そして今、OracleからPostgreSQLシリーズへの移行の2番目の記事に到達しました。今回は、START WITH/CONNECT BYを見ていきます。 構築します。
Oracleでは、START WITH/CONNECT BY 特定の番兵行から始まる単一リンクリスト構造を作成するために使用されます。リンクリストはツリーの形式をとることができ、バランスの要件はありません。
説明のために、クエリから始めて、テーブルに5行あると仮定します。
SELECT * FROM person;
last_name | first_name | id | parent_id
------------+------------+----+-----------
Dunstan | Andrew | 1 | (null)
Roybal | Kirk | 2 | 1
Riggs | Simon | 3 | 1
Eisentraut | Peter | 4 | 1
Thomas | Shaun | 5 | 3
(5 rows)Oracle構文を使用したテーブルの階層クエリは次のとおりです。
select id, parent_id
from person
start with parent_id IS NULL
connect by prior id = parent_id;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3そしてここでもPostgreSQLを使用しています。
WITH RECURSIVE a AS (
SELECT id, parent_id
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT id, parent_id FROM a;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3
(5 rows)このクエリは多くのPostgreSQL機能を利用しているので、ゆっくりと見ていきましょう。
WITH RECURSIVE
これは「共通テーブル式」(CTE)です。これは、同じトランザクションだけでなく、同じステートメントで実行される一連のクエリを定義します。括弧で囲まれた式はいくつでもあり、最後のステートメントがあります。この使用法では、1つだけ必要です。そのステートメントをRECURSIVEであると宣言する 、行が返されなくなるまで繰り返し実行されます。
SELECT
UNION ALL
SELECTこれは、再帰クエリの規定のフレーズです。これは、開始点と再帰アルゴリズムを区別するための方法としてドキュメントで定義されています。 Oracleの用語では、これらはCONNECTBY句に結合されたSTARTWITH句と考えることができます。
JOIN a ON a.id = d.parent_idこれは、前の行データを次の反復に提供するCTEステートメントへの自己結合です。
これがどのように機能するかを説明するために、クエリに反復インジケーターを追加しましょう。
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT * FROM a;
id | parent_id | recursion_level
----+-----------+-----------------
1 | (null) | 1
4 | 1 | 2
3 | 1 | 2
2 | 1 | 2
5 | 3 | 3
(5 rows)再帰レベルインジケーターを値で初期化します。返される行では、最初の再帰レベルが1回だけ発生することに注意してください。これは、最初の句が1回だけ実行されるためです。
2番目の節は、反復的な魔法が発生する場所です。ここでは、現在の行データとともに、前の行データを表示できます。これにより、再帰的な計算を実行できます。
Simon Riggsが、この機能をグラフデータベースの設計に使用する方法についての非常に優れたビデオを公開しています。非常に有益なので、ご覧になる必要があります。

このクエリが循環状態につながる可能性があることに気付いたかもしれません。それは正しいです。この無限の再帰を防ぐために、2番目のクエリに制限句を追加するのは開発者の責任です。たとえば、あきらめる前に4レベルだけ繰り返します。
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level --<-- initialize it here
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1 --<-- iteration increment
FROM person d
JOIN a ON a.id = d.parent_id
WHERE d.recursion_level <= 4 --<-- bail out here
) SELECT * FROM a;
列名とデータ型は、最初の句によって決定されます。この例では、再帰レベルにキャスト演算子を使用していることに注意してください。非常に深いグラフでは、このデータ型は1::bigint recursion_levelとして定義することもできます。 。
このグラフは、小さなシェルスクリプトとgraphvizユーティリティを使用して非常に簡単に視覚化できます。
#!/bin/bash -
#===============================================================================
#
# FILE: pggraph
#
# USAGE: ./pggraph
#
# DESCRIPTION:
#
# OPTIONS: ---
# REQUIREMENTS: ---
# BUGS: ---
# NOTES: ---
# AUTHOR: Kirk Roybal (), example@sqldat.com
# ORGANIZATION:
# CREATED: 04/21/2020 14:09
# REVISION: ---
#===============================================================================
set -o nounset # Treat unset variables as an error
dbhost=localhost
dbport=5432
dbuser=$USER
dbname=$USER
ScriptVersion="1.0"
output=$(basename $0).dot
#=== FUNCTION ================================================================
# NAME: usage
# DESCRIPTION: Display usage information.
#===============================================================================
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] [--]
Options:
-h|host name Database Host Name default:localhost
-n|name name Database Name default:$USER
-o|output file Output file default:$output.dot
-p|port number TCP/IP port default:5432
-u|user name User name default:$USER
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
while getopts ":dh:n:o:p:u:v" opt
do
case $opt in
d|debug ) set -x ;;
h|host ) dbhost="$OPTARG" ;;
n|name ) dbname="$OPTARG" ;;
o|output ) output="$OPTARG" ;;
p|port ) dbport=$OPTARG ;;
u|user ) dbuser=$OPTARG ;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))
[[ -f "$output" ]] && rm "$output"
tee "$output" <<eof< span="">
digraph g {
node [shape=rectangle]
rankdir=LR
EOF
psql -h $dbhost -U $dbuser -d $dbname -p $dbport -qtAf cte.sql |
sed -e 's/^/node/' -e 's/.*(null)|/node/' -e 's/^/\t/' -e 's/|[[:digit:]]*$//' |
sed -e 's/|/ -> node/' | tee -a "$output"
tee -a "$output" <<eof< span="">
}
EOF
dot -Tpng "$output" > "${output/dot/png}"
[[ -f "$output" ]] && rm "$output"
open "${output/dot/png}"</eof<></eof<>このスクリプトでは、cte.sql
というファイルにこのSQLステートメントが必要です。WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT parent_id, id, recursion_level FROM a;次に、次のように呼び出します:
chmod +x pggraph
./pggraphそして、結果のグラフが表示されます。

INSERT INTO person (id, parent_id) VALUES (6,2);ユーティリティを再度実行して、有向グラフへの即時の変更を確認します。

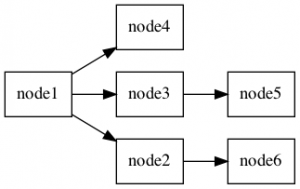
さて、それは今ではそれほど難しくありませんでしたね?