
データの可用性、アクセス可能性、およびパフォーマンスは、ビジネスの成功に不可欠です。パフォーマンスの調整とSQLクエリの最適化には注意が必要ですが、データベースの専門家にとっては必要な方法です。いくつか例を挙げると、拡張イベント、パフォーマンス、実行プラン、統計、インデックスを使用して、さまざまなデータのコレクションを確認する必要があります。アプリケーションの所有者は、システムパフォーマンスを向上させるために、システムリソース(CPUとメモリ)を増やすように要求することがあります。ただし、これらの追加のリソースは必要ない場合があり、それらに関連するコストが発生する可能性があります。場合によっては、必要なのはクエリの動作を変更するためのマイナーな機能強化だけです。
この記事では、SQLクエリを作成するときに適用するSQLクエリ最適化のベストプラクティスについて説明します。
SELECT *vsSELECT列リスト
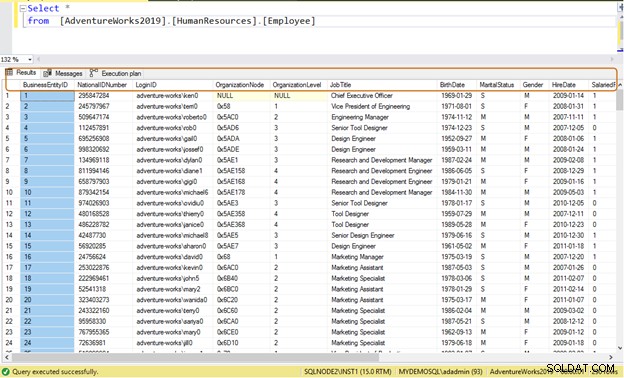
通常、開発者はSELECT*ステートメントを使用してテーブルからデータを読み取ります。テーブル内の列で使用可能なすべてのデータを読み取ります。テーブル[AdventureWorks2019]。[HumanResources]。[Employee]に290人の従業員のデータが格納されており、次の情報を取得する必要があるとします。
- 従業員の国民ID番号
- DOB
- 性別
- 採用日
非効率的なクエリ: SELECT *ステートメントを使用すると、290人の従業員すべてのすべての列のデータが返されます。
Select * from [AdventureWorks2019].[HumanResources].[Employee]から*を選択します
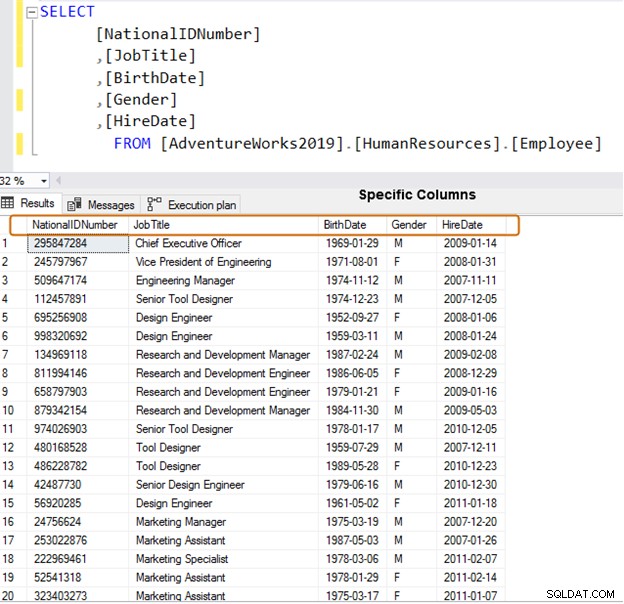
代わりに、データの取得に特定の列名を使用してください。
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
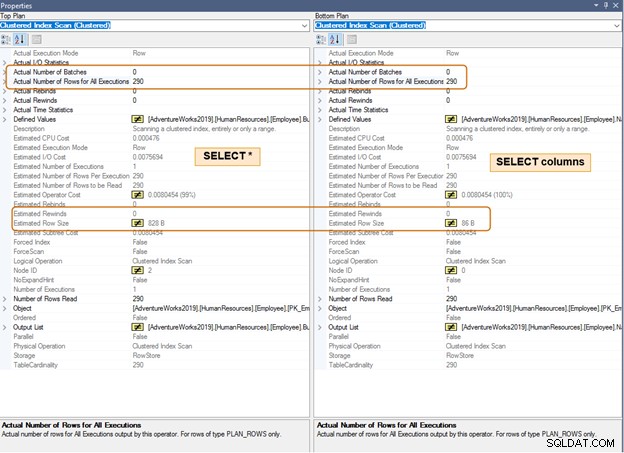
以下の実行プランでは、同じ行数の推定行サイズの違いに注意してください。多数の行でもCPUとIOの違いに気付くでしょう。
COUNT()とEXISTSの使用
特定のレコードがSQLテーブルに存在するかどうかを確認するとします。通常、COUNT(*)を使用してレコードをチェックし、出力内のレコード数を返します。
ただし、この目的でIF EXISTS()関数を使用することはできます。比較のために、クエリを実行する前に統計を有効にしました。
COUNT()のクエリ
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
IF EXISTS()のクエリ
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
両方のクエリの統計結果を分析するためにstatisticsparserを使用しました。以下の結果を見てください。 COUNT(*)を使用したクエリには276の論理読み取りがあり、IF EXISTS()には83の論理読み取りがあります。 IF EXISTS()を使用すると、論理読み取りをさらに大幅に削減することもできます。したがって、パフォーマンスを向上させるためにSQLクエリを最適化するために使用する必要があります。

SQLDISTINCTの使用は避けてください
クエリから一意のレコードが必要な場合は常に、SQLDISTINCT句を使用します。 2つのテーブルを結合し、出力で重複する行を返すとします。簡単な修正は、重複した行を抑制するDISTINCT演算子を指定することです。
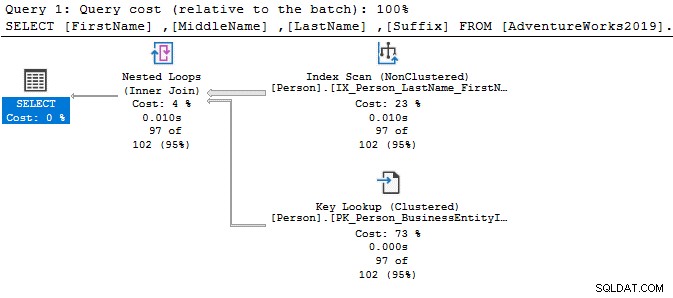
簡単なSELECTステートメントを見て、実行計画を比較してみましょう。両方のクエリの唯一の違いは、DISTINCT演算子です。
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
DISTINCT演算子を使用すると、クエリコストは77%になりますが、以前のクエリ(DISTINCTなし)のバッチコストは23%にすぎません。
結果セットから個別の値を取得するためにDISTINCTを使用する代わりに、GROUP BY、CTE、またはサブクエリを使用して効率的なSQLコードを記述できます。さらに、個別の結果セットの追加の列を取得できます。
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
SQLクエリでのワイルドカードの使用
指定された文字列で始まる名前を含む特定のレコードを検索するとします。開発者はワイルドカードを使用して、一致するレコードを検索します。
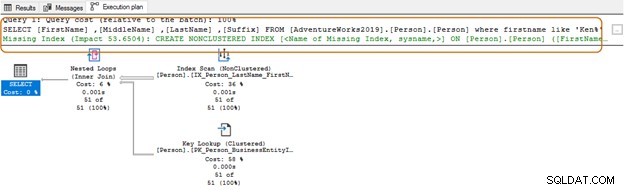
以下のクエリでは、名の列で文字列Kenを検索します。このクエリは、ケンの期待される結果を取得します ドラとケン ネット。ただし、Mac ken など、予期しない結果も発生します。 zieとNken ge。
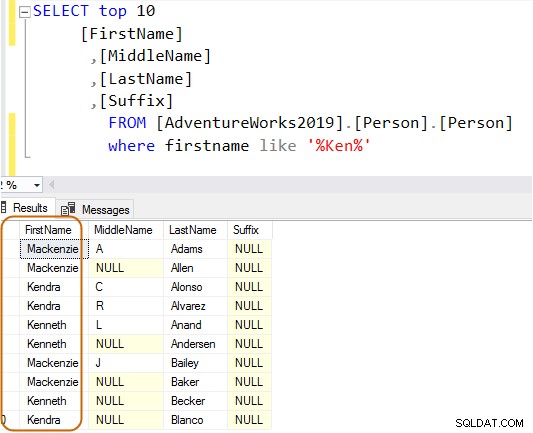
実行プランには、上記のクエリのインデックススキャンとキールックアップが表示されます。
文字列の最後にワイルドカード文字を使用すると、予期しない結果を回避できます。
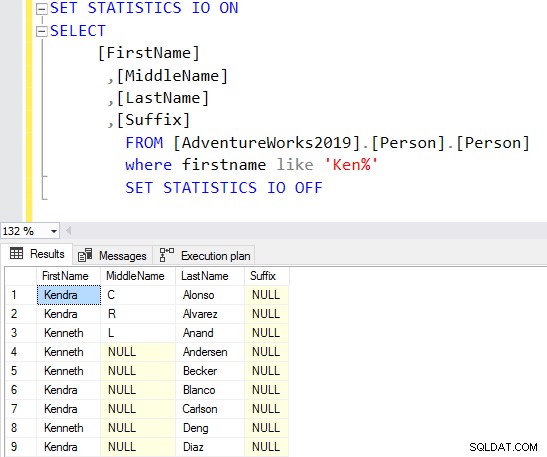
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
これで、要件に基づいてフィルタリングされた結果が得られます。
最初にワイルドカード文字を使用すると、クエリオプティマイザが適切なインデックスを使用できない場合があります。以下のスクリーンショットに示すように、末尾にワイルド文字が付いているクエリオプティマイザは、欠落しているインデックスも提案します。
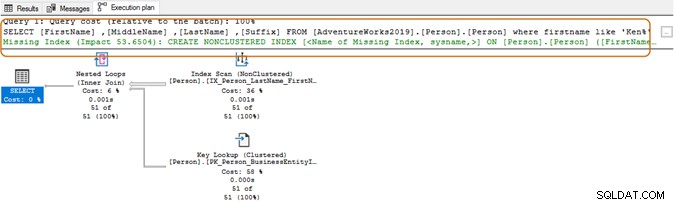
ここでは、アプリケーションの要件を評価する必要があります。クエリオプティマイザがテーブルスキャンを使用するように強制される可能性があるため、検索文字列でワイルドカード文字を使用しないようにする必要があります。テーブルが巨大な場合、IO、CPU、メモリに高いシステムリソースが必要になり、SQLクエリのパフォーマンスの問題が発生する可能性があります。
WHERE句とHAVING句の使用
WHERE句とHAVING句は、データ行フィルターとして使用されます。 WHERE句は、グループ化ロジックを適用する前にデータをフィルタリングしますが、HAVING句は、集計計算後に行をフィルタリングします。
たとえば、以下のクエリでは、WHERE句を指定せずにHAVING句でデータフィルタを使用しています。
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
次のクエリは、最初にWHERE句でデータをフィルタリングし、次に集合体データフィルタにHAVING句を使用します。
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Goとして選択します。
ベストプラクティスとして、データフィルタリングにはWHERE句を使用し、集合体データフィルタにはHAVING句を使用することをお勧めします。
IN句とEXISTS句の使用
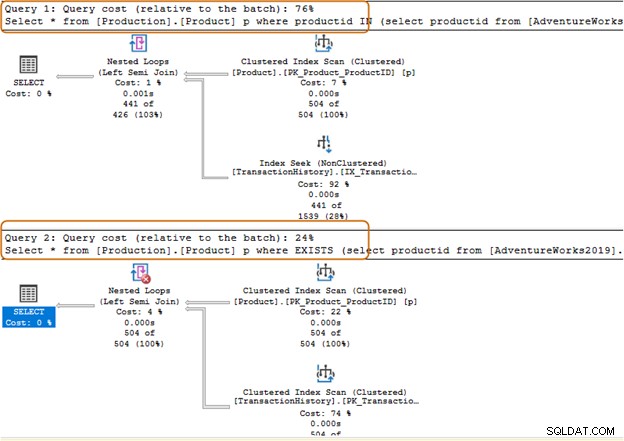
SQLクエリにIN演算子句を使用することは避けてください。たとえば、以下のクエリでは、最初に[Production]。[TransactionHistory])テーブルから製品IDを見つけ、次に[Production]。[Product]テーブルで対応するレコードを探しました。
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
以下のクエリでは、IN句をEXISTS句に置き換えました。
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
それでは、両方のクエリを実行した後の統計を比較してみましょう。
IN句は504スキャンを使用し、EXISTS句は[Production]。[TransactionHistory])テーブル]に1スキャンを使用します。
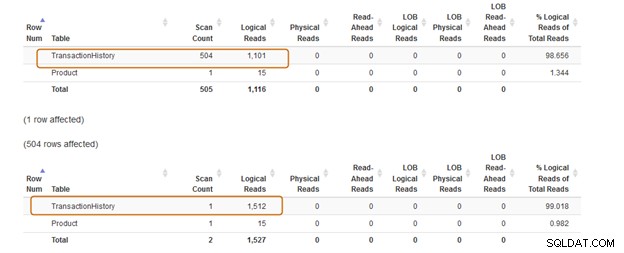
IN句のクエリバッチのコストは74%ですが、EXISTS句のコストは24%です。したがって、特にサブクエリが大きなデータセットを返す場合は、IN句を避ける必要があります。
欠落しているインデックス
SQLクエリを実行し、SSMSで実際の実行プランを探すと、SQLクエリを改善する可能性のあるインデックスに関する提案が表示される場合があります。
または、動的管理ビューを使用して、環境で欠落しているインデックスの詳細を確認することもできます。
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
通常、DBAはSSMSからのアドバイスに従い、インデックスを作成します。現時点では、クエリのパフォーマンスが向上する可能性があります。ただし、これらの推奨事項に基づいてインデックスを直接作成しないでください。他のクエリのパフォーマンスに影響を与え、INSERTステートメントとUPDATEステートメントの速度を低下させる可能性があります。
- まず、SQLテーブルの既存のインデックスを確認します。
- インデックスのオーバーインデックスとインデックス不足はどちらもクエリのパフォーマンスに悪影響を及ぼします。
- 既存のインデックスを確認した後、最も影響の大きい不足しているインデックスの推奨事項を適用し、それを下位環境に実装します。新しい欠落しているインデックスを実装した後、ワークロードが正常に機能する場合は、tを追加する価値があります。
インデックス作成の詳細なベストプラクティスについては、次の記事を参照することをお勧めします:パフォーマンスチューニングを改善するための11SQLServerインデックスのベストプラクティス。
クエリのヒント
開発者は、t-SQLステートメントでクエリヒントを明示的に指定します。これらのクエリヒントは、クエリオプティマイザの動作を上書きし、クエリヒントに基づいて実行プランを準備するように強制します。頻繁に使用されるクエリヒントは、NOLOCK、Optimize For、およびRecompile Merge / Hash/Loopです。これらは、クエリの短期的な修正です。ただし、永続的なソリューションについては、クエリ、インデックス、統計、および実行プランの分析に取り組む必要があります。
ベストプラクティスに従って、クエリヒントの使用を最小限に抑える必要があります。 SQLクエリの意味を最初に理解した後で、クエリヒントを使用し、不必要に使用しないようにします。
SQLクエリ最適化のリマインダー
すでに説明したように、SQLクエリの最適化は制限のない道です。パフォーマンスを大幅に向上させることができるベストプラクティスと小さな修正を適用できます。クエリ開発を改善するために、次のヒントを検討してください。
- 常にシステムリソース(ディスク、CPU、メモリ)の割り当てを確認します
- 起動トレースフラグ、インデックス、データベースメンテナンスタスクを確認します
- 拡張イベント、プロファイラー、またはサードパーティのデータベース監視ツールを使用してワークロードを分析します
- 最初にテスト環境に(100%自信がある場合でも)常にソリューションを実装し、その影響を分析します。満足したら、本番環境の実装を計画します