SQLServerインデックスの概要
Microsoft SQL Serverは、リレーショナルデータベース管理システム( RDBMS )の1つと見なされています。 )、データは、テーブルと呼ばれるデータコンテナに格納される行と列に論理的に編成されます。物理的には、テーブルは8KBページとして保存されます これは、ヒープまたはBツリーのクラスター化されたテーブルに編成できます。 ヒープ内 テーブルには、データページ内のデータの順序とそのテーブル内のページの順序を制御する並べ替え順序はありません。これは、そのテーブルに並べ替えメカニズムを適用するためのクラスター化インデックスが定義されていないためです。クラスター化インデックスがテーブル列のグループの1つの列で定義されている場合、データはクラスター化インデックスキー列の値に基づいてデータページ内で並べ替えられ、ページはこれらのインデックスキー値に基づいてリンクされます。このソートされたテーブルは、クラスター化テーブルと呼ばれます。 。
SQL Serverでは、インデックスはパフォーマンス調整プロセスにおいて重要かつ効果的なキーと見なされます。インデックスを作成する目的は、要求されたデータを返すためにすべてのテーブル行をスキャンする必要なしに、ベーステーブルへのアクセスを高速化し、要求されたデータを取得することです。データベースインデックスは、本全体を読んでその単語を見つける必要がなく、本の中の単語をすばやく見つけるのに役立つ本のインデックスと考えることができます。たとえば、顧客IDを使用して特定の顧客に関する情報を取得する必要があるとします。このテーブルの[顧客ID]列にインデックスが定義されていない場合、SQL Serverエンジンは、提供されたIDを持つ顧客を取得するために、すべてのテーブル行を1つずつチェックします。このテーブルの[顧客ID]列にインデックスが定義されている場合、SQL Serverエンジンは、ベーステーブルではなく、並べ替えられたインデックスで要求された顧客ID値を検索して、顧客に関する情報を取得し、スキャンされる数を減らします。データを取得する行。
SQL Serverでは、インデックスはBツリー形式の8Kページまたはインデックスノードとして論理的に構造化されています。 Bツリー構造には、次の3つのレベルが含まれます。ルートレベル これには、Bツリーの上部にあるリーフレベルの1つのインデックスページが含まれます。 これはBツリーの下部にあり、データページと中級レベルが含まれています。 これには、ルートレベルとリーフレベルの間にあるすべてのノードが含まれ、インデックスキー値と次のページへのポインタが含まれます。このBツリーの形状は、インデックスキーに基づいて、データページを左から右へ、上から下へとすばやくナビゲートする方法を提供します。
SQL Serverには、主に2つのタイプのインデックスがあります。クラスター化インデックスです。 データページ内のデータとページの順序はクラスター化されたインデックスに基づいて並べ替えられるため、実際のデータはインデックスのリーフレベルのページに格納され、テーブルごとに1つのクラスター化されたインデックスのみを作成できます。鍵。テーブルに主キー制約を定義した場合、そのテーブルにクラスター化インデックスが以前に定義されていなければ、クラスター化インデックスが自動的に作成されます。 2番目のタイプのインデックスは、非クラスター化インデックスです。 これには、インデックスキー列の並べ替えられたコピーと、ベーステーブルまたはクラスター化インデックスの残りの列へのポインターが含まれ、テーブルごとに最大999個の非クラスター化インデックスを作成できます。
SQL Serverは、一意のインデックスなど、他の特殊なタイプのインデックスを提供します。 これは、特定の列値の一意性を強制するために一意性制約が定義されたときに自動的に作成されます。複合インデックス 複数のキー列がインデックスキー、カバーインデックスに参加します 特定のクエリによって要求されたすべての列がインデックスキー、フィルタリングされたインデックスに参加します これは、テーブル行のごく一部のみにインデックスを付けるためのフィルター述語、空間インデックスを備えた、最適化された非クラスター化インデックスです。 これは、空間データを格納する列に作成され、XMLデータ型列のXMLバイナリラージオブジェクト(BLOB)に作成されるXMLインデックス、列ストアインデックス データが列データ形式で編成されている場合、フルテキストインデックス これは、SQLServerフルテキストエンジンとハッシュインデックスによって作成されます。 これは、メモリ最適化テーブルで使用されます。
以前はSQLServerインデックスを呼び出していたので、これは両刃の剣です。 、SQL Serverクエリオプティマイザーは、データ取得プロセスを高速化することでアプリケーションのパフォーマンスを向上させるように設計されたインデックスの恩恵を受けることができます。対照的に、不適切な方法で設計されたインデックスはSQL Serverクエリオプティマイザーによって選択されず、データ変更操作が遅くなり、データでそれを利用せずにストレージを消費するため、アプリケーションのパフォーマンスが低下します。検索プロセス。したがって、最初にインデックス作成のベストプラクティスとガイドラインに従い、開発環境で作成する場合の効果を確認し、データ取得操作の速度とデータ変更操作でそのインデックスを追加するオーバーヘッドの間の妥協点を見つけることをお勧めします。実稼働環境に適用する前の、そのインデックスのスペース要件。
インデックスを作成する前に、インデックスの作成と使用に影響を与えるさまざまな側面を調べる必要があります。これにはタイプが含まれます データベースワークロード、オンライントランザクション処理(OLTP)またはオンライン分析処理(OLAP)の、テーブルのサイズ 、テーブル列の特性 、並べ替え順序 クエリの列のうち、インデックスのタイプ これは、クエリと FILLFACTORなどのストレージプロパティに対応します およびPAD_INDEX 各リーフレベルと中間レベルのページのスペースの割合を制御するオプション。
SQLServerインデックスの断片化
DBAとしての作業は、適切なインデックスの作成に限定されません。インデックスを作成したら、インデックスの使用状況と統計を監視する必要があります。たとえば、このインデックスが適切に使用されていないか、まったく使用されていないかを知る必要があります。したがって、これらのインデックスを維持したり、より効率的なインデックスに置き換えたりするための正しいソリューションを提供できます。このようにして、システムに適用可能な最高のパフォーマンスを維持します。自問するかもしれませんが、SQL Serverクエリオプティマイザーが以前は使用していたのに、なぜインデックスを使用しなくなったのですか?
答えは主に、インデックスに反映される必要があるベーステーブルで実行される継続的なデータとスキーマの変更に関連しています。時間の経過とともに、これらすべての変更により、インデックスページが並べ替えられなくなり、インデックスが断片化されます。断片化のもう1つの理由は、新しい値を挿入しようとしたり、現在の値を更新しようとしたりして、新しい値が現在使用可能な空き領域に収まらないことです。この場合、ページは2つのページに分割され、最後のページの後に新しいページが物理的に作成されます。そして、断片化されたインデックスからの読み取りとスキャンする必要のあるページ数、そしてもちろん、これらのページ間の距離のために複数のレコードを取得するために実行されるI/O操作の数を想像できます。また、この断片化されたインデックスを使用するためのこの余分なコストのために、SQLServerクエリオプティマイザーはこのインデックスを無視します。
インデックスの断片化を取得するさまざまな方法
SQL Serverは、インデックスの断片化の割合を取得するためのさまざまな方法を提供します。最初の方法は、インデックスのインデックスの断片化の割合を確認することです。 プロパティ フラグメンテーションの下のウィンドウ 以下に示すように、タブ:
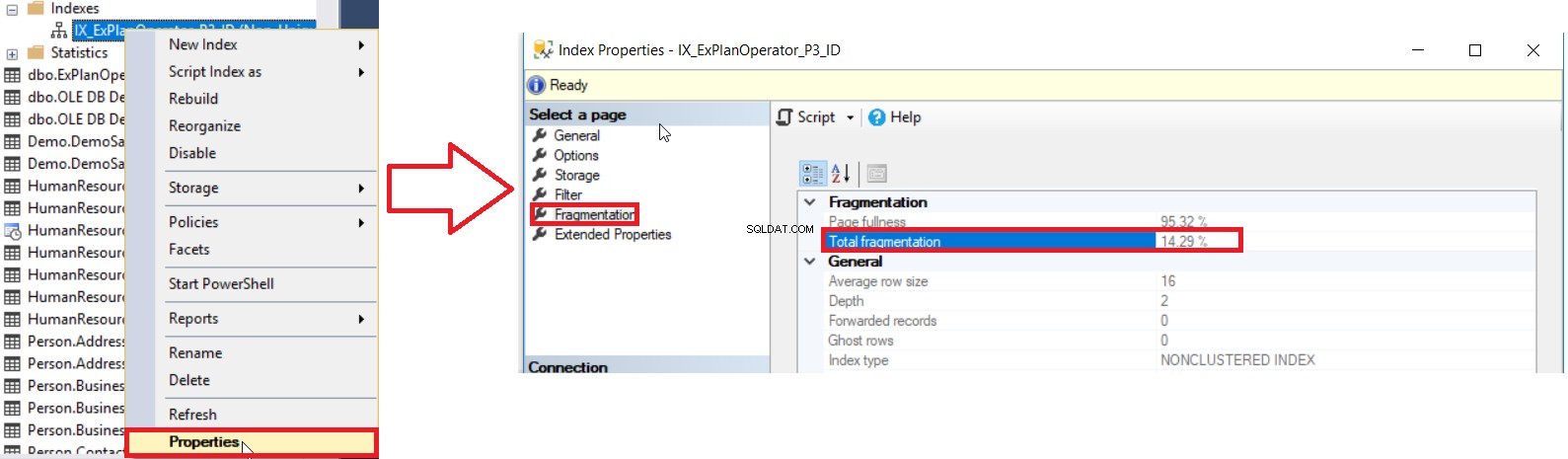
ただし、複数のインデックスの断片化レベルをチェックするには、最初にすべてのインデックスのUIメソッドチェックを1つずつ実行する必要があります。これは、時間の無駄な操作です。すべてのデータベースインデックスの断片化レベルを確認するために使用できる2番目の方法は、sys.dm_db_index_physical_stats DMFにクエリを実行し、sys.indexes DMVと結合して、これらのインデックスに関するすべての情報を取得することです。次のようなクエリを使用して、SQLServerサービスが再起動されます。
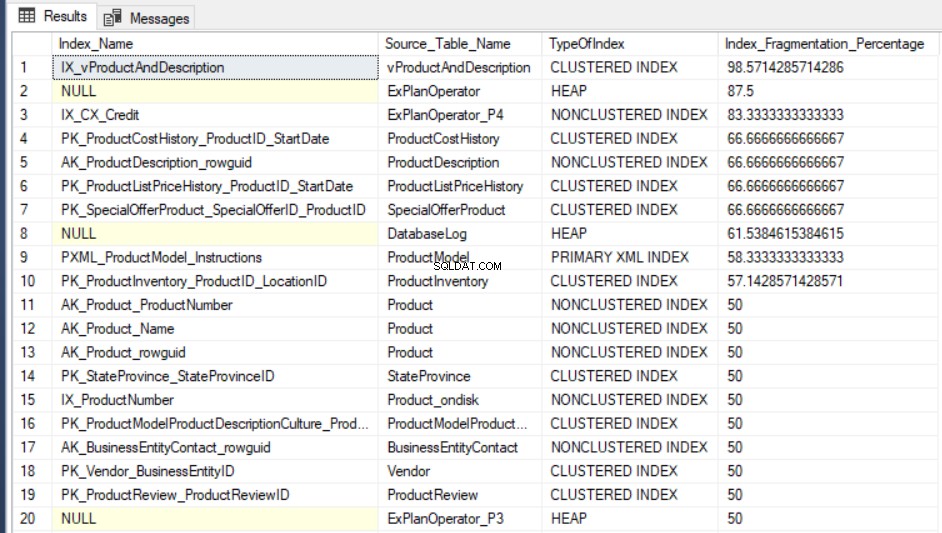
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
AdventureWorks2016CTP3のクエリの出力結果 テストデータベースは次のようになります:
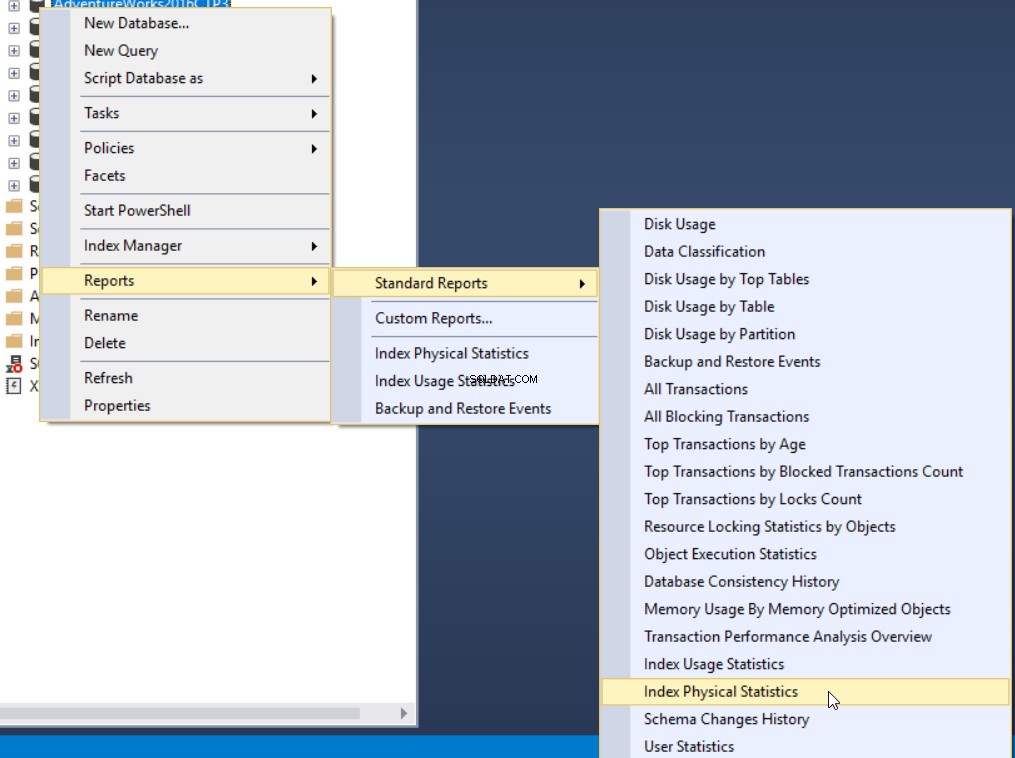
断片化の割合を取得する3番目の方法は、インデックス物理統計と呼ばれるSQLServerの組み込みの標準レポートを使用することです。このレポートは、インデックスパーティション、断片化の割合、各インデックスパーティションのページ数、およびインデックスを再構築または再編成することによってインデックスの断片化の問題を修正する方法に関する推奨事項に関する有用な情報を返します。レポートを表示するには、データベースを右クリックし、[レポート]オプション、[標準レポート]を選択して、以下のように[物理統計のインデックス作成]を選択します。
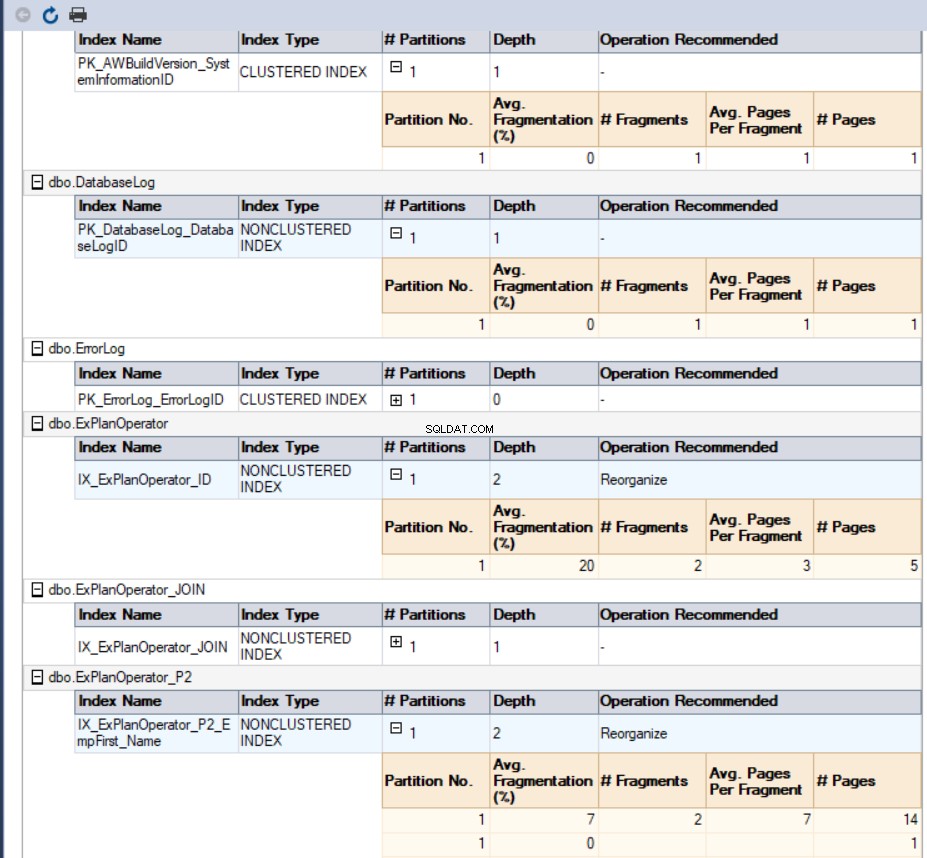
この場合、生成されるレポートは次のようになります。
すべてのデータベースインデックスの断片化率を取得する最後の最も簡単な方法は、dbForgeIndexManagerツールです。 dbForgeインデックスマネージャー ツールは、SQL Server ManagementStudioに追加してSQLServerデータベースインデックスを分析できるアドインであり、選択したデータベースインデックスのステータスと、これらのインデックスの断片化の問題を修正するためのメンテナンスの提案を含む非常に便利なレポートを提供します。
dbForge Index ManagerアドインをSSMSにインストールした後、スキャンするデータベースを右クリックして、 Index Managerを選択して実行できます。 、次にインデックスの断片化を管理 以下に示すように:
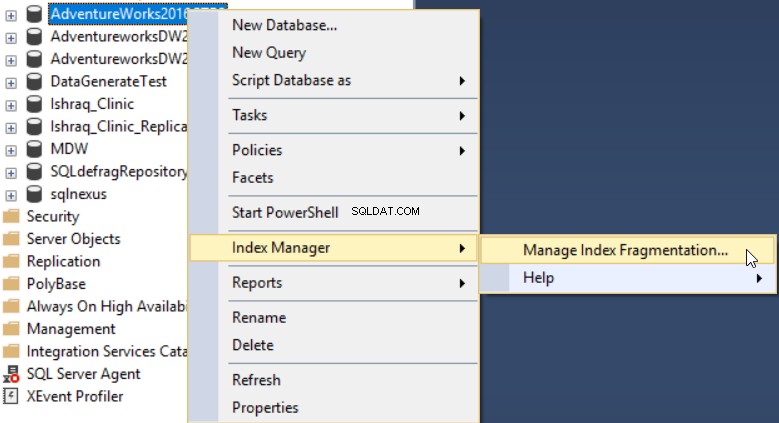
dbForge Index Managerツールを使用すると、以下に示すように、選択したデータベースインデックスの断片化の全体像を把握し、この問題を修正するための適切なアクションを推奨できます。

dbForge Index Managerツールを使用すると、データベースを切り替えることもでき、以下に示すように、このデータベースをスキャンした後に新しいレポートが提供されます。
以下に示すように、dbForge Index Managerツールによって生成されたインデックス断片化レポートをCSVファイルにエクスポートして、インデックスの断片化ステータスを分析できます。
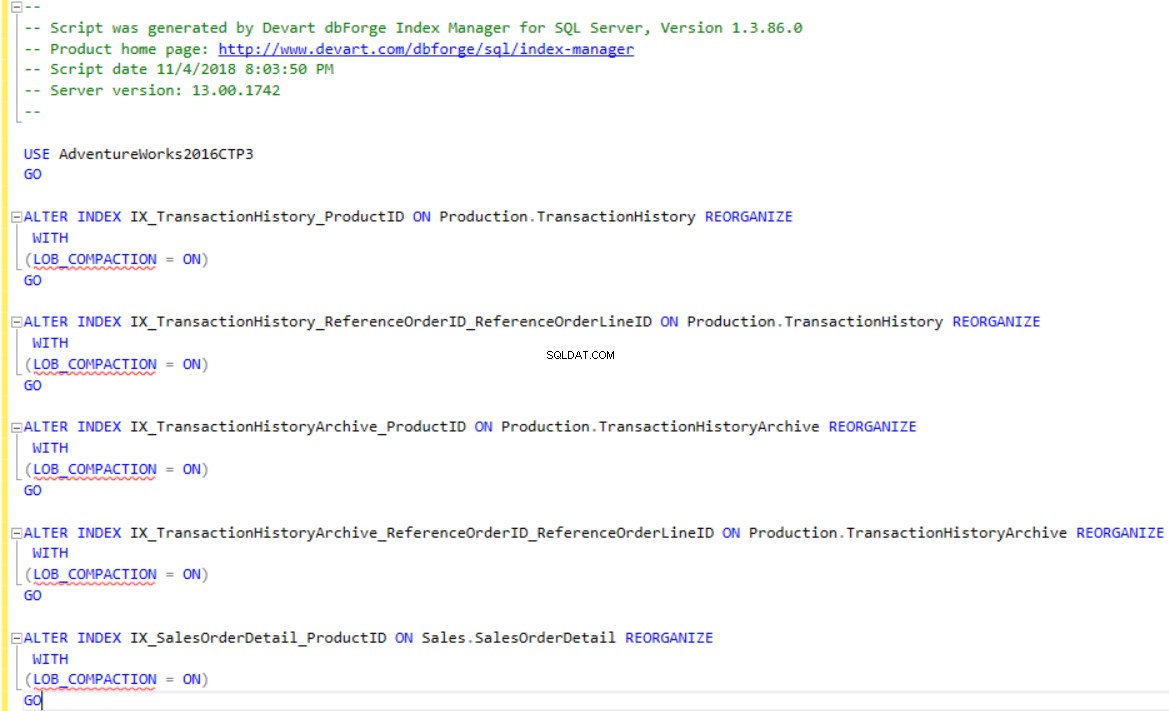
dbForge Index Managerを使用すると、T-SQLスクリプトを生成して、ツールの推奨事項に従ってインデックスを再構築または再編成できます。 スクリプトの変更を使用する 以下に示すように、フラグメント化されたインデックスのスクリプトを表示または保存するオプション:
dbForge Index Managerツールを使用すると、修正をクリックして、インデックスの断片化の問題を直接修正できます。 選択したインデックスに対して推奨されるアクションを直接実行するボタン。結果に修正ステータスを表示します。 以下に示す列:

再分析をクリックした場合 ボタンをクリックすると、修正操作が正常に実行された後、データベースのインデックスの断片化が再度スキャンされます。この記事に記載されているのは、dbForgeIndexManagerツールがインデックスの断片化の問題の特定と修正にどのように役立つかを紹介したものにすぎません。ダウンロードして、このツールで何ができるかを確認することをお勧めします。
便利なリンク:
- インデックスの基本
- インデックスの種類
- クラスター化インデックスと非クラスター化インデックスの説明
- クラスター化されたインデックス構造
便利なツール:
dbForge Index Manager – SQLインデックスのステータスを分析し、インデックスの断片化に関する問題を修正するための便利なSSMSアドイン。