データベーストポロジでロードバランサーを使用する利点については、何度も説明しました。トラフィックを正常なデータベースノードにリダイレクトしたり、トラフィックを複数のサーバーに分散してパフォーマンスを向上させたり、アプリケーションで単一のエンドポイントを構成して構成とフェイルオーバーのプロセスを容易にしたりする場合があります。
新しいClusterControl1.7.6バージョンでは、PostgreSQLクラスターをクラウドに直接デプロイできるだけでなく、同じジョブにロードバランサーをデプロイすることもできます。このため、ClusterControlは、クラウドプロバイダーとしてAWS、Google Cloud、Azureをサポートしています。この新機能を見てみましょう。
この例では、サポートされているクラウドプロバイダーのいずれかでアカウントを持っており、ClusterControl1.7.6インストールで資格情報を構成していることを前提としています。
構成していない場合は、ClusterControl->統合->クラウドプロバイダー->クラウドクレデンシャルの追加に移動する必要があります。

ここでは、クラウドプロバイダーを選択し、対応する情報を追加する必要があります。
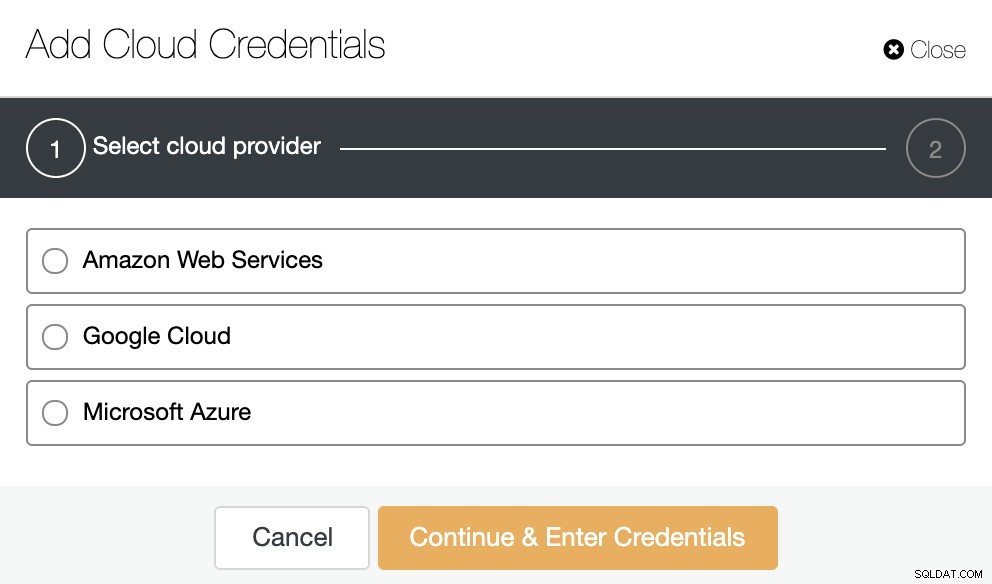
この情報は、クラウドプロバイダー自体によって異なります。詳細については、公式ドキュメントを確認してください。
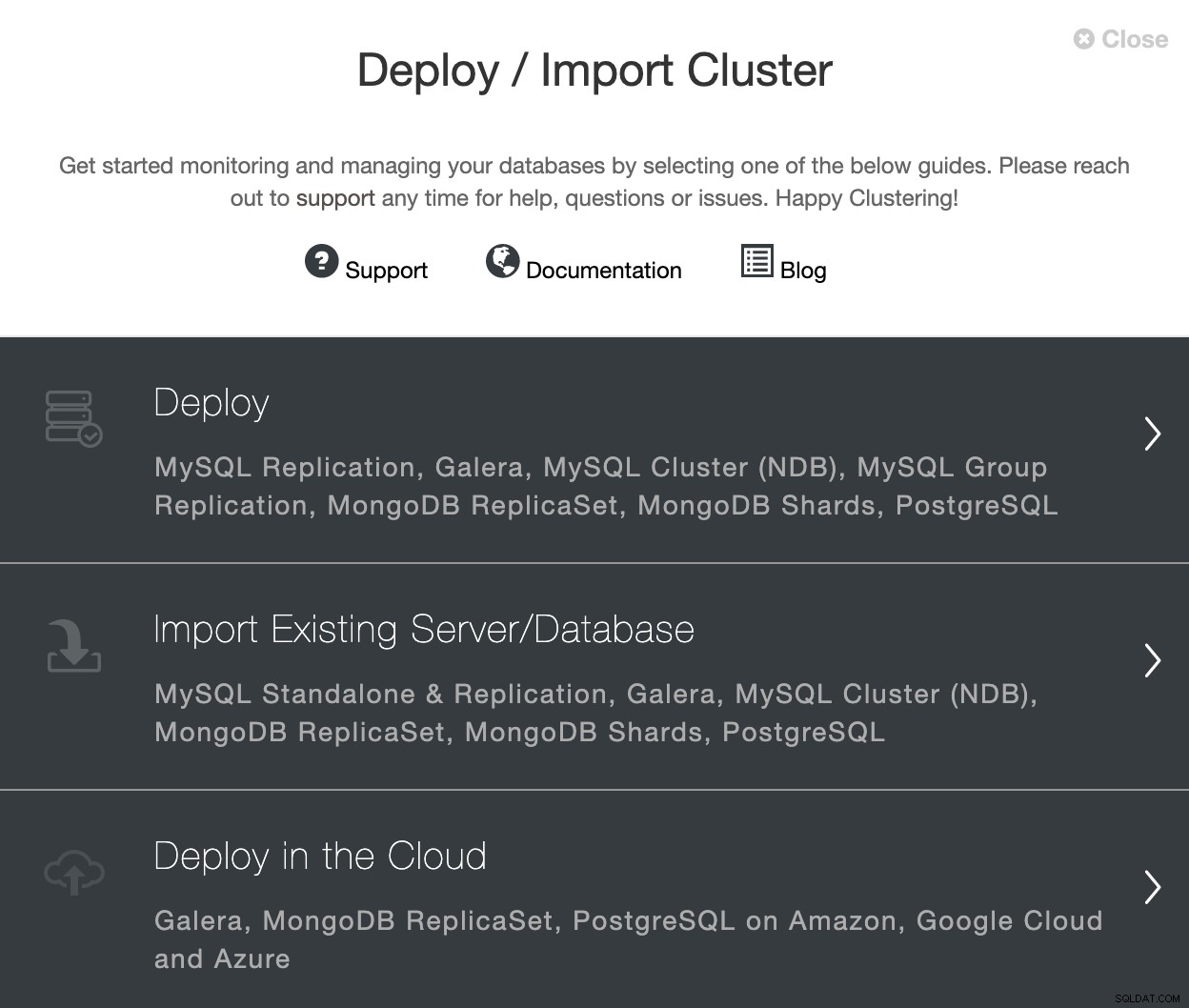
何かを作成するためにクラウドプロバイダー管理コンソールにアクセスする必要はありません。仮想マシン、データベース、ロードバランサーをClusterControlから直接デプロイできます。デプロイセクションに移動し、[クラウドにデプロイ]を選択します。
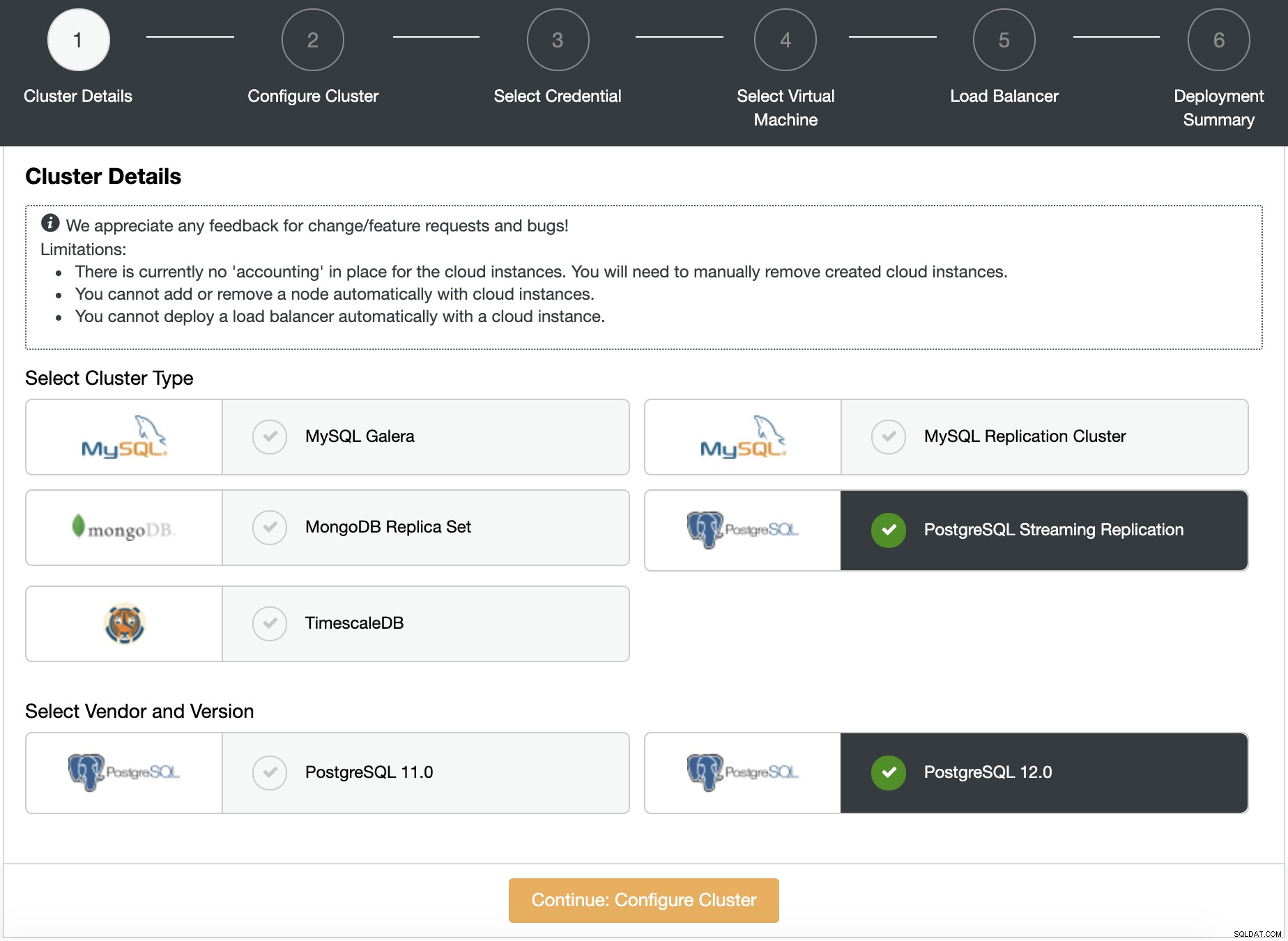
新しいデータベースクラスターのベンダーとバージョンを指定します。この場合、PostgreSQL12を使用します。
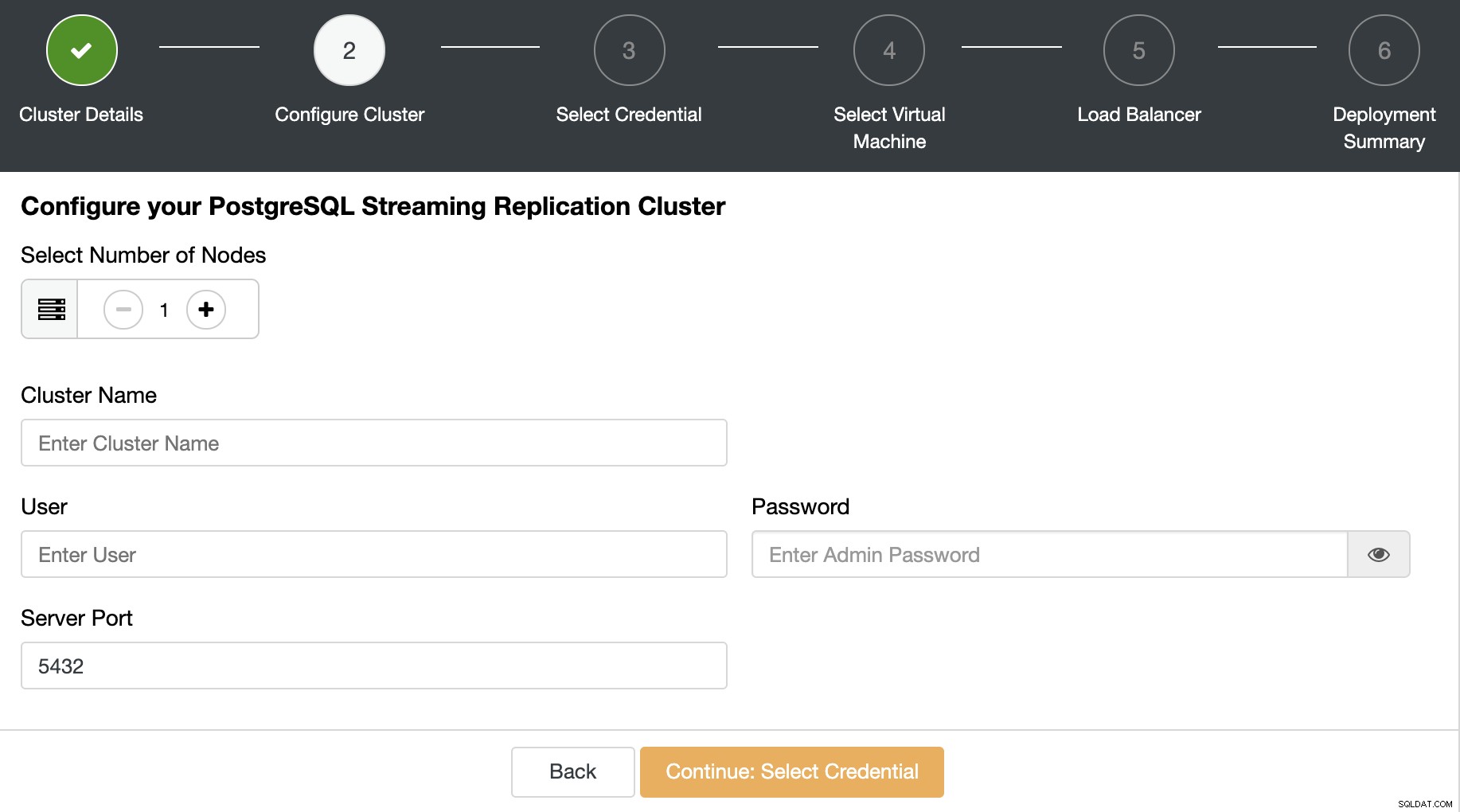
ノード数、クラスター名、資格情報などのデータベース情報を追加し、サーバーポート。
クラウドのクレデンシャルを選択します。この場合は、AWSを使用しますアカウント。まだClusterControlにアカウントを追加していない場合は、このタスクのドキュメントに従うことができます。
次に、オペレーティングシステム、サイズ、および地域。
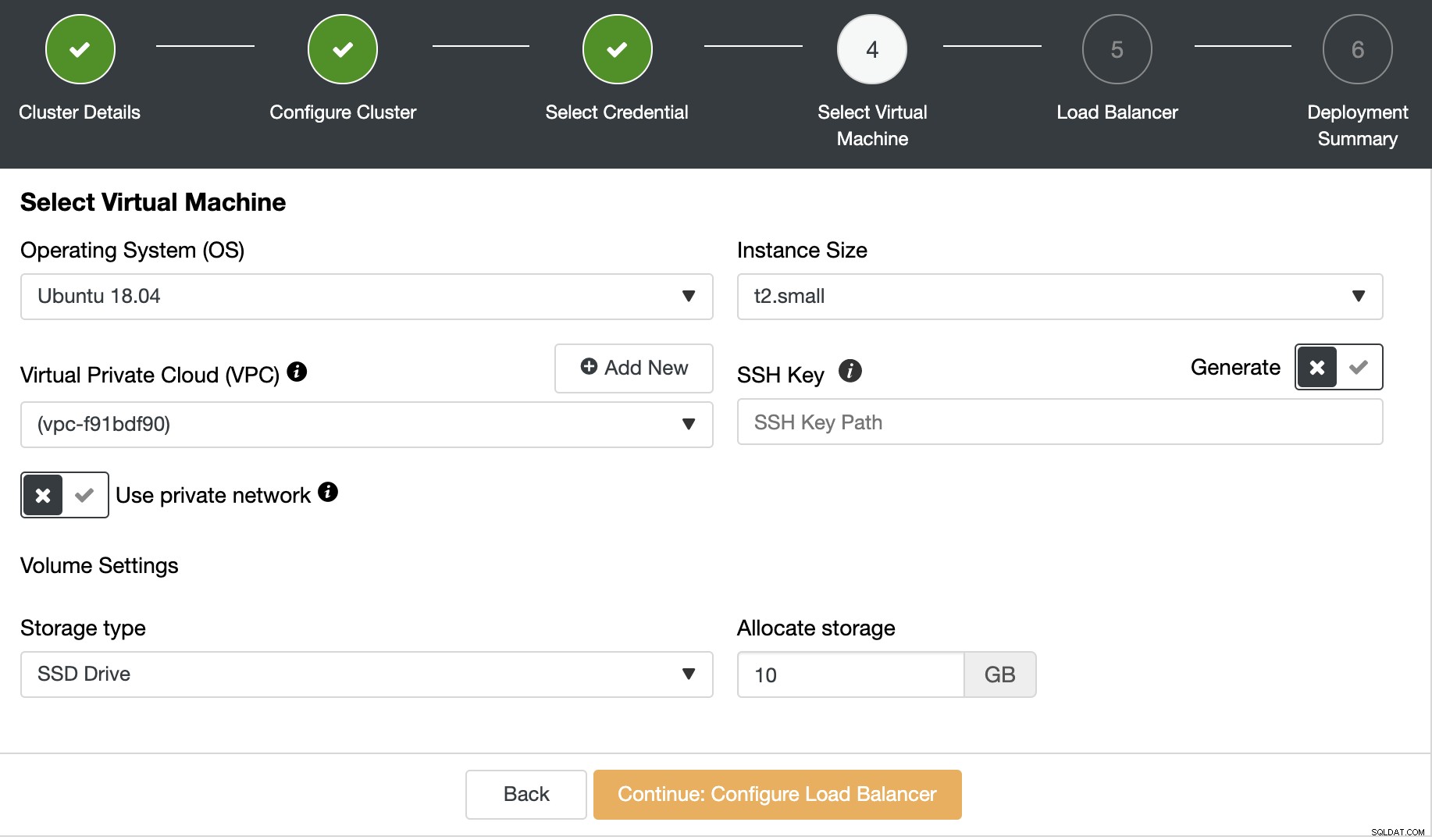
次のステップでは、データベースクラスターにロードバランサーを追加できます。 PostgreSQLの場合、ClusterControlはロードバランサーとしてHAProxyをサポートします。ロードバランサーノードの数、インスタンスサイズ、およびロードバランサー情報を選択する必要があります。
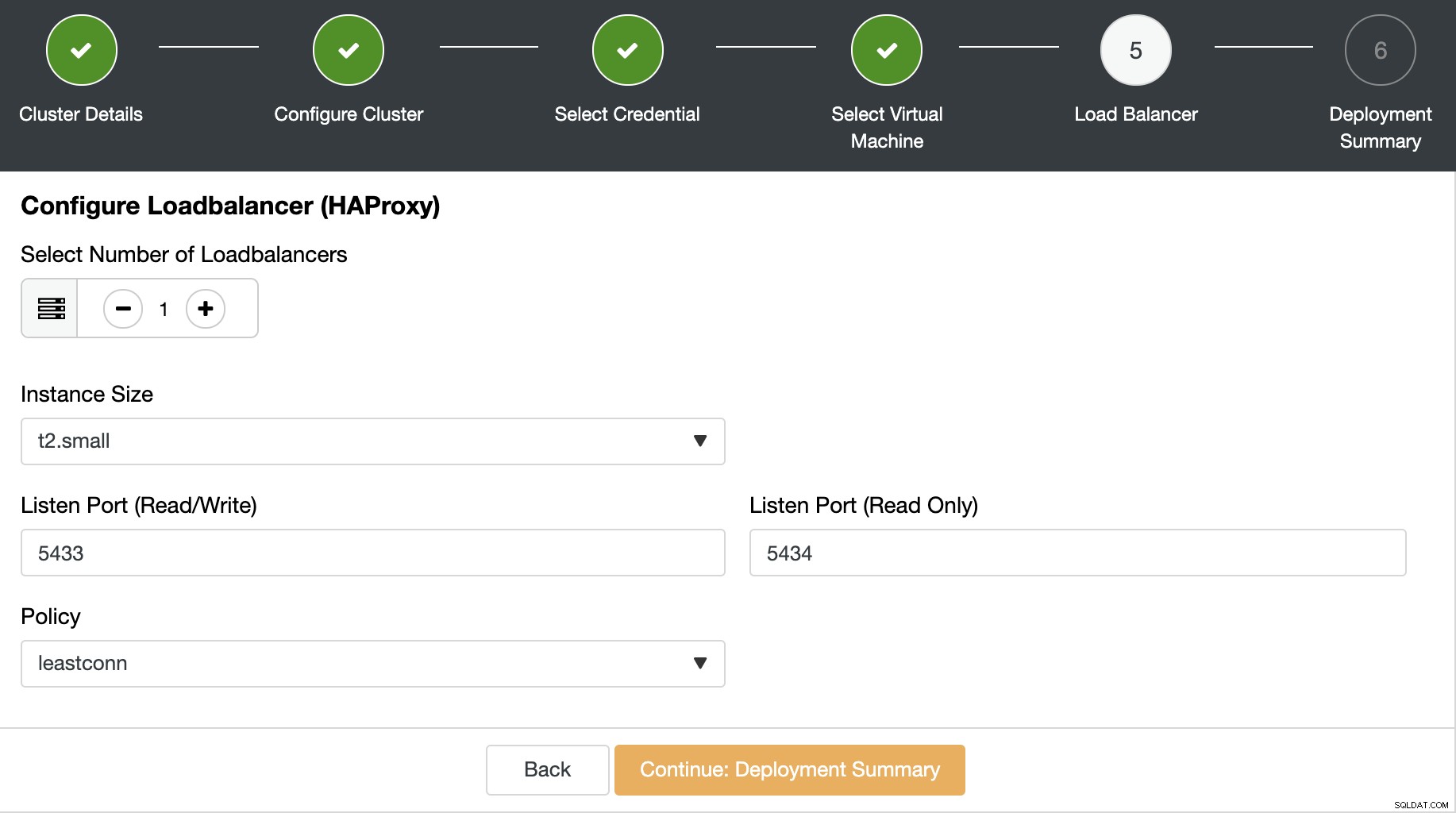
このロードバランサーの情報は次のとおりです。
- リッスンポート(読み取り/書き込み):読み取り/書き込みトラフィック用のポート。
- リッスンポート(読み取り専用):読み取り専用トラフィック用のポート。
- ポリシー:次のようになります:
- lessonconn:接続数が最も少ないサーバーが接続を受信します
- ラウンドロビン:各サーバーは、その重みに応じて順番に使用されます
- source:送信元IPアドレスがハッシュされ、実行中のサーバーの総重量で除算されて、リクエストを受信するサーバーを指定します
これで、概要を確認して展開できます。
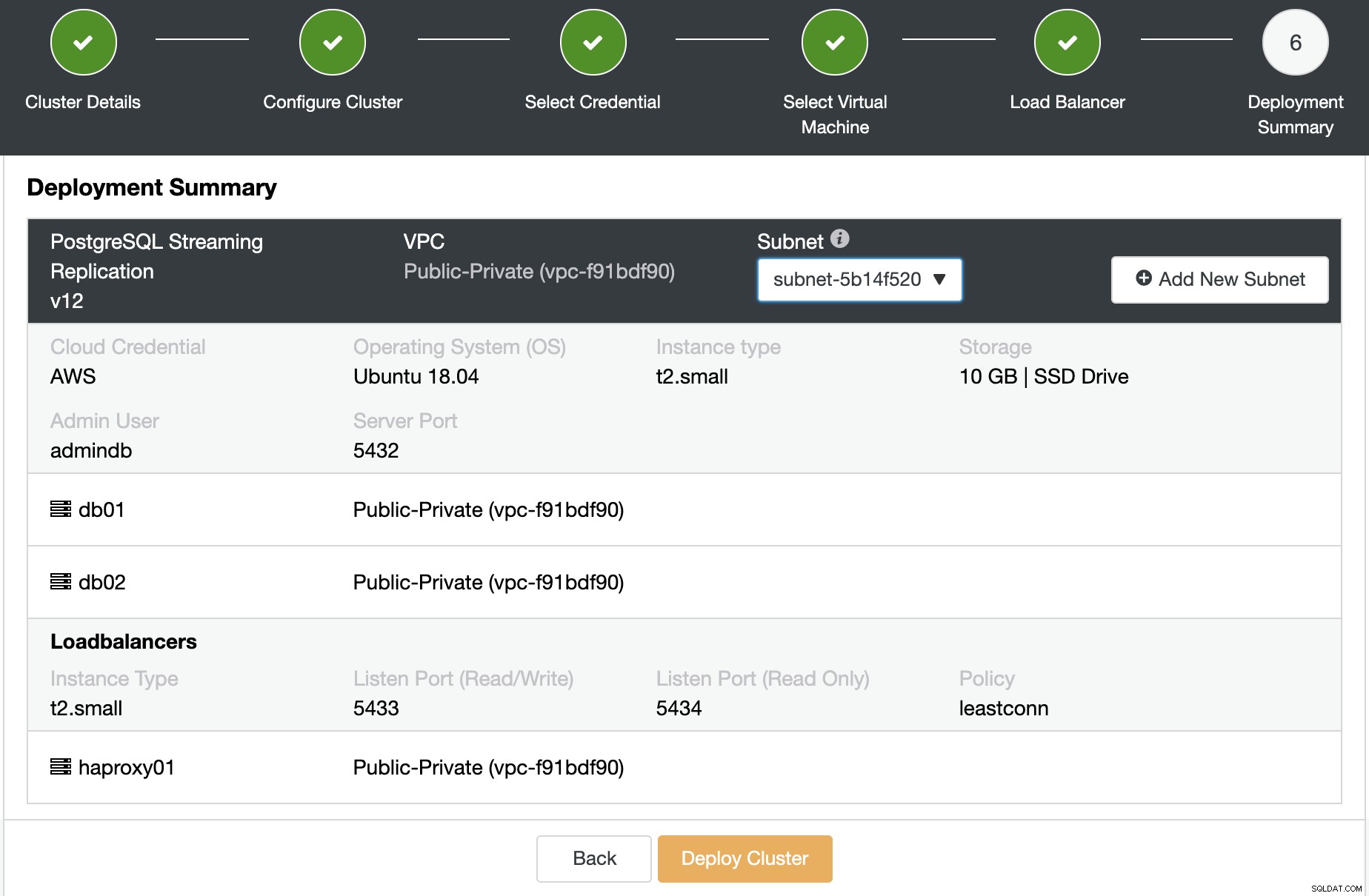
ClusterControlは仮想マシンを作成し、ソフトウェアをインストールして構成します。すべて同じ仕事で無人の方法で。
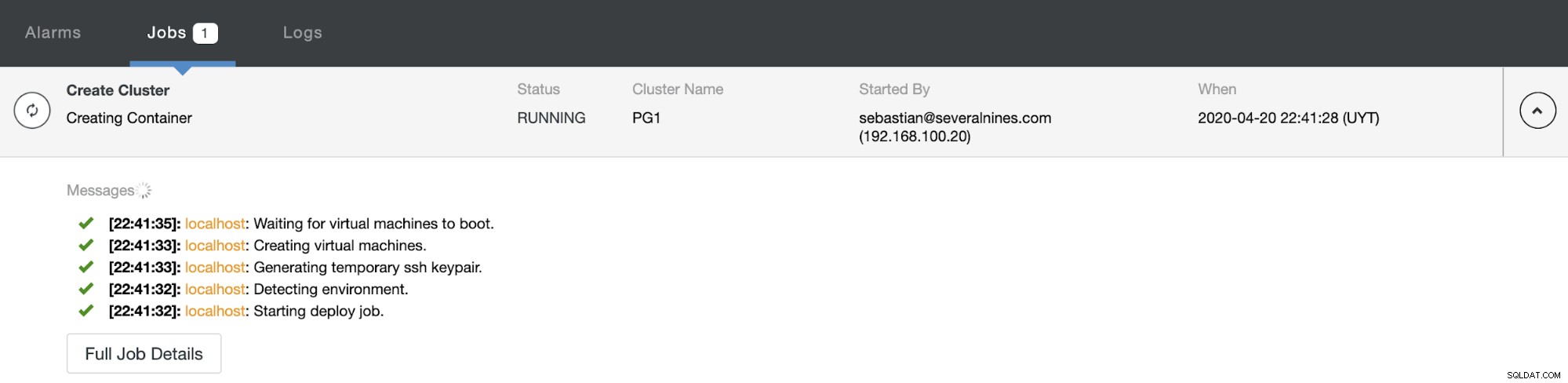
ClusterControlアクティビティセクションで作成プロセスを監視できます。完了すると、ClusterControlのメイン画面に新しいクラスターが表示されます。

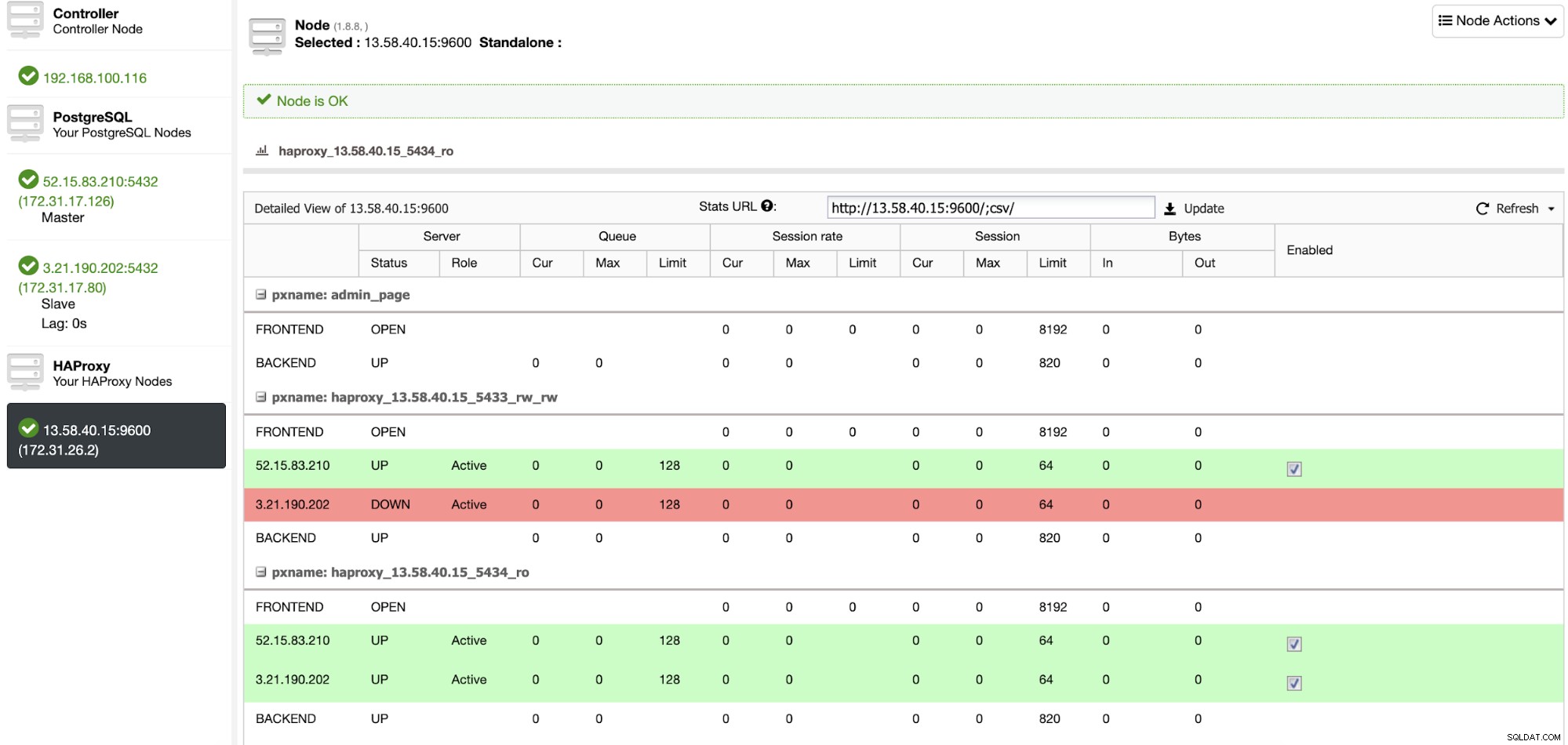
ロードバランサノードを確認する場合は、ClusterControlにアクセスできます。 ->ノード->HAProxyノード、および現在のステータスを確認します。
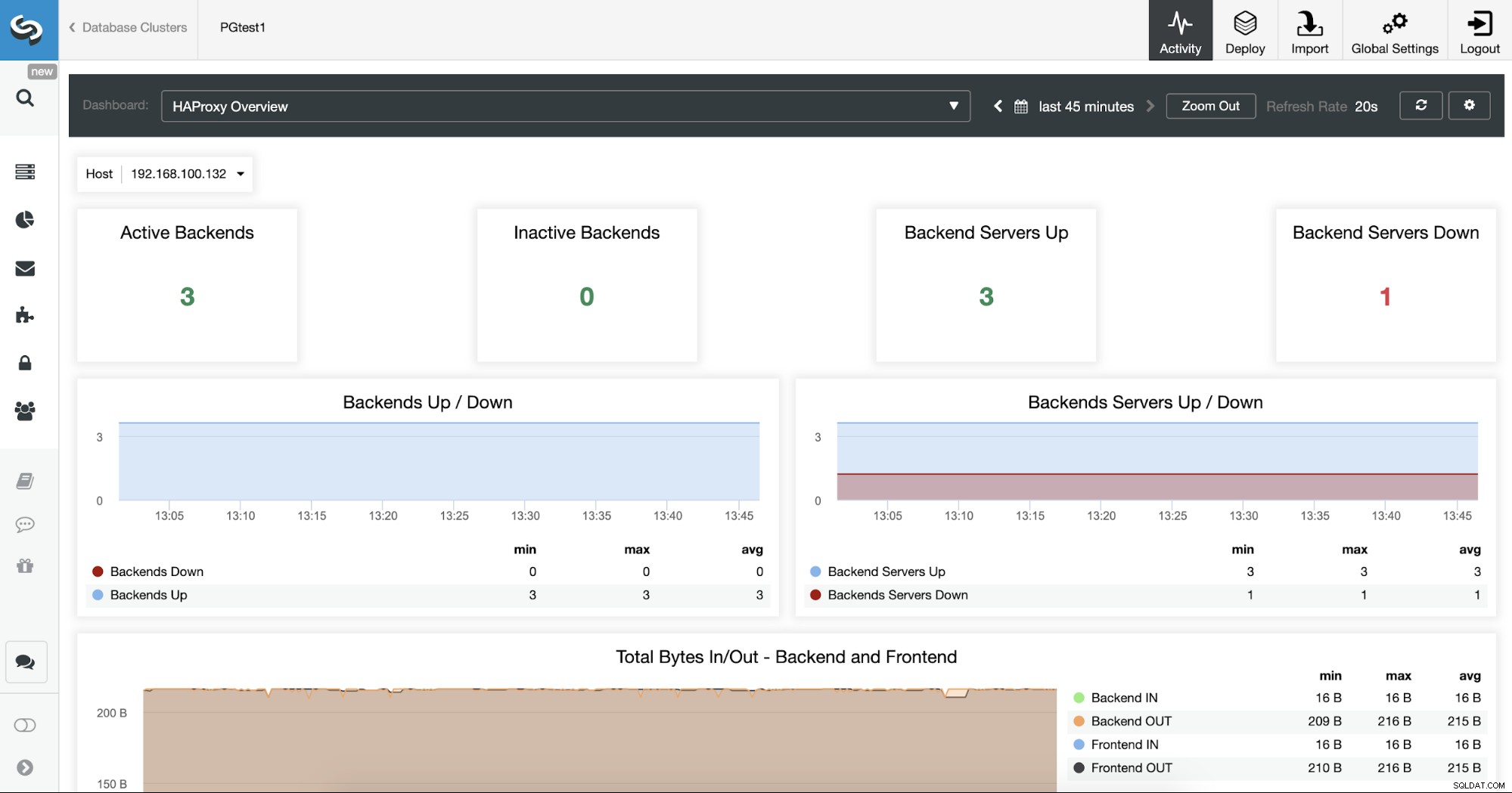
[ダッシュボード]セクションを確認して、ClusterControlからHAProxyサーバーを監視することもできます。
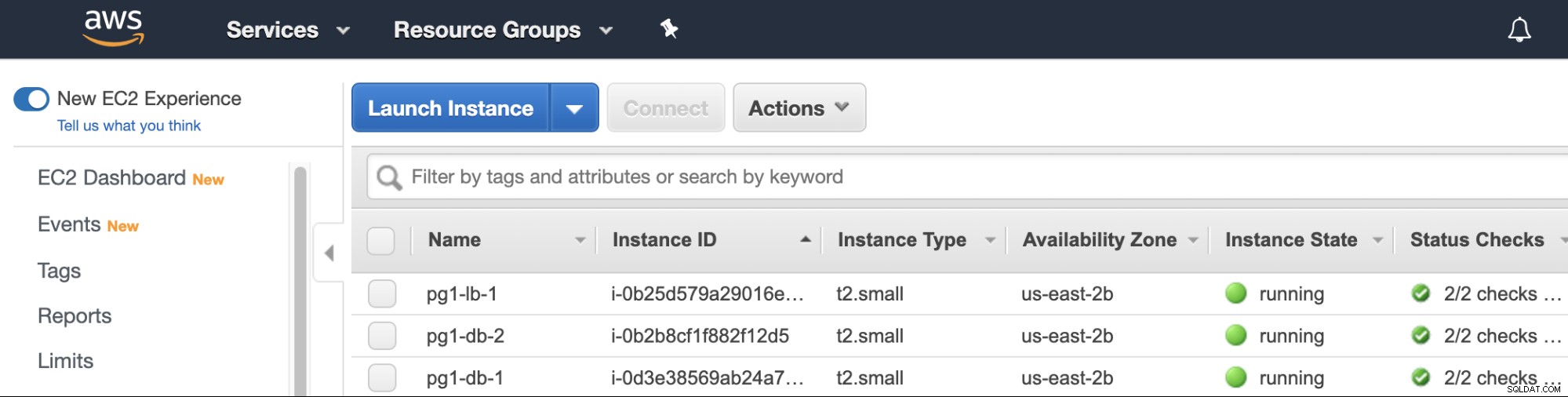
これで完了です。ここで、クラウドプロバイダー管理コンソールを確認できます。選択したClusterControlジョブオプションに従って作成された仮想マシンが見つかります。
ご覧のとおり、クラウド内のPostgreSQLクラスターの前にロードバランサーを配置するのは、データベースとロードバランサーノードを同じジョブにデプロイできる新しいClusterControl「DeployintheCloud」機能を使用すると非常に簡単です。