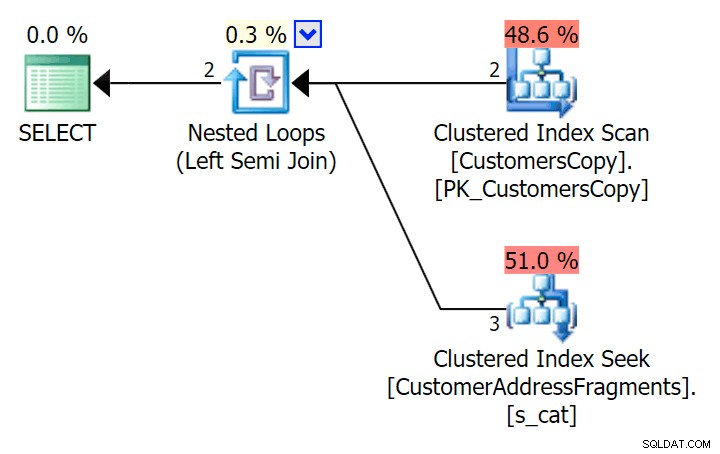
さて、この42行の大規模なデータセットでは、期間とI / Oに見られる違いはごくわずかであり、無関係です(実際、この小さなサイズでは、ベーステーブルに対するスキャンはI/の点で安価に見えます。 Oフラグメントテーブルを使用する他の2つのプランよりも):

これらのテーブルにさらに多くのデータを入力するとどうなりますか? Sales.Customersの私のコピー 663行あるので、それ自体に対してクロス結合すると、440,000行近くになります。それでは、400Kをマッシュアップして、はるかに大きなテーブルを生成しましょう。
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
ここで、さまざまな可能な検索パラメーターを指定してパフォーマンスと実行計画を比較するために、上記の3つのクエリをこれらの述語でテストしました。
| クエリ | 述語 | ||||
|---|---|---|---|---|---|
| WHEREDeliveryLineAddress2LIKE… | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN…WHEREFragmentLIKE… | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| WHERE EXISTS(…WHERE Fragment LIKE…) | |||||
検索パターンから文字を削除すると、より多くの行が出力され、オプティマイザーによって選択されたさまざまな戦略が表示されると思います。各パターンでどのように進んだか見てみましょう:
Hudecova%
このパターンの場合、スキャンはLIKE条件でも同じでした。ただし、データが多いほど、コストははるかに高くなります。フラグメントテーブルへのシークは、推定値が非常に低くても、この行数(1,206)で実際に成果を上げます。 EXISTSプランは、コストに追加されると予想される明確な並べ替えを追加しますが、この場合、読み取りの回数は少なくなります。


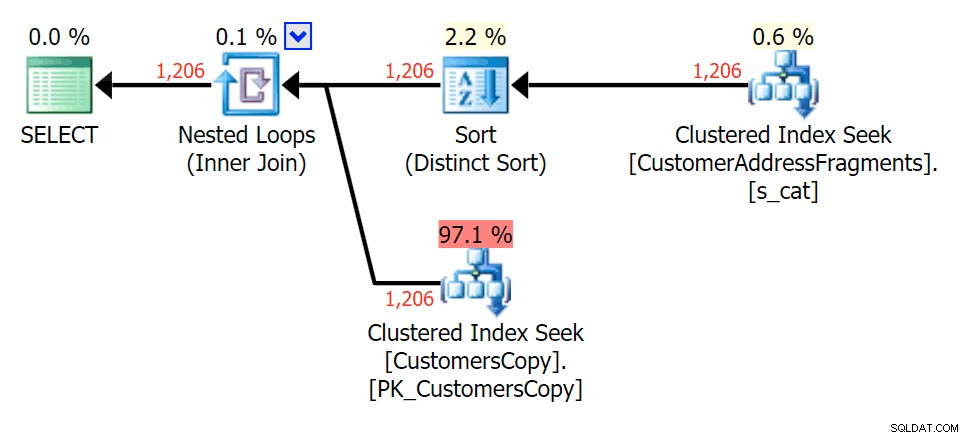
cova%
述語からいくつかの文字を取り除くと、実際には元のクラスター化インデックススキャンよりも読み取りが少し高くなり、以上になります。 -行を推定します。それでも、両方のフラグメントクエリを使用すると、期間は大幅に短くなります。今回の違いはもっと微妙です–どちらにも種類があります(EXISTSのみが区別されます):

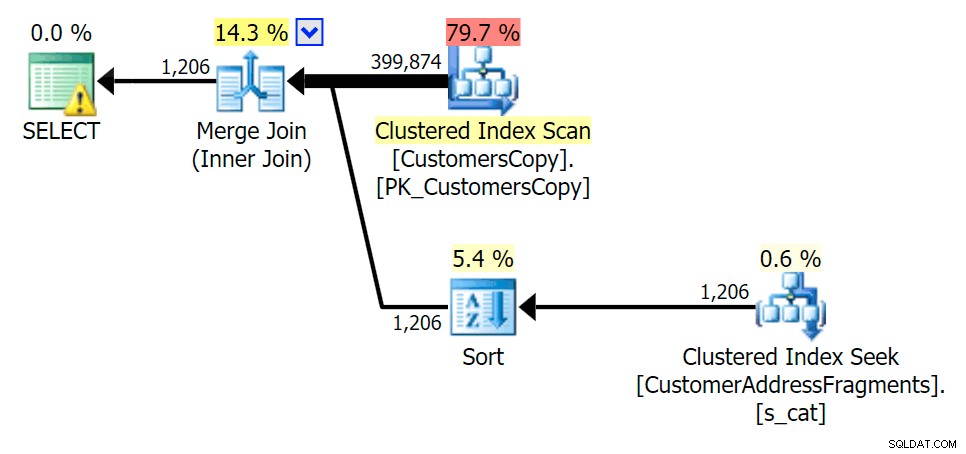
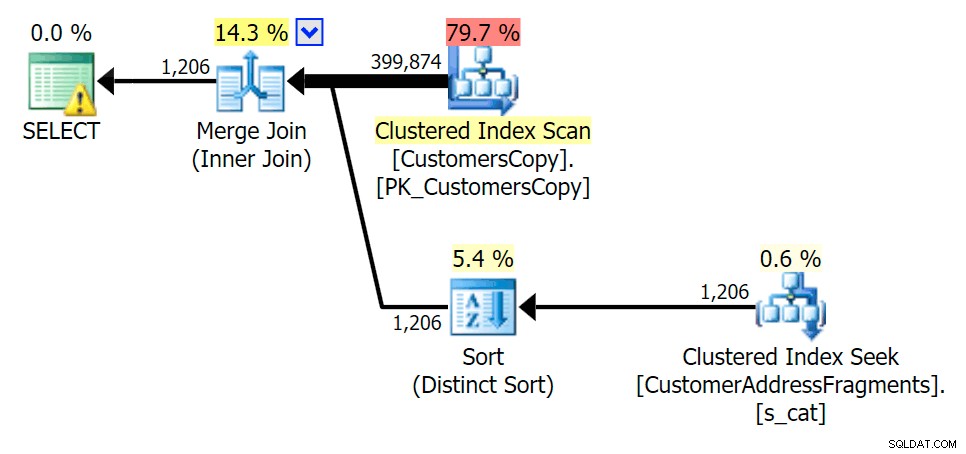
ova%
追加の文字を削除してもあまり変わりませんでした。ただし、ここで推定行と実際の行がどれだけジャンプするかは注目に値します。つまり、これは一般的なサブストリングパターンである可能性があります。元のLIKEクエリは、フラグメントクエリよりもかなり低速です。

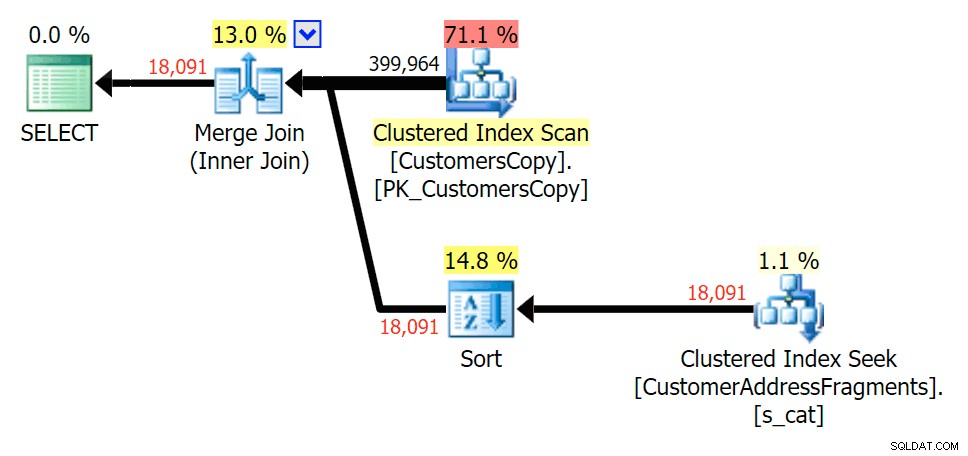
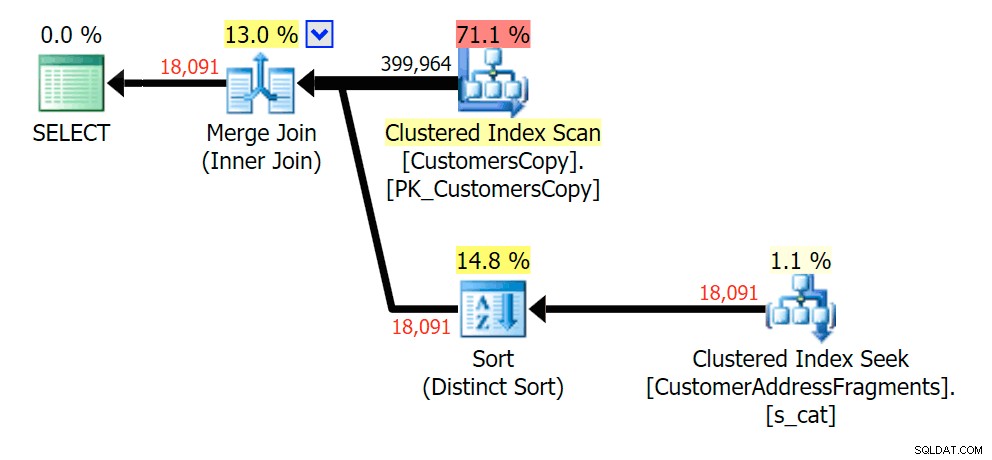
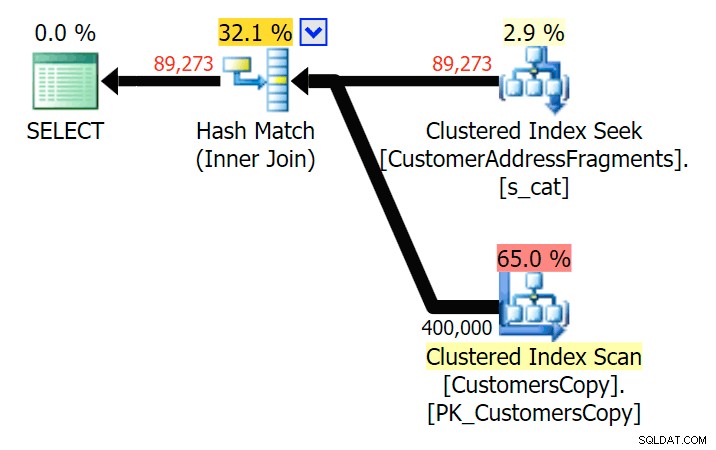
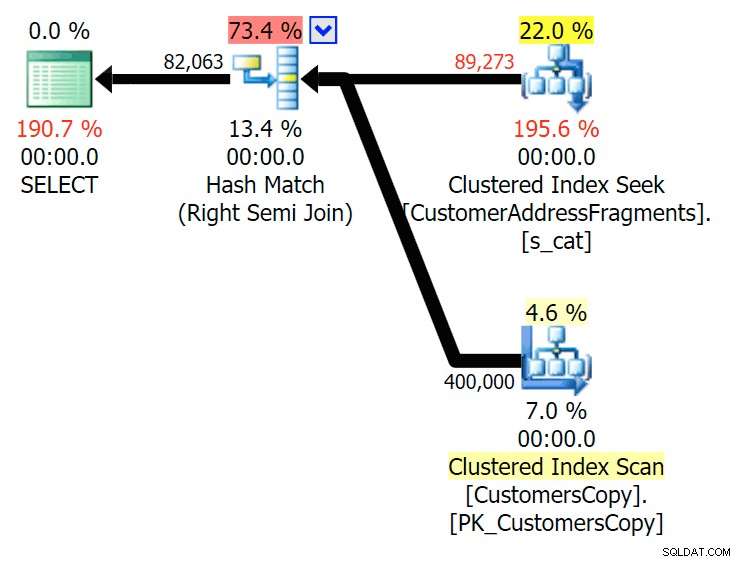
va%
2文字まで、これは私たちの最初の不一致をもたらします。 JOINがもっとを生成することに注意してください 元のクエリまたはEXISTSよりも行。なぜそうなるのでしょうか?

899 Valentova Roadのようなものを意味します。 フラグメントテーブルには、vaで始まる2つの行があります。 (大文字と小文字の区別は別として)。したがって、両方のFragment = N'Valentova Road'で一致します。 およびFragment = N'va Road' 。検索を保存し、多くの例を1つ紹介します。 SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
これは、JOINがより多くの行を生成する理由を簡単に説明します。元のLIKEクエリの出力と一致させる場合は、EXISTSを使用する必要があります。通常、リソースをあまり消費しない方法で正しい結果を取得できるという事実は、単なるボーナスです。 (それが繰り返しより効率的なオプションである場合、人々がJOINを選択するのを見るのは緊張します。パフォーマンスを心配するよりも、常に正しい結果を優先する必要があります。)
概要
この特定のケースでは、アドレス列がnvarchar(60)であることは明らかです。 最大長は26文字です。各アドレスをフラグメントに分割すると、コストのかかる「主要なワイルドカード」検索をある程度緩和できます。検索パターンが大きくなり、その結果、よりユニークになると、より良い見返りが得られるようです。また、複数の一致が可能なシナリオでEXISTSが優れている理由も示しました。JOINを使用すると、「グループあたり最大のn」ロジックを追加しない限り、冗長な出力が得られます。
警告
私は、このソリューションが不完全で、不完全であり、完全に具体化されていないことを最初に認めます:
- トリガーを使用してフラグメントテーブルをベーステーブルと同期させる必要があります。最も簡単なのは、挿入と更新、それらの顧客のすべての行の削除と再挿入、削除の場合は明らかにフラグメントからの行の削除です。テーブル。
- 前述のように、このソリューションはこの特定のデータサイズではうまく機能し、他の文字列の長さではうまく機能しない可能性があります。列サイズ、平均値の長さ、および一般的な検索パラメーターの長さに適していることを確認するために、さらにテストする必要があります。
- 「Crescent」や「Street」などのフラグメントのコピーが多数あるため(同じまたは類似のストリート名や家番号は気にしないでください)、各一意のフラグメントをフラグメントテーブルに格納することで、さらに正規化できます。次に、多対多のジャンクションテーブルとして機能するさらに別のテーブル。それは設定するのがはるかに面倒であり、得るものがたくさんあるかどうかはよくわかりません。
- 私はまだページ圧縮について完全に調査していませんでしたが、少なくとも理論的には、これはいくつかの利点を提供する可能性があるようです。また、場合によっては、列ストアの実装が有益であると感じています。
とにかく、それでも、私はそれを開発中のアイデアとして共有し、特定のユースケースでの実用性についてフィードバックを求めたいと思いました。このソリューションのどの側面に関心があるかを教えていただければ、今後の投稿のために詳細を掘り下げることができます。