この記事では、リアルタイムの運用分析と、このアプローチをOLTPデータベースに適用する方法に焦点を当てます。従来の分析モデルを見ると、OLTPと分析環境が別々の構造であることがわかります。まず、従来の分析モデル環境では、ETL(抽出、変換、および読み込み)タスクを作成する必要があります。トランザクションデータをデータウェアハウスに転送する必要があるためです。これらのタイプのアーキテクチャには、いくつかの欠点があります。それらは、コスト、複雑さ、およびデータ遅延です。これらの欠点を取り除くには、別のアプローチが必要です。
リアルタイム運用分析
Microsoftは、SQLServer2016でReal-TimeOperationalAnalyticsを発表しました。この機能の機能は、パフォーマンスの問題なしにトランザクションデータベースと分析クエリのワークロードを組み合わせることです。リアルタイム運用分析は以下を提供します:
- ハイブリッド構造
- トランザクションクエリと分析クエリを同時に実行できます
- パフォーマンスと遅延の問題は発生しません。
- 簡単な実装。
この機能は、従来の分析環境の欠点を克服できます。この機能の主なテーマは、列ストアインデックスが、トランザクションシステムのパフォーマンスに影響を与えることなくデータのコピーを維持することです。このテーマにより、パフォーマンスに影響を与えることなく分析クエリを実行できます。したがって、これによりパフォーマンスへの影響が最小限に抑えられます。この機能の主な制限は、さまざまなデータソースからデータを収集できないことです。
非クラスター化列ストアインデックス
SQL Server 2016では、更新可能な「非クラスター化列ストアインデックス」が導入されています。非クラスター化列ストアインデックスは、分析クエリのパフォーマンスを向上させる列ベースのインデックスです。この機能により、リアルタイムの運用分析フレームワークを作成できます。つまり、トランザクションと分析クエリを同時に実行できます。毎月の総売上高が必要だと考えてください。従来のモデルでは、ETLタスク、データマート、およびデータウェアハウスを開発する必要があります。しかし、リアルタイムの運用分析では、データウェアハウスやOLTP構造の変更を必要とせずにそれを行うことができます。適切な非クラスター化列ストアインデックスを作成するだけで済みます。
非クラスター化列ストアインデックスのアーキテクチャ
非クラスター化列ストアインデックスのアーキテクチャと実行メカニズムについて簡単に見てみましょう。非クラスター化列ストアインデックスには、基になるテーブルの行と列の一部またはすべてのコピーが含まれます。非クラスター化列ストアインデックスの主なテーマは、データのコピーを維持し、このデータのコピーを使用することです。したがって、このメカニズムは、トランザクションデータベースのパフォーマンスへの影響を最小限に抑えます。非クラスター化列ストアインデックスは、1つまたは複数の列を作成し、列にフィルターを適用できます。
非クラスター化列ストアインデックスを持つテーブルに新しい行を挿入すると、最初にSQLServerが「行グループ」を作成します。行グループは、行のセットを表す論理構造です。次に、SQLServerはこれらの行を一時ストレージに格納します。この一時ストレージの名前は「deltastore」です。このメカニズムにより圧縮率が向上し、インデックスの断片化が減少するため、SQLServerはこの一時ストレージ領域を使用します。行数が1,048,577に達すると、SQLServerは行グループの状態を閉じます。 SQL Serverはこの行グループを圧縮し、状態を「圧縮」に変更します。
次に、テーブルを作成し、非クラスター化列ストアインデックスを追加します。
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO>
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
このステップでは、いくつかの行を挿入し、非クラスター化列ストアインデックスのプロパティを確認します。
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
このクエリは、行グループの状態、行サイズの総数、およびその他の値を表示します。
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

上の画像は、デルタストアの状態と圧縮されていない行の総数を示しています。次に、テーブルにさらにデータを入力し、行数が1,048,577に達すると、SQL Serverは最初の行グループを閉じて、新しい行グループを開きます。
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Serverはこの行グループを圧縮し、新しい行グループを作成します。 「COMPRESSION_DELAY」オプションを使用すると、行グループが閉じた状態で待機する時間を制御できます。

インデックス維持コマンド(再編成、再構築)を実行すると、削除された行が物理的に削除され、インデックスのフラグが解除されます。

このテーブルの一部の行を更新(削除+挿入)すると、削除された行は「削除済み」としてマークされ、新しく更新された行がデルタストアに挿入されます。
分析クエリパフォーマンスベンチマーク
この見出しでは、Analysis_TableTestテーブルにデータを入力します。 400万枚のレコードを挿入しました。 (このステップと次のステップをテスト環境でテストする必要があります。パフォーマンスの問題が発生する可能性があり、DBCC DROPCLEANBUFFERSコマンドによってパフォーマンスが低下する可能性があります。このコマンドは、バッファー・プール上のすべてのバッファー・データを削除します。)
次に、次の分析クエリを実行して、パフォーマンス値を調べます。
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

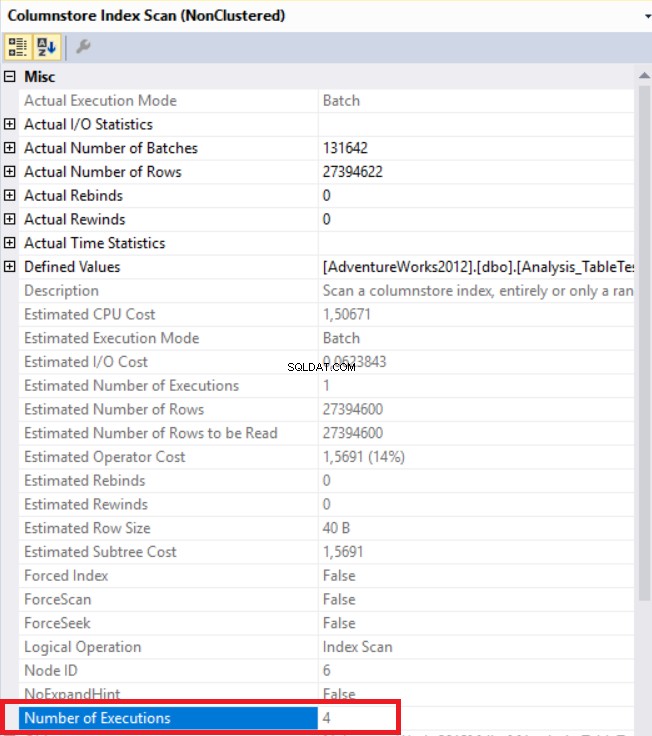
上の画像では、非クラスター化列ストアインデックススキャン演算子を確認できます。次の表は、CPUと実行時間を示しています。このクエリはCPUで1.765ミリ秒を消費し、0.791ミリ秒で完了します。実行プランは並列プロセッサを使用し、タスクを4プロセッサに分散するため、CPU時間は経過時間よりも長くなります。これは、「列ストアインデックススキャン」演算子のプロパティで確認できます。 「実行回数」の値はこれを示しています。

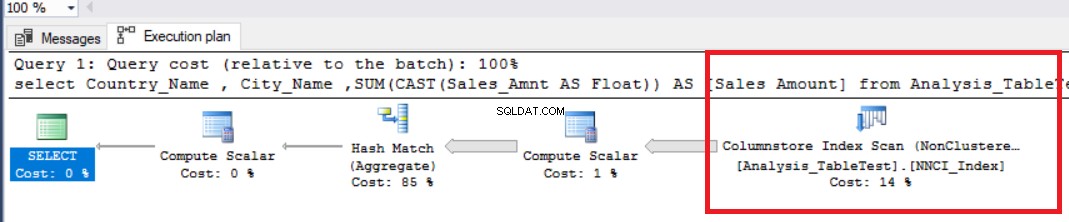
次に、プロセッサの数を減らすためのヒントをクエリに追加します。並列処理演算子は表示されません。
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

次の表は、実行時間を定義しています。このグラフでは、SQL Serverが1つのプロセッサのみを使用したため、経過時間がCPU時間よりも長いことがわかります。
次に、非クラスター化列ストアインデックスを無効にして、同じクエリを実行します。
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

上記の表は、非クラスター化列ストアインデックスが分析クエリで驚異的なパフォーマンスを提供することを示しています。およそ、列ストアのインデックス付きクエリは、他のクエリより5倍優れています。
結論
Real-Time Operational Analyticsは、データの待ち時間なしでOLTPシステムで分析クエリを実行できるため、信じられないほどの柔軟性を提供します。同時に、これらの分析クエリはOLTPデータベースのパフォーマンスに影響を与えません。この機能により、トランザクションデータと分析クエリを同じ環境で管理できるようになります。
参考資料
列ストアインデックス–データ読み込みガイダンス
リアルタイムの運用分析のための列ストアの使用を開始する
リアルタイム運用分析
参考資料:
SQL Serverインデックスの後方スキャン:理解、調整
SQLServerのメモリ最適化テーブルでのインデックスの使用