歴史的に、PostgreSQLを使用する際の最も困難な作業は、アップグレードの処理でした。考えられる最も直感的なアップグレード方法は、新しいバージョンでレプリカを生成し、そのレプリカへのアプリケーションのフェイルオーバーを実行することです。 PostgreSQLでは、これはネイティブな方法では不可能でした。アップグレードを実行するには、pg_upgradeの使用、ダンプと復元、SlonyやBucardoなどのサードパーティツールの使用など、他のアップグレード方法を考える必要がありました。これらにはすべて独自の注意事項があります。
なんでこれ? PostgreSQLがレプリケーションを実装する方法のため。
PostgreSQLの組み込みストリーミングレプリケーションは、いわゆる物理レプリケーションです。変更をバイト単位でレプリケートし、別のサーバーにデータベースの同一のコピーを作成します。この方法では、アップグレードを検討する際に多くの制限があります。これは、異なるサーバーバージョン、または異なるアーキテクチャでさえレプリカを作成できないためです。
したがって、ここでPostgreSQL10がゲームチェンジャーになります。これらの新しいバージョン10および11では、PostgreSQLは組み込みの論理レプリケーションを実装しており、物理レプリケーションとは対照的に、PostgreSQLの異なるメジャーバージョン間でレプリケートできます。もちろん、これは戦略をアップグレードするための新しい扉を開きます。
このブログでは、論理レプリケーションを使用してダウンタイムなしでPostgreSQL10をPostgreSQL11にアップグレードする方法を見てみましょう。まず、論理レプリケーションの概要を見ていきましょう。
論理レプリケーションとは何ですか?
論理レプリケーションは、レプリケーションID(通常は主キー)に基づいて、データオブジェクトとその変更をレプリケートする方法です。これは、1つ以上のサブスクライバーがパブリッシャーノード上の1つ以上のパブリケーションをサブスクライブするパブリッシュアンドサブスクライブモードに基づいています。
パブリケーションは、テーブルまたはテーブルのグループから生成された一連の変更です(レプリケーションセットとも呼ばれます)。パブリケーションが定義されているノードは、パブリッシャーと呼ばれます。サブスクリプションは、論理レプリケーションのダウンストリーム側です。サブスクリプションが定義されているノードはサブスクライバーと呼ばれ、サブスクライブする別のデータベースおよび一連のパブリケーション(1つ以上)への接続を定義します。購読者は、購読している出版物からデータを取得します。
論理レプリケーションは、物理ストリーミングレプリケーションと同様のアーキテクチャで構築されています。これは、「walsender」および「apply」プロセスによって実装されます。 walsenderプロセスは、WALの論理デコードを開始し、標準の論理デコードプラグインをロードします。プラグインは、WALから読み取った変更を論理レプリケーションプロトコルに変換し、パブリケーション仕様に従ってデータをフィルタリングします。次に、データはストリーミングレプリケーションプロトコルを使用して適用ワーカーに継続的に転送されます。適用ワーカーは、データをローカルテーブルにマッピングし、受信した個々の変更を正しいトランザクション順序で適用します。
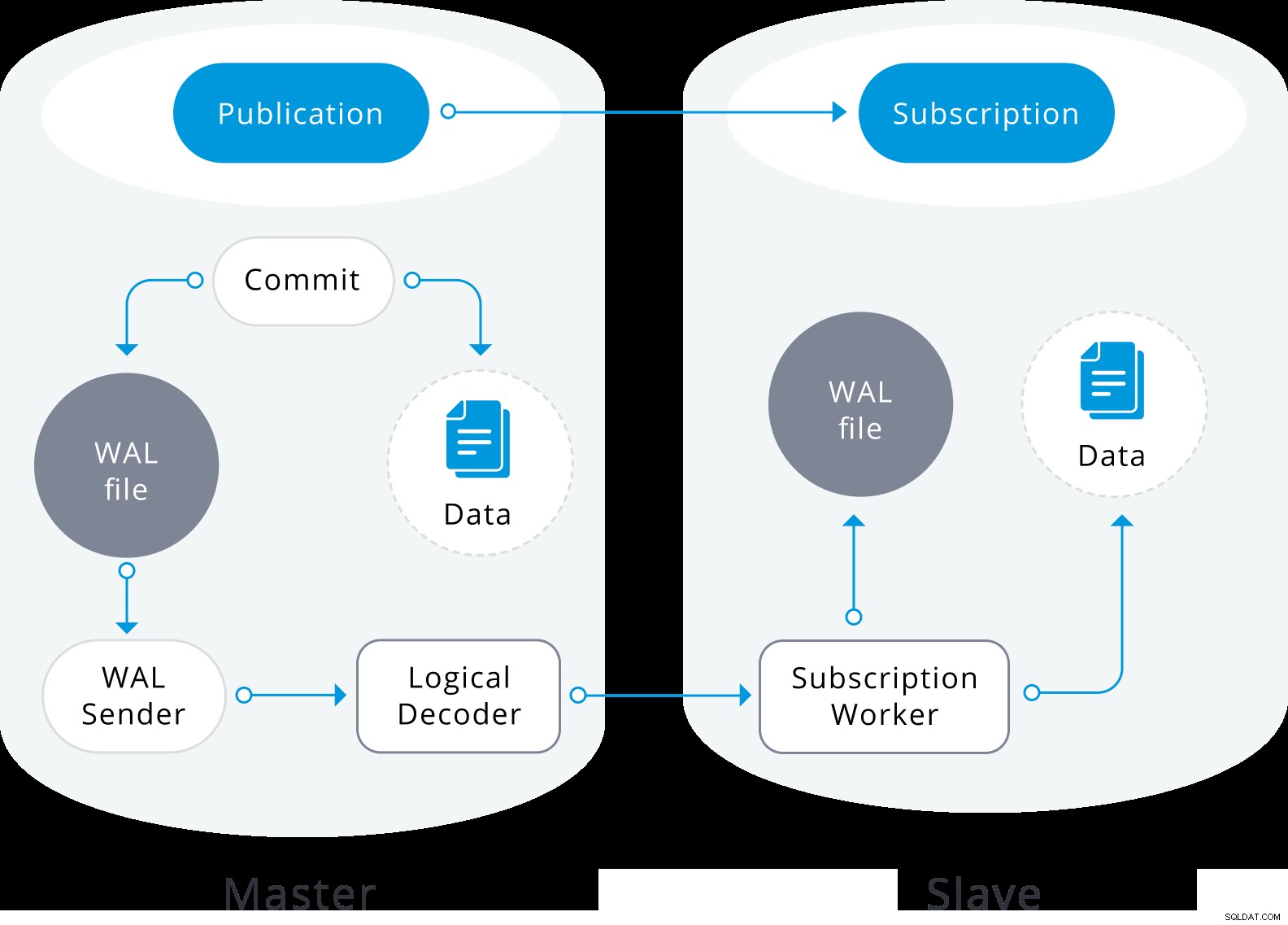 論理レプリケーション図
論理レプリケーション図 論理レプリケーションは、パブリッシャーデータベース上のデータのスナップショットを取得し、それをサブスクライバーにコピーすることから始まります。既存のサブスクライブされたテーブルの初期データは、スナップショットが作成され、特別な種類の適用プロセスの並列インスタンスにコピーされます。このプロセスにより、独自の一時レプリケーションスロットが作成され、既存のデータがコピーされます。既存のデータがコピーされると、ワーカーは同期モードに入ります。これにより、標準の論理レプリケーションを使用して最初のデータコピー中に発生した変更をストリーミングすることにより、テーブルがメインの適用プロセスと同期された状態になります。同期が完了すると、テーブルのレプリケーションの制御がメインの適用プロセスに戻され、レプリケーションは通常どおり続行されます。パブリッシャーでの変更は、リアルタイムで発生したときにサブスクライバーに送信されます。
論理レプリケーションの詳細については、次のブログをご覧ください。
- PostgreSQLでの論理レプリケーションの概要
- PostgreSQLストリーミングレプリケーションと論理レプリケーション
論理レプリケーションを使用してPostgreSQL10をPostgreSQL11にアップグレードする方法
したがって、この新機能が何であるかがわかったので、アップグレードの問題を解決するためにそれをどのように使用できるかを考えることができます。
PostgreSQLの2つの異なるメジャーバージョン(10と11)間で論理レプリケーションを構成します。もちろん、これが機能した後は、新しいバージョンでデータベースへのアプリケーションフェイルオーバーを実行するだけです。
論理レプリケーションを機能させるには、次の手順を実行します。
- パブリッシャーノードを構成します
- サブスクライバーノードを構成します
- サブスクライバーユーザーを作成する
- パブリケーションを作成する
- サブスクライバーでテーブル構造を作成します
- サブスクリプションを作成する
- レプリケーションステータスを確認します
それでは始めましょう。
パブリッシャー側では、postgresql.confファイルで次のパラメーターを構成します。
- listen_addresses:リッスンするIPアドレス。すべてに「*」を使用します。
- wal_level:WALに書き込まれる情報の量を決定します。論理に設定します。
- max_replication_slots:サーバーがサポートできるレプリケーションスロットの最大数を指定します。少なくとも接続が予想されるサブスクリプションの数に加えて、テーブル同期用の予約数に設定する必要があります。
- max_wal_senders:スタンバイサーバーまたはストリーミングベースのバックアップクライアントからの同時接続の最大数を指定します。少なくともmax_replication_slotsに、同時に接続される物理レプリカの数を加えたものと同じに設定する必要があります。
これらのパラメータの一部を適用するには、PostgreSQLサービスを再起動する必要があることに注意してください。
pg_hba.confファイルも、レプリケーションを許可するように調整する必要があります。レプリケーションユーザーがデータベースに接続できるようにする必要があります。
これに基づいて、パブリッシャー(この場合はPostgreSQL 10サーバー)を次のように構成しましょう。
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
レプリケーションに使用されるユーザー(この例ではrep)と、PostgreSQL11に対応するIPのIPアドレス192.168.100.144/32を変更する必要があります。
加入者側では、max_replication_slotsも設定する必要があります。この場合、少なくともサブスクライバーに追加されるサブスクリプションの数に設定する必要があります。
ここでも設定する必要のあるその他のパラメータは次のとおりです。
- max_logical_replication_workers:論理レプリケーションワーカーの最大数を指定します。これには、適用ワーカーとテーブル同期ワーカーの両方が含まれます。論理レプリケーションワーカーは、max_worker_processesで定義されたプールから取得されます。少なくともサブスクリプションの数に加えて、テーブル同期用の予約を設定する必要があります。
- max_worker_processes:システムがサポートできるバックグラウンドプロセスの最大数を設定します。レプリケーションワーカーに対応するように調整する必要がある場合があります。少なくともmax_logical_replication_workers+1です。このパラメーターにはPostgreSQLの再起動が必要です。
したがって、サブスクライバー(この場合はPostgreSQL 11サーバー)を次のように構成する必要があります。
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
このPostgreSQL11はまもなく新しいマスターになるため、後でサービスが新たに再起動しないように、このステップでwal_levelパラメーターとarchive_modeパラメーターを追加することを検討する必要があります。
wal_level = logical
archive_mode = onこれらのパラメータは、新しいレプリケーションスレーブを追加する場合、またはPITRバックアップを使用する場合に役立ちます。
パブリッシャーでは、サブスクライバーが接続するユーザーを作成する必要があります:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEレプリケーション接続に使用されるロールには、REPLICATION属性が必要です。ロールへのアクセスはpg_hba.confで構成する必要があり、LOGIN属性を持っている必要があります。
初期データをコピーできるようにするには、レプリケーション接続に使用されるロールに、公開されたテーブルに対するSELECT権限が必要です。
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTすべてのテーブルについて、パブリッシャーノードにpub1パブリケーションを作成します:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONパブリケーションを作成するユーザーは、データベースでCREATE権限を持っている必要がありますが、すべてのテーブルを自動的に公開するパブリケーションを作成するには、ユーザーはスーパーユーザーである必要があります。
作成されたパブリケーションを確認するために、pg_publicationカタログを使用します。このカタログには、データベースで作成されたすべての出版物に関する情報が含まれています。
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | t列の説明:
- pubname:パブリケーションの名前。
- 出版社:出版物の所有者。
- puballtables:trueの場合、このパブリケーションには、将来作成されるテーブルを含む、データベース内のすべてのテーブルが自動的に含まれます。
- pubinsert:trueの場合、INSERT操作はパブリケーション内のテーブルに複製されます。
- pubupdate:trueの場合、UPDATE操作はパブリケーション内のテーブルに複製されます。
- pubdelete:trueの場合、パブリケーション内のテーブルに対してDELETE操作が複製されます。
スキーマは複製されないため、PostgreSQL 10でバックアップを取り、PostgreSQL 11で復元する必要があります。情報は最初の転送で複製されるため、バックアップはスキーマに対してのみ行われます。
PostgreSQL 10の場合:
$ pg_dumpall -s > schema.sqlPostgreSQL 11の場合:
$ psql -d postgres -f schema.sqlPostgreSQL 11でスキーマを取得したら、サブスクリプションを作成し、host、dbname、user、およびpasswordの値を環境に対応する値に置き換えます。
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTION上記はレプリケーションプロセスを開始します。レプリケーションプロセスは、パブリケーション内のテーブルの初期テーブルコンテンツを同期してから、それらのテーブルへの増分変更のレプリケーションを開始します。
サブスクリプションを作成するユーザーは、スーパーユーザーである必要があります。サブスクリプションの適用プロセスは、スーパーユーザーの権限でローカルデータベースで実行されます。
作成されたサブスクリプションを確認するには、pg_stat_subscriptionカタログを使用できます。このビューには、メインワーカーのサブスクリプションごとに1つの行(ワーカーが実行されていない場合はnull PID)と、サブスクライブされたテーブルの初期データコピーを処理するワーカーの追加の行が含まれます。
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00列の説明:
- subid:サブスクリプションのOID。
- subname:サブスクリプションの名前。
- pid:サブスクリプションワーカープロセスのプロセスID。
- relid:ワーカーが同期している関係のOID。メインの適用ワーカーの場合はnull。
- received_lsn:最後に受信したログ先行書き込みの場所。このフィールドの初期値は0です。
- last_msg_send_time:発信元のWAL送信者から受信した最後のメッセージの送信時刻。
- last_msg_receipt_time:発信元のWAL送信者から受信した最後のメッセージの受信時刻。
- latest_end_lsn:発信元のWAL送信者に報告された最後の先行書き込みログの場所。
- latest_end_time:発信元のWAL送信者に報告された最後の先行書き込みログの場所の時刻。
マスターでのレプリケーションのステータスを確認するには、pg_stat_replicationを使用できます:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async列の説明:
- pid:WAL送信者プロセスのプロセスID。
- usesysid:このWAL送信者プロセスにログインしたユーザーのOID。
- usename:このWAL送信者プロセスにログインしているユーザーの名前。
- application_name:このWAL送信者に接続されているアプリケーションの名前。
- client_addr:このWAL送信者に接続されているクライアントのIPアドレス。このフィールドがnullの場合、クライアントがサーバーマシンのUnixソケットを介して接続されていることを示します。
- client_hostname:client_addrの逆DNSルックアップによって報告された、接続されたクライアントのホスト名。このフィールドは、IP接続の場合、およびlog_hostnameが有効になっている場合にのみnull以外になります。
- client_port:クライアントがこのWAL送信者との通信に使用しているTCPポート番号。Unixソケットが使用されている場合は-1。
- backend_start:このプロセスが開始された時刻。
- backend_xmin:hot_standby_feedbackによって報告されたこのスタンバイのxminホライズン。
- 状態:現在のWAL送信者の状態。可能な値は、起動、キャッチアップ、ストリーミング、バックアップ、および停止です。
- send_lsn:この接続で送信された最後の先行書き込みログの場所。
- write_lsn:このスタンバイサーバーによってディスクに書き込まれた最後の先行書き込みログの場所。
- flush_lsn:このスタンバイサーバーによってディスクにフラッシュされた最後の先行書き込みログの場所。
- replay_lsn:このスタンバイサーバー上のデータベースに再生された最後の先行書き込みログの場所。
- write_lag:最近のWALをローカルでフラッシュしてから、このスタンバイサーバーが書き込みを行ったという通知を受信するまでの経過時間(ただし、まだフラッシュまたは適用されていません)。
- flush_lag:最近のWALをローカルでフラッシュしてから、このスタンバイサーバーがWALを書き込んでフラッシュした(ただしまだ適用していない)という通知を受信するまでの経過時間。
- replay_lag:最近のWALをローカルでフラッシュしてから、このスタンバイサーバーが書き込み、フラッシュ、および適用したという通知を受信するまでの経過時間。
- sync_priority:優先度ベースの同期レプリケーションで同期スタンバイとして選択されるこのスタンバイサーバーの優先度。
- sync_state:このスタンバイサーバーの同期状態。可能な値は、async、potential、sync、quorumです。
最初の転送がいつ終了したかを確認するために、サブスクライバーのPostgreSQLログを確認できます。
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedまたは、pg_subscription_relカタログのsrsubstate変数を確認します。このカタログには、各サブスクリプションで複製された各リレーションの状態が含まれています。
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90列の説明:
- srsubid:サブスクリプションへの参照。
- srrelid:関係への参照。
- srsubstate:状態コード:i =初期化、d =データのコピー中、s =同期、r =準備完了(通常のレプリケーション)。
- srsublsn:sおよびr状態のLSNを終了します。
PostgreSQL 10にいくつかのテストレコードを挿入し、PostgreSQL11にそれらがあることを検証できます。
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)この時点で、アプリケーションをPostgreSQL11にポイントする準備が整いました。
このためには、まず、レプリケーションの遅延がないことを確認する必要があります。
マスターについて:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0そして今、エンドポイントをアプリケーションまたはロードバランサー(ある場合)から新しいPostgreSQL11サーバーに変更するだけで済みます。
HAProxyのようなロードバランサーがある場合は、次のようにPostgreSQL 10をアクティブとして、PostgreSQL11をバックアップとして使用して構成できます。
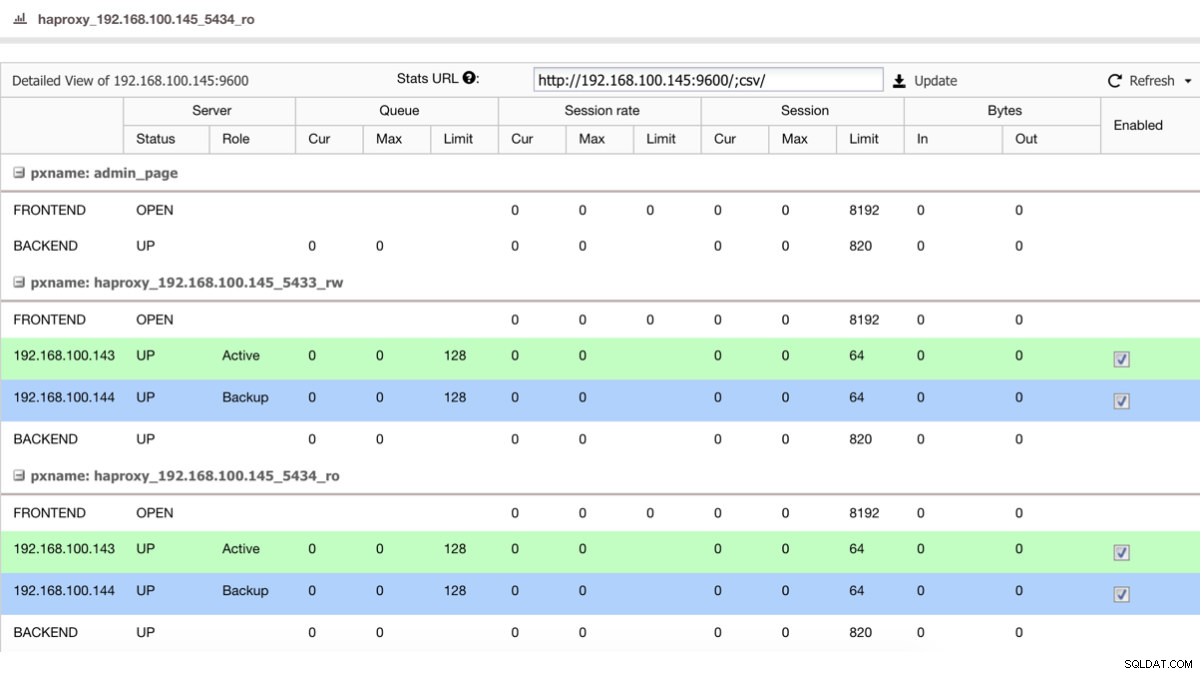 HAProxyステータスビュー
HAProxyステータスビュー したがって、PostgreSQL 10でマスターをシャットダウンした場合、バックアップサーバー(この場合はPostgreSQL 11)は、ユーザー/アプリケーションに対して透過的な方法でトラフィックの受信を開始します。
移行の最後に、PostgreSQL11の新しいマスターのサブスクリプションを削除できます。
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONそして、それが正しく削除されていることを確認します:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)制限
論理レプリケーションを使用する前に、次の制限に注意してください。
- データベーススキーマとDDLコマンドは複製されません。初期スキーマは、pg_dump--schema-onlyを使用してコピーできます。
- シーケンスデータは複製されません。シーケンスに裏打ちされたシリアル列またはID列のデータはテーブルの一部として複製されますが、シーケンス自体には引き続きサブスクライバーの開始値が表示されます。
- TRUNCATEコマンドのレプリケーションはサポートされていますが、外部キーで接続されたテーブルのグループを切り捨てる場合は注意が必要です。切り捨てアクションを複製する場合、サブスクライバーは、サブスクリプションの一部ではないテーブルを除いて、明示的に指定された、またはCASCADEを介して暗黙的に収集された、パブリッシャーで切り捨てられたテーブルの同じグループを切り捨てます。影響を受けるすべてのテーブルが同じサブスクリプションの一部である場合、これは正しく機能します。ただし、サブスクライバーで切り捨てられるテーブルの一部に、同じ(またはいずれかの)サブスクリプションの一部ではないテーブルへの外部キーリンクがある場合、サブスクライバーでの切り捨てアクションの適用は失敗します。
- 大きなオブジェクトは複製されません。通常のテーブルにデータを保存する以外に、その回避策はありません。
- レプリケーションは、ベーステーブルからベーステーブルへの複製のみが可能です。つまり、パブリケーション側とサブスクリプション側のテーブルは、ビュー、マテリアライズドビュー、パーティションルートテーブル、または外部テーブルではなく、通常のテーブルである必要があります。パーティションの場合、パーティション階層を1対1で複製できますが、現在、別のパーティションに分割されたセットアップに複製することはできません。
結論
定期的なアップグレードを実行してPostgreSQLサーバーを最新の状態に保つことは必要でしたが、PostgreSQL10バージョンまでは困難な作業でした。
このブログでは、バージョン10でネイティブに導入されたPostgreSQL機能である論理レプリケーションについて簡単に紹介しました。ダウンタイムゼロの戦略でこの課題を達成するのにどのように役立つかを示しました。