ロードバランサーは、データベースの高可用性に不可欠なコンポーネントです。特に、トポロジの変更をアプリケーションに対して透過的にし、読み取り/書き込み分割機能を実装する場合。 ClusterControlは、業界をリードするオープンソースの負荷分散テクノロジーを安全に展開、監視、構成するための一連の機能を提供します。
昨年、ProxySQLのサポートを追加し、HAProxyとMariaDBのMaxscaleに複数の拡張機能を追加しました。 ClusterControl 1.5の最新リリースでも、この伝統を引き継いでいます。
ユーザーから受け取ったフィードバックに基づいて、ProxySQLの管理方法を改善しました。また、PostgreSQLクラスター上で実行するHAProxyとKeepalivedのサポートも追加しました。
このブログ投稿では、これらの改善点を見ていきます...
ProxySQL-ユーザー管理の機能強化
以前は、UIでは、一度に1つずつ、新しいユーザーを作成するか、既存のユーザーを追加することしかできませんでした。ユーザーから寄せられたフィードバックの1つは、多数のユーザーを管理するのは非常に難しいというものでした。聞いてみたところ、ClusterControl 1.5では、大量のユーザーをインポートできるようになりました。それを行う方法を見てみましょう。まず、ProxySQLをデプロイする必要があります。次に、ProxySQLノードに移動し、[ユーザー]タブに[ユーザーのインポート]ボタンが表示されます。

それをクリックすると、新しいダイアログボックスが開きます:

ここでは、ClusterControlがクラスターで検出したすべてのユーザーを確認できます。それらをスクロールして、インポートするものを選択できます。現在のビューからすべてのユーザーを選択または選択解除することもできます。

検索ボックスに入力を開始すると、ClusterControlは一致しない結果を除外し、検索に関連するユーザーのみにリストを絞り込みます。
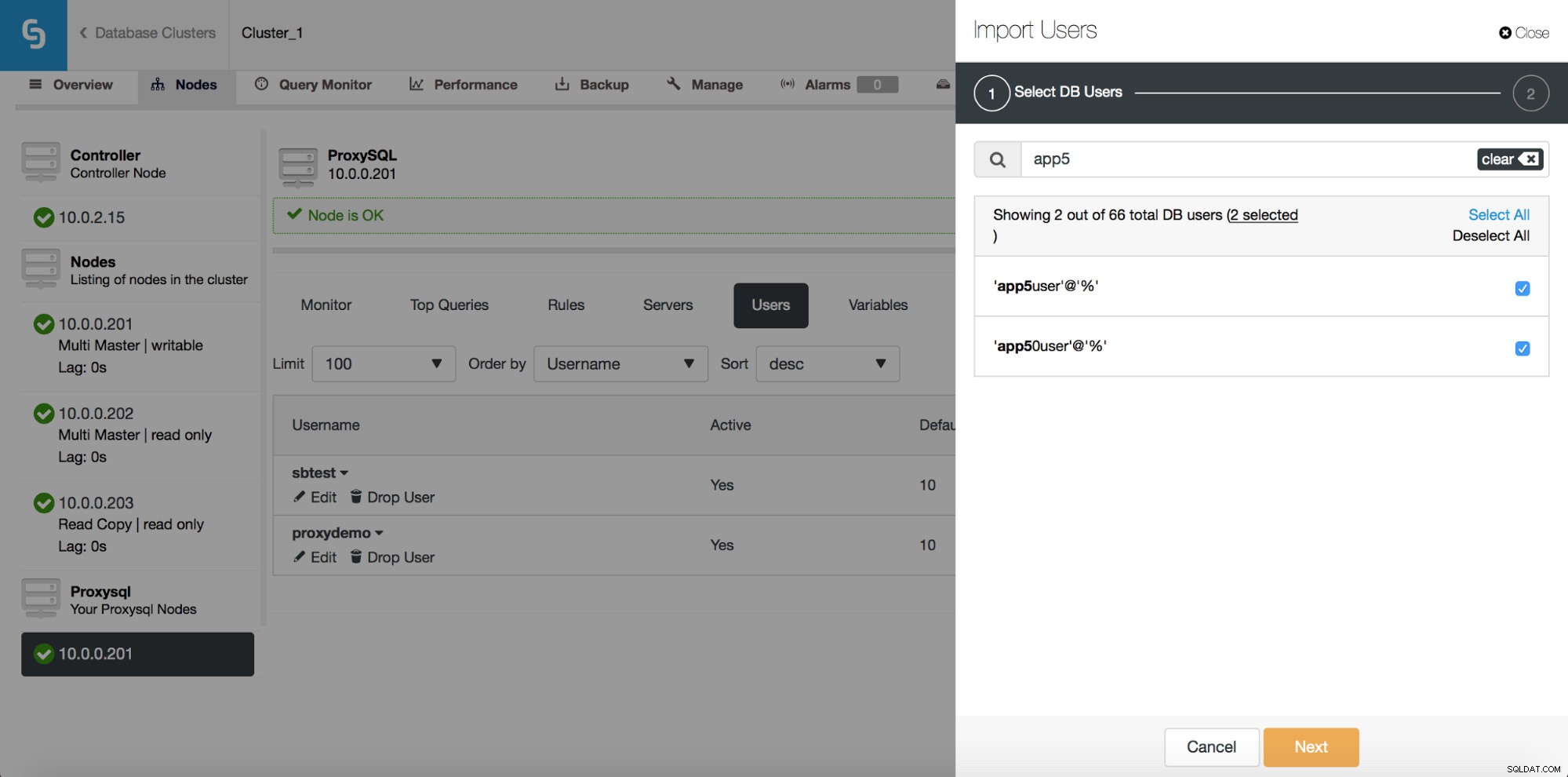
「すべて選択」ボタンを使用して、検索に一致するすべてのユーザーを選択できます。もちろん、インポートするユーザーを選択したら、検索ボックスをクリアして別の検索を開始できます:

「(7つ選択)」に注意してください。これは、(この検索だけでなく)合計でインポートするように選択したユーザーの数を示します。それをクリックして、インポートするために選択したユーザーのみを表示することもできます。

選択に満足したら、[次へ]をクリックして次の画面に進むことができます。

ここで、各ユーザーのデフォルトのホストグループを決定する必要があります。これは、ユーザーごとに、またはグローバルに、検索の結果として得られたユーザーのセット全体またはサブセットに対して行うことができます。

[ユーザーのインポート]ボタンをクリックすると、ユーザーがインポートされ、[ユーザー]タブに表示されます。
ProxySQL-スケジューラ管理
ProxySQLのスケジューラはcronに似たモジュールであり、ProxySQLが定期的に外部スクリプトを開始できるようにします。スケジュールは非常に細かく設定できます。ミリ秒ごとに最大1回実行されます。通常、スケジューラーはGaleraチェッカースクリプト(proxysql_galera_checker.shなど)を実行するために使用されますが、他の任意のスクリプトを実行するためにも使用できます。以前は、ClusterControlはスケジューラーを使用してGaleraチェッカースクリプトをデプロイしていましたが、これはUIに表示されませんでした。 ClusterControl 1.5以降、完全に制御できるようになりました。

ご覧のとおり、1つのスクリプトが2秒(2000ミリ秒)ごとに実行されるようにスケジュールされています。これは、Galeraクラスターのデフォルト構成です。

上のスクリーンショットは、既存のエントリを編集するためのオプションを示しています。 ProxySQLは、スケジューラを介して実行するスクリプトに対して最大5つの引数をサポートすることに注意してください。

新しいスクリプトをスケジューラーに追加したい場合は、「新しいスクリプトの追加」ボタンをクリックすると、上記のような画面が表示されます。実行時にスクリプト全体がどのように表示されるかをプレビューすることもできます。すべての「引数」フィールドに入力して間隔を定義したら、「新しいスクリプトの追加」ボタンをクリックできます。

その結果、スクリプトがスケジューラーに追加され、スケジュールされたスクリプトのリストに表示されます。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするPostgreSQL-高可用性スタックの構築
自動フェイルオーバーを使用してレプリケーションを設定することは適切ですが、アプリケーションには、書き込み可能なマスターを追跡するための簡単な方法が必要です。そのため、PostgreSQLクラスターに加えてHAProxyとKeepalivedのサポートを追加しました。これにより、PostgreSQLユーザーはClusterControlを使用して完全な高可用性スタックをデプロイできます。

[ロードバランサー]サブタブから、HAProxyをデプロイできるようになりました。ClusterControlがMySQLレプリケーションをデプロイする方法に精通している場合は、非常によく似たセットアップです。特定のホスト、2つのバックエンドにHAProxyをインストールし、ポート3308で読み取り、ポート3307で書き込みます。tcp-checkを使用して、特定の文字列が返されることを期待します。その文字列を生成するために、次の手順がすべてのデータベースノードで実行されます。まず、xinet.dは、ポート9201でサービスを実行するように構成されています(ポート9200を使用するMySQLセットアップとの混同を避けるため)。
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDこのサービスは/usr/ local / sbin / postgreschkスクリプトを実行します。このスクリプトは、PostgreSQLの状態を検証し、特定のホストが使用可能かどうか、およびそのホストのタイプ(マスターまたはスレーブ)を通知します。すべて問題がなければ、HAProxyが期待する文字列を返します。
MySQLの場合と同様に、PostgreSQLクラスターのHAProxyノードがUIに表示され、ステータスページにアクセスできます。

ここでは、両方のバックエンドを確認し、マスターのみがr / wバックエンドに対応しており、すべてのノードに読み取り専用バックエンドを介してアクセスできることを確認できます。トラフィックと接続に関する統計も取得できます。
HAProxyは高可用性の向上に役立ちますが、単一障害点になる可能性があります。キープアライブを利用して、さらに一歩進んで冗長性を構成する必要があります。

[管理]->[ロードバランサー]->[キープアライブ]で、使用するHAProxyホストを選択すると、キープアライブが、選択したインターフェイスに接続された仮想IPを使用してそれらの上にデプロイされます。
今後、すべての接続は、HAProxyノードの1つに接続されるVIPに接続する必要があります。そのノードがダウンした場合、KeepalivedはそのノードでVIPをダウンさせ、別のHAProxyノードで起動します。
ClusterControl1.5で導入された負荷分散機能については以上です。それらを試してみて、どのように私たちに知らせてください