これらのテスト (データベース AdventureWorks2008R2) は何が起こるかを示しています:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
結果:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
SET STATISTICS IO の結果 LIO が同じであることを示しています .しかし、実行計画はかなり異なります。 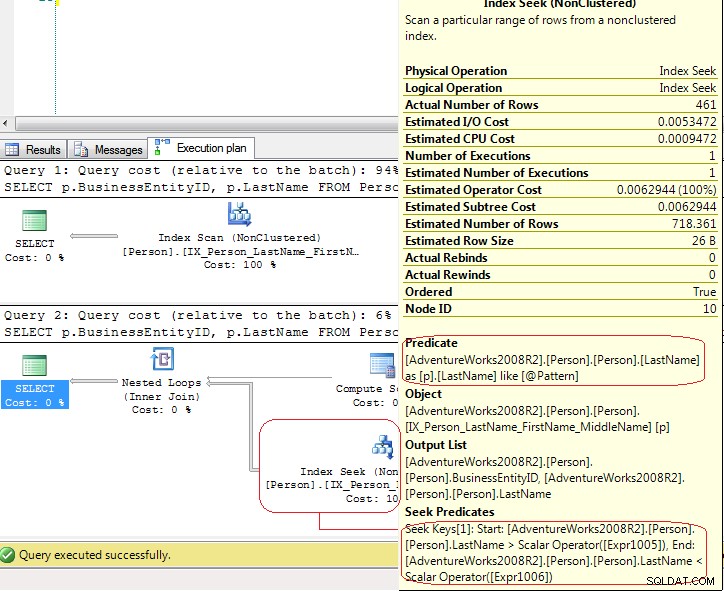
最初のテストでは、SQL Server は Index Scan を使用します 明示的ですが、2 番目のテストでは SQL Server は Index Seek を使用します これは Index Seek - range scan です .最後のケースでは、SQL Server は Compute Scalar を使用します これらの値を生成する演算子
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
そして、Index Seek 演算子は Seek Predicate を使用します (最適化) range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) と別の最適化されていない Predicate (LastName LIKE @pattern ).
私の答え:「本当の」 Index Seek ではありません .これは Index Seek - range scan です この場合、Index Scan と同じパフォーマンスです。 .
Index Seek の違いも参照してください。 および Index Scan (同様の議論):それで…シークですか、それともスキャンですか?
.
編集 1: OPTION(RECOMPILE) の実行計画 (Aaron の推奨事項を参照してください) Index Scan も示しています (Index Seek の代わりに ):