本番環境に移行することは非常に重要なタスクであり、事前に慎重に検討して計画する必要があります。あまり良くない決定は後で簡単に修正できるものもありますが、そうでないものもあります。ですから、後で後悔するよりも、他の人が作った公式のドキュメント、本、研究を早く読むことにその余分な時間を費やす方が常に良いです。これはほとんどのコンピューターシステムの展開に当てはまり、PostgreSQLも例外ではありません。
システムの初期計画
システムが稼働する前に、いくつかの決定を早い段階で行う必要があります。 PostgreSQL DBAは、いくつかの質問に答える必要があります。DBは、ベアメタル、VM、またはコンテナ化された状態で実行されますか?組織の敷地内で実行されますか、それともクラウドで実行されますか?どのOSを使用しますか?ストレージはスピニングディスクタイプまたはSSDになりますか?シナリオや決定ごとに賛否両論があり、組織の要件に応じて利害関係者と協力して最終的な電話がかけられます。従来、人々はベアメタル上でPostgreSQLを実行していましたが、これは近年劇的に変化し、PostgreSQLを標準オプションとして提供するクラウドプロバイダーが増えています。これは、PostgreSQLの幅広い採用と人気の高まりの結果です。特定のソリューションとは関係なく、DBAはデータが安全であることを確認する必要があります。つまり、データベースはクラッシュに耐えることができます。これは、ハードウェアとストレージに関する決定を行う際の第1の基準です。これで最初のヒントになります!
ヒント1
ディスクコントローラー、ディスクメーカー、またはクラウドストレージプロバイダーが何を宣伝していても、ストレージがfsyncに依存していないことを常に確認する必要があります。 fsyncがOKを返すと、その後に何が起こっても(クラッシュ、電源障害など)、データはメディア上で安全になります。ディスクのライトバックキャッシュの信頼性をテストするのに役立つ優れたツールの1つは、diskchecker.plです。
メモを読んでください:https://brad.livejournal.com/2116715.htmlそしてテストを行ってください。
1台のマシンを使用してイベントをリッスンし、実際のマシンを使用してテストします。表示されるはずです:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0テストされたマシンのレポートの最後に。
信頼性に続く2番目の懸念は、パフォーマンスに関するものです。システム(CPU、メモリ)に関する決定は、後で変更するのが非常に困難であったため、以前ははるかに重要でした。しかし、今日のクラウド時代では、DBが実行されているシステムについてより柔軟に対応できます。同じことがストレージにも当てはまります。特に、システムの初期の段階で、サイズがまだ小さい場合はそうです。 DBのサイズがTBの数値を超えると、データベースを完全にコピーする必要なしに基本的なストレージパラメータを変更することがますます難しくなり、さらに悪いことに、pg_dump、pg_restoreを実行する必要がなくなります。 2番目のヒントは、システムパフォーマンスに関するものです。
ヒント2
信頼性に関するメーカーの約束を常にテストするのと同様に、ハードウェアのパフォーマンスについても同じことを行う必要があります。 Bonnie ++は、Unixライクなシステムで最も人気のあるストレージパフォーマンスベンチマークです。システム全体のテスト(CPU、メモリ、およびストレージ)については、DBのパフォーマンスほど代表的なものはありません。したがって、新しいシステムでの基本的なパフォーマンステストは、TCP-Bに基づく公式のPostgreSQLベンチマークスイートであるpgbenchを実行することになります。
pgbenchの使用を開始するのはかなり簡単です。あなたがしなければならないのは、次のとおりです。
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$結果を評価および比較したい重要な変更があった場合は、常にpgbenchに相談する必要があります。
システムの展開、自動化、監視
運用を開始したら、主要なシステムコンポーネントを文書化して再現可能にし、サービスと定期的なタスクを作成するための自動化された手順を用意し、継続的な監視を実行するためのツールを用意することが非常に重要です。
ヒント3
高度なエンタープライズ機能をすべて備えたPostgreSQLの使用を開始する便利な方法の1つは、SevereninesによるClusterControlです。数回クリックするだけで、エンタープライズクラスのPostgreSQLクラスターを作成できます。 ClusterControlは、前述のすべてのサービスとその他多くのサービスを提供します。 ClusterControlの設定は非常に簡単で、公式ドキュメントの指示に従うだけです。システムを準備し(通常、CCを実行するために1つ、基本的なセットアップのためにPostgreSQL用に1つ)、SSHセットアップを完了したら、基本的なパラメーター(IP、ポート番号など)を入力する必要があります。すべてがうまくいけば、次のような出力を参照してください:
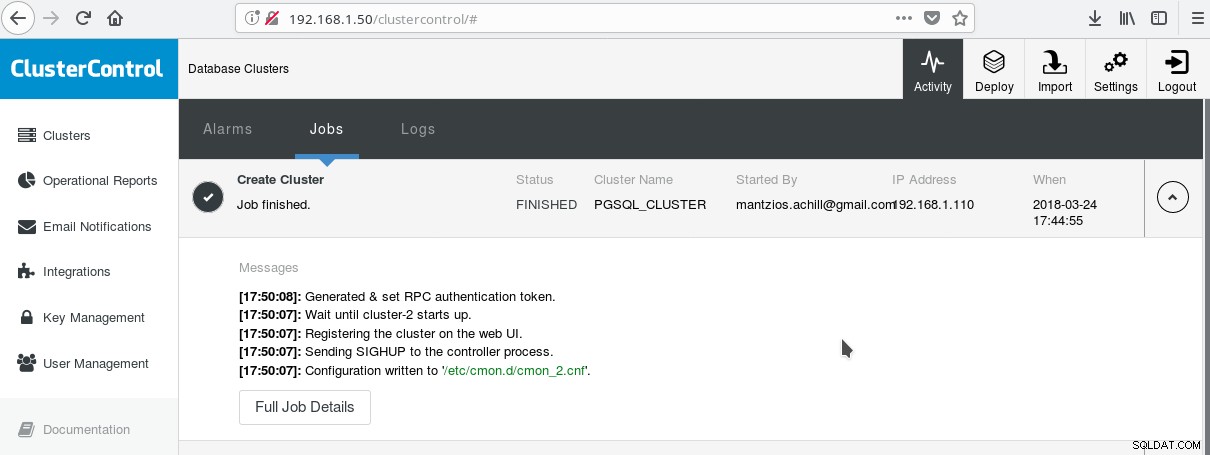
そして、メインクラスター画面で:
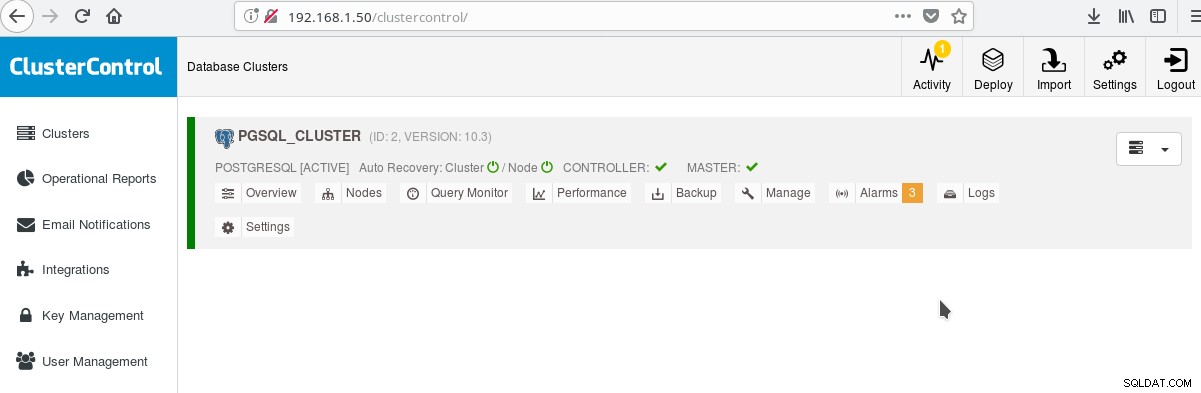
マスターサーバーにログインして、スキーマの作成を開始できます。もちろん、作成したばかりのクラスターをベースとして使用して、インフラストラクチャ(トポロジ)をさらに構築することもできます。一般的に良いアイデアは、作成したばかりの新しいサーバーに基づいてクローンとスタンバイ(スレーブ)の作成を開始する前に、PostgreSQLサーバーとユーザー/アプリデータベースで安定したサーバーファイルシステムレイアウトと最終構成を用意することです。
PostgreSQLのレイアウト、パラメータ、設定
クラスタの初期化フェーズで最も重要な決定は、データページでデータチェックサムを使用するかどうかです。大切な(将来の)データに対して最大限のデータの安全性が必要な場合は、今がその時です。将来この機能が必要になる可能性があり、この段階でそれを怠った場合、後で変更することはできません(pg_dump / pg_restoreがない場合)。これが次のヒントです:
ヒント4
データチェックサムを有効にするには、次のようにinitdbを実行します。
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>これは、上記のヒント3の時点で実行する必要があることに注意してください。 ClusterControlを使用してクラスターを既に作成している場合は、pg_createclusterを手動で再実行する必要があります。これを書いている時点では、システムまたはCCにこのオプションを含めるように指示する方法はありません。
本番環境に入る前のもう1つの非常に重要なステップは、サーバーファイルシステムのレイアウトを計画することです。最近のほとんどのLinuxディストリビューション(少なくともDebianベースのディストリビューション)はすべてを/にマウントしますが、PostgreSQLでは通常それは望ましくありません。表領域を別々のボリュームに配置し、1つのボリュームをWALファイル専用にし、別のボリュームをpgログ専用にすることは有益です。ただし、最も重要なのは、WALを独自のディスクに移動することです。これにより、次のヒントに進みます。
ヒント5
DebianStretch上のPostgreSQL10では、次のコマンドを使用してWALを新しいディスクに移動できます(新しいディスクの名前が/ dev / sdbであると仮定します):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlデータベースのロケールとエンコーディングを正しく設定することは非常に重要です。 これをcreatedbフェーズで見落とすと、アプリ/ DBがi18n、l10nの領域に移動するため、これを心から後悔することになります。次のヒントは、その方法を示しています。
ヒント6
公式ドキュメントを読んで、COLLATEとCTYPE(createdb --locale =)の設定(並べ替え順序と文字分類を担当)、およびcharset(createdb --encoding =)の設定を決定する必要があります。エンコーディングとしてUTF8を指定すると、データベースで多言語テキストを保存できるようになります。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするPostgreSQLの高可用性
PostgreSQL 9.0以降、ストリーミングレプリケーションが標準機能になると、1つ以上の読み取り専用ホットスタンバイを使用できるようになり、読み取り専用トラフィックを使用可能な任意のスレーブに転送できるようになりました。マルチマスターレプリケーションの新しい計画が存在しますが、この記事の執筆時点(10.3)では、少なくとも公式のオープンソース製品では、読み取り/書き込みマスターを1つしか持つことができません。これを正確に扱う次のヒントについて。
ヒント7
ヒント3で作成したClusterControlPGSQL_CLUSTERを使用します。最初に、読み取り専用スレーブ(PostgreSQL用語ではホットスタンバイ)として機能する2番目のマシンを作成します。次に、[レプリケーションスレーブの追加]をクリックして、マスターと新しいスレーブを選択します。ジョブが終了すると、次の出力が表示されます。
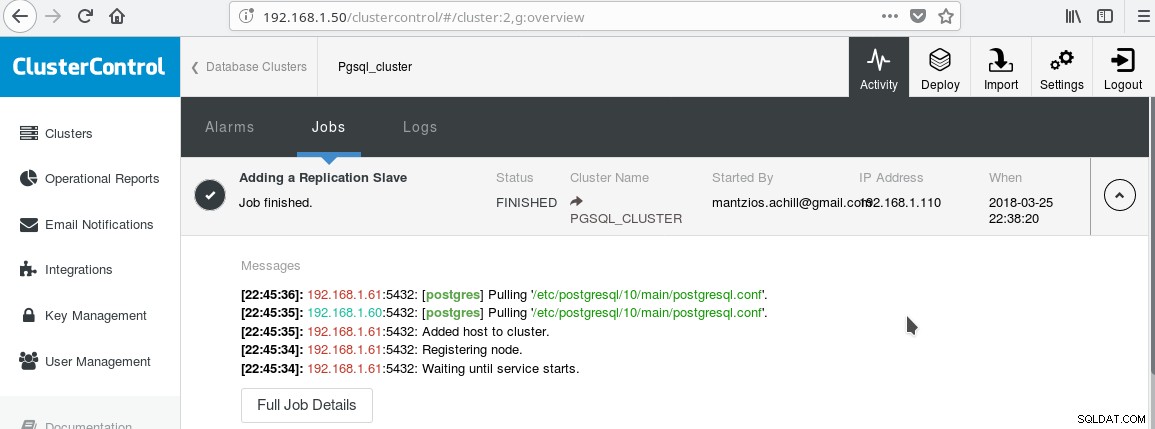
これで、クラスターは次のようになります。
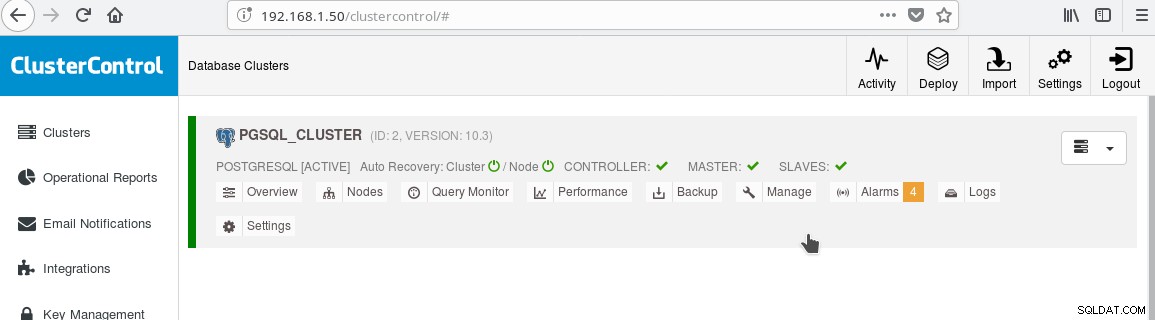
「MASTER」の横にある「SLAVES」ラベルの緑色の「チェックマーク」アイコンに注意してください。データベースオブジェクト(データベース、テーブルなど)を作成するか、マスターのテーブルにいくつかの行を挿入してスタンバイで変更を確認することにより、ストリーミングレプリケーションが機能することを確認できます。
読み取り専用スタンバイの存在により、使用可能な2つのサーバー(マスターとスレーブ)間で選択専用クエリを実行するクライアントの負荷分散を実行できます。これでヒント8に進みます。
ヒント8
HAProxyを使用して、2つのサーバー間の負荷分散を有効にできます。 ClusterControlを使用すると、これを行うのはかなり簡単です。 [管理]->[ロードバランサー]をクリックします。 HAProxyサーバーを選択すると、ClusterControlはすべてをインストールします。指定したすべてのインスタンスにxinetdをインストールし、HAProxy指定サーバーにHAProxyをインストールします。ジョブが正常に完了すると、次のように表示されます。
SLAVESの横にあるHAPROXYの緑色のチェックマークに注意してください。これで、HAProxyが機能することをテストできます:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#ヒント9
HAと負荷分散の構成に加えて、PostgreSQLサーバーの前に何らかの接続プールを配置することは常に有益です。 PgpoolとPgbouncerは、PostgreSQLコミュニティからの2つのプロジェクトです。多くのエンタープライズアプリケーションサーバーは、独自のプールも提供します。 Pgbouncerは、そのシンプルさ、速度、および「トランザクションプーリング」機能により非常に人気があります。これにより、トランザクションが終了するとサーバーへの接続が解放され、同じセッションまたは別のセッションからの後続のトランザクションで再利用できるようになります。 。トランザクションプーリング設定は、一部のセッションプーリング機能を壊しますが、一般に、「トランザクションプーリング」対応のセットアップへの変換は簡単であり、一般的な場合、短所はそれほど重要ではありません。一般的な設定は、半永続的な接続を使用してアプリサーバーのプールを構成することです。ユーザーごとまたはアプリごと(pgbouncerに接続する)の接続プールがかなり大きくなり、アイドルタイムアウトが長くなります。このように、アプリからの接続時間は最小限に抑えられますが、pgbouncerはサーバーへの接続を可能な限り少なくするのに役立ちます。
PostgreSQLを使い始めたら、おそらく気になることの1つは、遅いクエリを理解して修正することです。 pg_stat_statementsなどの以前のブログで言及した監視ツールやClusterControlなどのツールの画面は、遅いクエリを修正するためのアイデアを特定し、場合によっては提案するのに役立ちます。ただし、遅いクエリを特定したら、クエリプランに含まれるコストと時間を正確に確認するために、EXPLAINまたはEXPLAINANALYZEを実行する必要があります。次のヒントは、それを行うための非常に便利なツールについてです。
ヒント10
データベースでEXPLAINANALYZEを実行してから、出力をコピーしてdepeszのexplainanalyzeオンラインツールに貼り付けて[送信]をクリックする必要があります。次に、HTML、TEXT、STATSの3つのタブが表示されます。 HTMLには、プラン内のすべてのノードのコスト、時間、およびループの数が含まれています。 [STATS]タブには、ノードタイプごとの統計が表示されます。 「クエリの%」列を確認して、クエリが正確にどこに影響を与えているかを確認する必要があります。
PostgreSQLに慣れるにつれて、自分でさらに多くのヒントを見つけることができます!