Prestoは、ビッグデータ処理用のオープンソースの並列分散SQLエンジンです。 Facebookによってゼロから開発されました。最初の内部リリースは2013年に行われ、ビッグデータの問題に対する非常に革新的なソリューションでした。
地理的に配置された数百のサーバーとペタバイトのデータを使用して、FacebookはHadoopクラスターの代替プラットフォームを探し始めました。彼らのインフラストラクチャチームは、組織で広く知られているプログラミング言語であるSQLを使用して、分析バッチジョブの実行に必要な時間を短縮し、パイプライン開発を簡素化したいと考えていました。
Presto Foundationによると、「Facebookは、300PBデータウェアハウスを含むいくつかの内部データストアに対するインタラクティブなクエリにPrestoを使用しています。 1,000人を超えるFacebookの従業員が毎日Prestoを使用して、1日あたりペタバイトを超える合計スキャンを行う30,000を超えるクエリを実行しています。」
Facebookには例外的なデータウェアハウス環境がありますが、ビッグデータを扱う多くの組織にも同じ課題があります。
このブログでは、tarファイルからDockerサーバーを使用して基本的なpresto環境をセットアップする方法を見ていきます。データソースとして、MySQLデータソースに焦点を当てますが、他の一般的なRDBMSでもかまいません。
ビッグデータ環境でのPrestoの実行
始める前に、その主要なアーキテクチャの原則を簡単に見てみましょう。 Prestoは、HiveなどのMapReduceジョブのパイプラインを使用してHDFSをクエリするツールの代替手段です。 Hive Prestoとは異なり、MapReduceは使用しません。 Prestoは、高レベルの演算子とインメモリ処理を備えた専用のクエリ実行エンジンで実行されます。
Hive Prestoとは対照的に、データチャンクを同時に実行すると、すべてのステージでデータをストリーミングできます。これは、単一または分散した異種データソースに対してアドホック分析クエリを実行するように設計されています。 Hadoopプラットフォームから連絡を取り、リレーショナルデータベースやフラットファイルなどの他のデータストアにクエリを実行できます。
Prestoは、集計、結合、または分析ウィンドウ関数を含む標準のANSISQLを使用します。 SQLはよく知られており、Javaで記述されたMapReduceと比較してはるかに使いやすいです。
PrestoをDockerにデプロイする
基本的なPresto構成は、事前構成されたDockerイメージまたはprestoサーバーtarballを使用してデプロイできます。
DockerサーバーとPrestoCLIコンテナーは、次の方法で簡単にデプロイできます。
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cli2つのPrestoサーバーバージョンから選択できます。 Starburstのコミュニティバージョンとエンタープライズバージョン。非本番サンドボックス環境で実行するため、この記事ではApacheバージョンを使用します。
前提条件
Prestoは完全にJavaで実装されており、システムにJVMをインストールする必要があります。 OpenJDKとOracleJavaの両方で動作します。最小バージョンはJava8u151またはJava11です。
JAVA JDKをダウンロードするには、https://openjdk.java.net/またはhttps://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
にアクセスしてください。Javaのバージョンは
で確認できます$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)プレストインストール
Prestoをインストールするには、サーバーtarとPrestoCLIjar実行可能ファイルをダウンロードします。
tarballには、インストールディレクトリと呼ばれる単一のトップレベルディレクトリpresto-server-0.223が含まれます。
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoさらに、Prestoにはログなどを保存するためのデータディレクトリが必要です。
インストールディレクトリの外にデータディレクトリを作成することをお勧めします。
$ mkdir -p ~/data/presto/この場所は、トラブルシューティングを開始するときの場所です。
Prestoの構成
最初のインスタンスを開始する前に、一連の構成ファイルを作成する必要があります。インストールディレクトリ内にetc/ディレクトリを作成することから始めます。この場所には、次の構成ファイルが保持されます。
など/
- ノードのプロパティ-ノードの環境構成
- JVM構成(jvm.config)-Java仮想マシン構成
- Config Properties(config.properties)-Prestoサーバーの構成
- カタログプロパティ-コネクタ(データソース)の構成
- ログのプロパティ-ロガーの構成
以下に、Prestoサンドボックスを実行するための基本的な構成をいくつか示します。詳細については、ドキュメントをご覧ください。
vi etc / config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc / node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/presto基本的なetc/構造は次のようになります。

次のステップは、MySQLコネクタを設定することです。
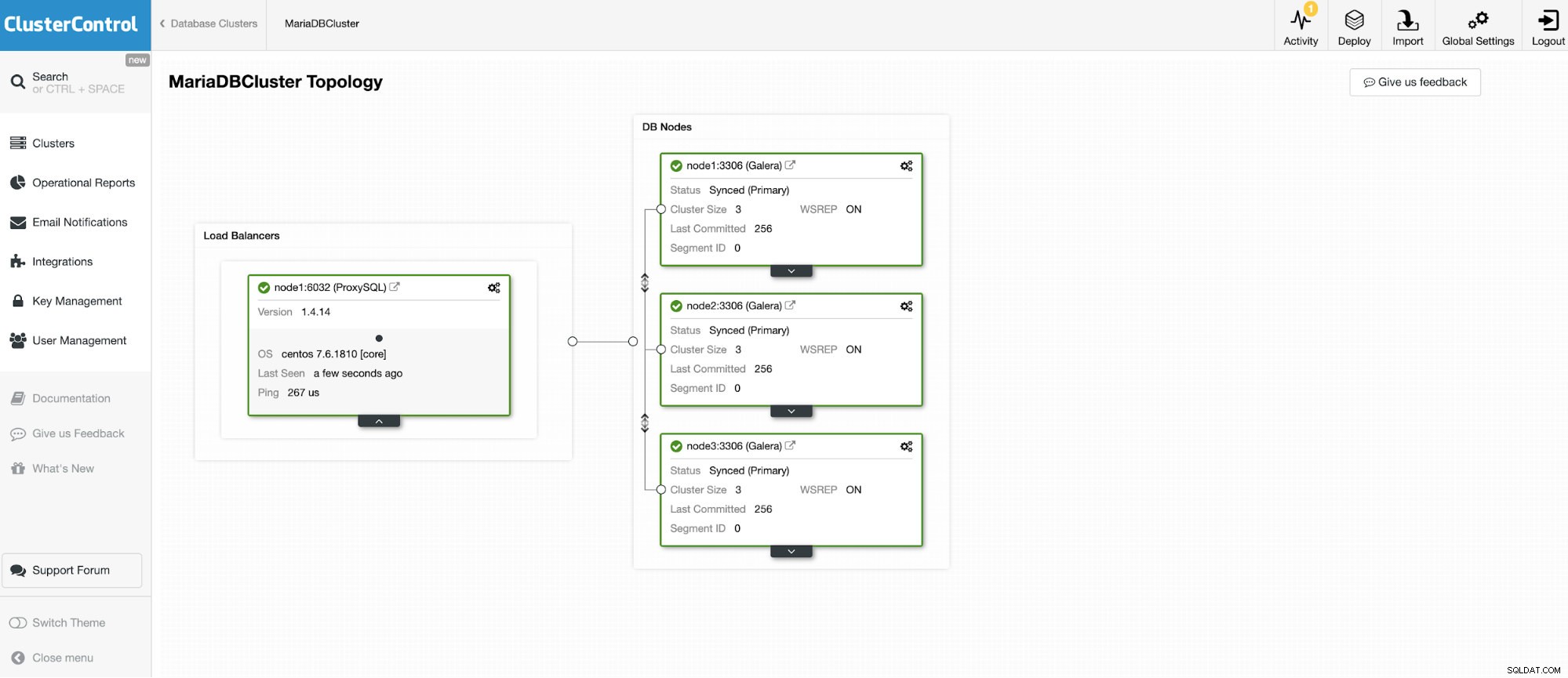
3つのノードMariaDBクラスタの1つに接続します。
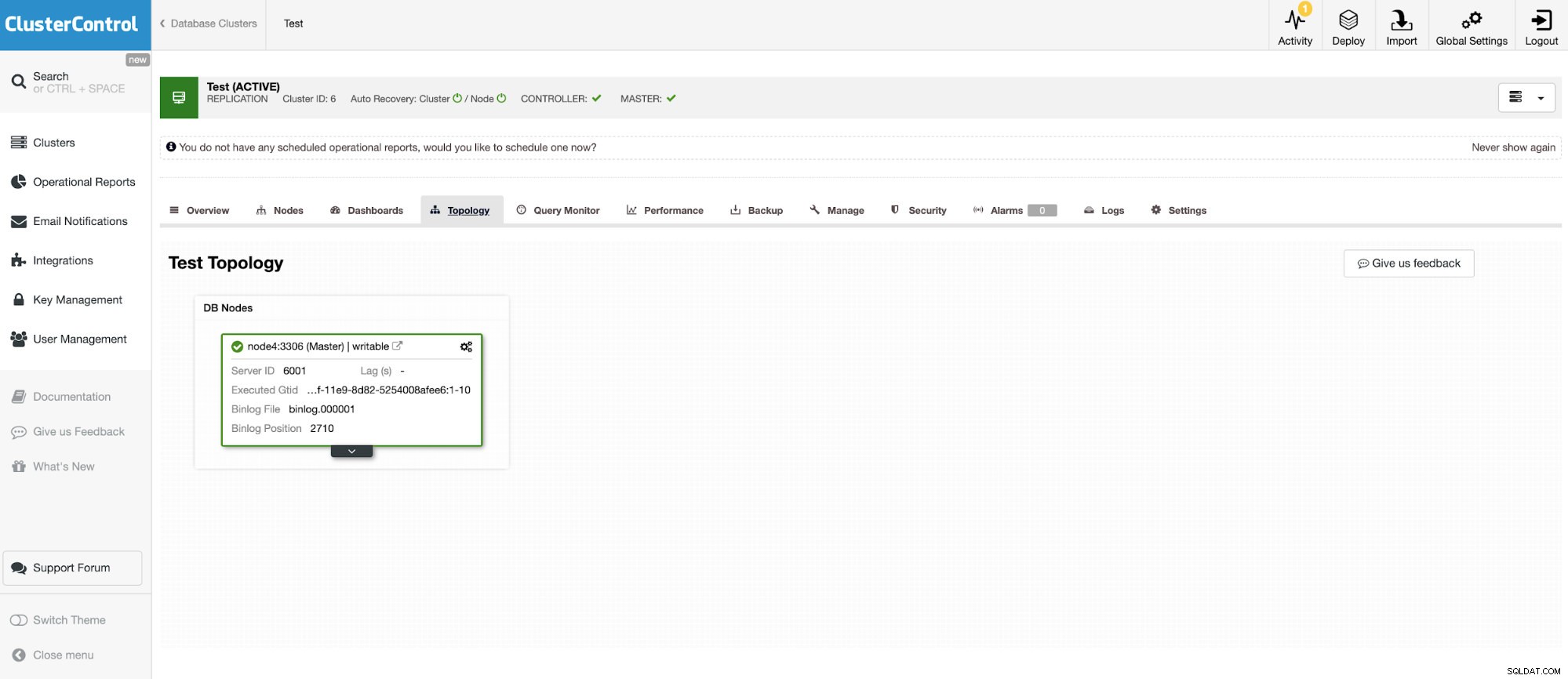
そして、OracleMySQL5.7を実行している別のスタンドアロンインスタンス。
MySQLコネクタを使用すると、外部MySQLデータベースでテーブルをクエリおよび作成できます。これは、MariaDBやOracleのMySQLなどの異なるシステム間でデータを結合するために使用できます。
Prestoはプラグ可能なコネクタを使用しており、設定は非常に簡単です。 MySQLコネクタを設定するには、etc / catalogにmysql.propertiesなどの名前のカタログプロパティファイルを作成して、MySQLコネクタをmysqlカタログとしてマウントします。他のサーバーへの接続を表す各ファイル。この場合、2つのファイルがあります:
vi etc / catalog / mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc / catalog / mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretPrestoの実行
すべてが設定されたら、Prestoインスタンスを開始します。 prestoを開始するには、presoインストールの下のbinディレクトリに移動し、次のコマンドを実行します。
$ bin/launcher start
Started as 18363Prestoの実行を停止するには
$ bin/launcher stopこれで、サーバーが稼働しているときに、CLIを使用してPrestoに接続し、MySQLデータベースにクエリを実行できます。
Prestoコンソールの実行を開始するには:
./presto --server localhost:8080 --catalog mysql --schema employeesこれで、CLIを介してデータベースにクエリを実行できます。
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
MariaDBクラスターとMySQLの両方のデータベースに従業員データベースが提供されています。
wgethttps://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlクエリのステータスは、Presto Webコンソールにも表示されます: http:// localhost:8080 / ui /#
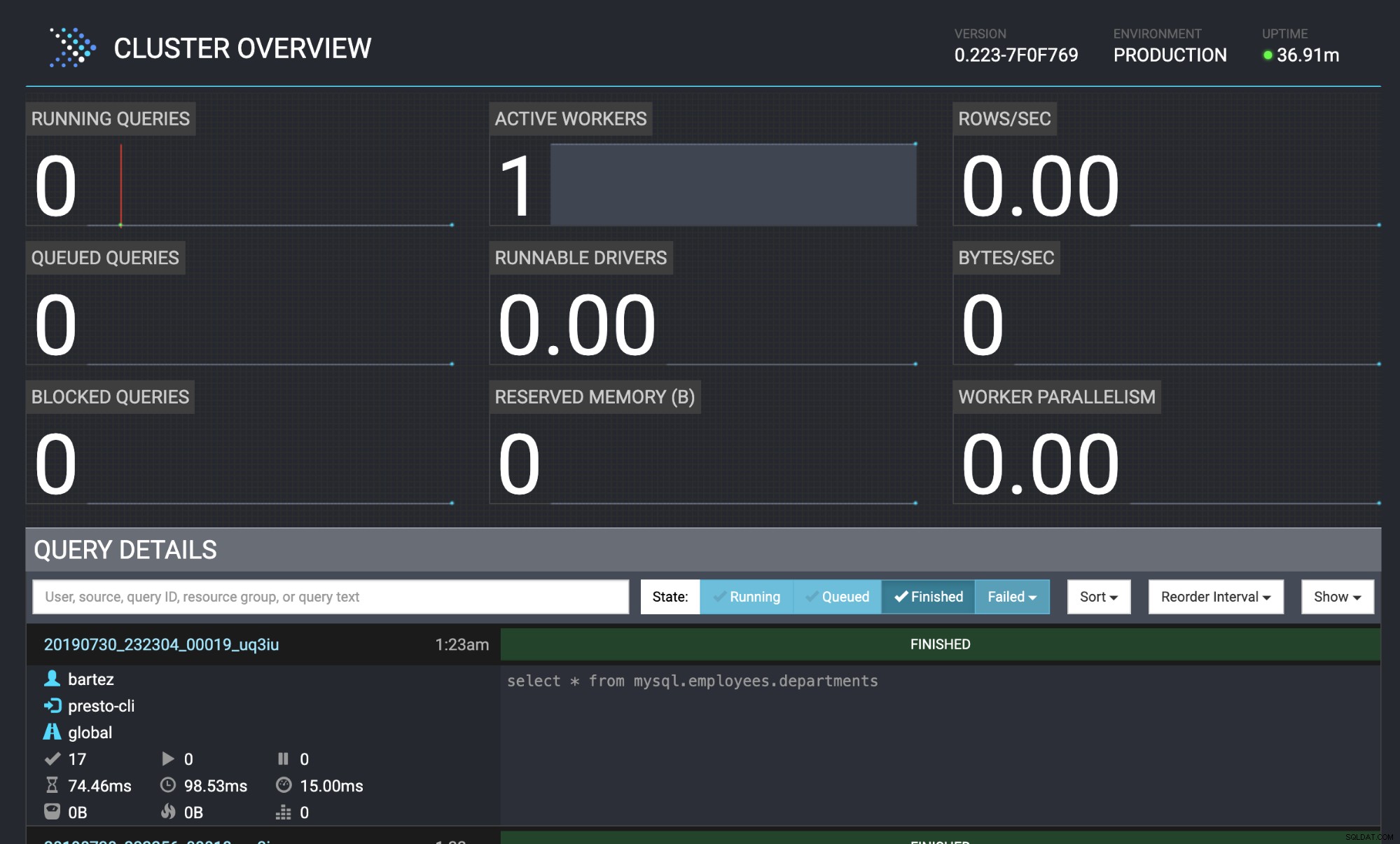 Prestoクラスターの概要
Prestoクラスターの概要 結論
多くの有名な企業(Airbnb、Netflix、Twitterなど)は、低遅延パフォーマンスのためにPrestoを採用しています。これは間違いなく非常に興味深いソフトウェアであり、大量のETLデータウェアハウスプロセスを実行する必要がなくなる可能性があります。このブログでは、MySQLコネクタについて簡単に説明しましたが、これを使用して、HDFS、オブジェクトストア、RDBMS(SQL Server、Oracle、PostgreSQL)、Kafka、Cassandra、MongoDBなどのデータを分析できます。
>