あなたの質問は本当に 不正確。 @RiggsFollyの提案に従い、良い質問をする方法についてのリファレンスを読んでください。
また、@ DuduMarkovitzが提案しているように、問題を単純化してデータをクリーンアップすることから始める必要があります。始めるためのいくつかのリソース:
- 基本的なテキスト処理チュートリアル MattDeny著
- Rでの文字列の処理と処理 ガストン・サンチェス著
結果に満足したら、各 Var1のグループの識別に進むことができます。 エントリ(これは、同様のエントリでさらに分析/操作を実行するのに役立ちます)これはさまざまな方法で実行できますが、@ GordonLinoffが述べているように、1つの可能性はレーベンシュタイン距離です。
注 :50Kエントリの場合、結果は100%正確ではありません。常に 用語を適切なグループに分類しますが、これにより手作業が大幅に削減されます。
Rでは、<を使用してこれを行うことができます。 code> adist()
サンプルデータの使用:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
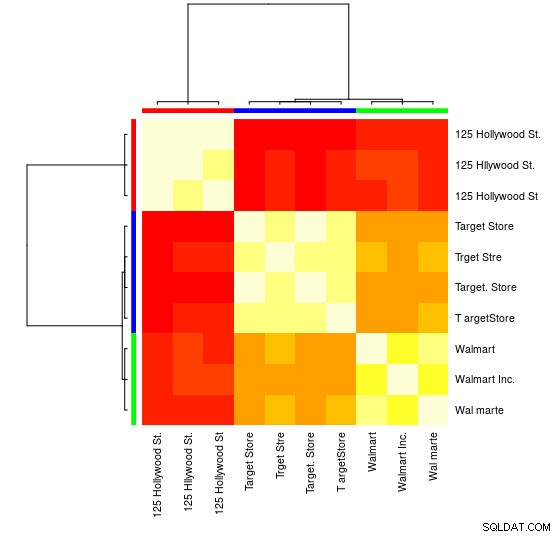
この小さなサンプルでは、3つの異なるグループ(低いレーベンシュタイン距離値のクラスター)を確認でき、それらを手動で簡単に割り当てることができますが、より大きなセットの場合は、クラスタリングアルゴリズムが必要になる可能性があります。
コメントで、私の前の回答
hclust()を使用してこれを行う方法を示します ウォード法の最小分散法ですが、ここでは他の手法を使用したほうがよいと思います(Rで最も広く使用されている方法の概要については、このトピックに関する私のお気に入りのリソースの1つは、この詳細な回答
)
アフィニティ伝播クラスタリングを使用した例を次に示します。
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
APResultオブジェクトd_apにあります 各クラスターに関連付けられている要素とクラスターの最適数(この場合は3)。
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
視覚的な表現も見ることができます:
> heatmap(d_ap, margins = c(10, 10))
次に、グループごとにさらに操作を実行できます。例として、ここでは hunspellを使用します Var1から個別の単語を検索します スペルミスのen_US辞書で、各グループ内で検索してみてください 、 id スペルミスはありません( Potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
与えるもの:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
注 :ここでは、テキスト処理を実行していないため、結果はあまり決定的ではありませんが、アイデアは得られます。
データ
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)