マルチクラウド環境はディザスタリカバリプラン(DRP)に適したオプションですが、さまざまなクラウドプロバイダー間の接続を構成する必要があるため、時間のかかる作業になる可能性があります。次に、データベースクラスターを2つの異なる場所にデプロイして管理する必要があります。
このブログでは、現時点で最も人気のある2つのクラウドプロバイダーであるAWSとGoogleCloudでPostgreSQLのマルチクラウドデプロイを実行する方法を紹介します。このタスクでは、スケーリングやクラスター間レプリケーションなど、ClusterControlが提供できるいくつかの機能を使用します。
ClusterControlのインストールが実行されており、2つの異なるクラウドプロバイダーアカウントがすでに作成されていることを前提としています。
まず、メインのクラウドプロバイダーで環境を作成する必要があります。この場合、2つのPostgreSQLノードでAWSを使用します:

ClusterControlサーバーからのSSHおよびPostgreSQLトラフィックが許可されていることを確認してください。セキュリティグループの編集:

次に、セカンダリクラウドプロバイダーに移動して、少なくとも1つの仮想マシンを作成しますそれがスレーブノードになります。 1つのPostgreSQLノードでGoogleCloudPlatformを使用します。

また、ClusterControlからのSSHおよびPostgreSQLトラフィックを許可していることを確認してくださいサーバー:

この場合、ソースに制限のないトラフィックを許可しています、ただし、これは単なる例であり、実際には推奨されていません。
このタスクにはClusterControlを使用するため、インストールされていることを前提としています。
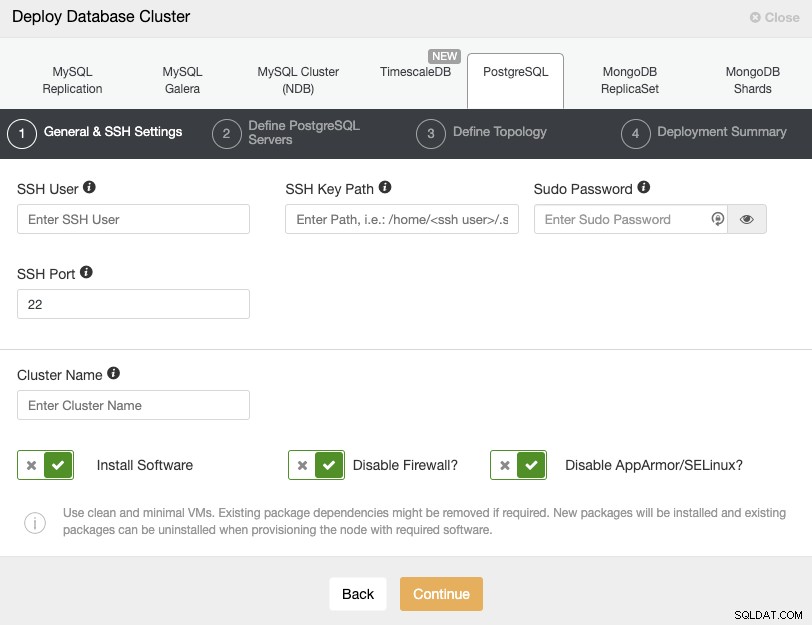
ClusterControlサーバーに移動し、[展開]オプションを選択します。すでにPostgreSQLインスタンスを実行している場合は、代わりに「既存のサーバー/データベースのインポート」を選択する必要があります。
PostgreSQLを選択するときは、ユーザー、キーまたはパスワード、およびポートを指定する必要がありますSSHでPostgreSQLノードに接続します。新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合にも必要です。
この手順の詳細については、ClusterControlのユーザー要件を確認してください。
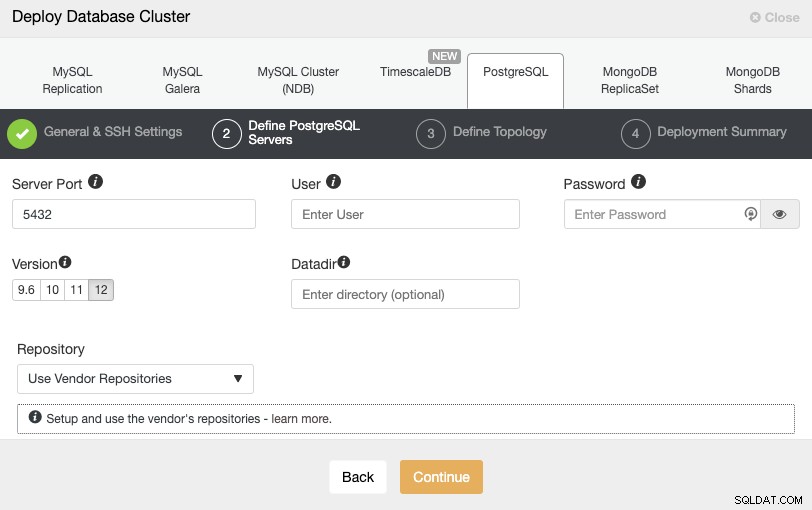
SSHアクセス情報を設定した後、データベースユーザーを定義する必要があります。 version、およびdatadir(オプション)。使用するリポジトリを指定することもできます。次のステップでは、作成するクラスターにサーバーを追加する必要があります。
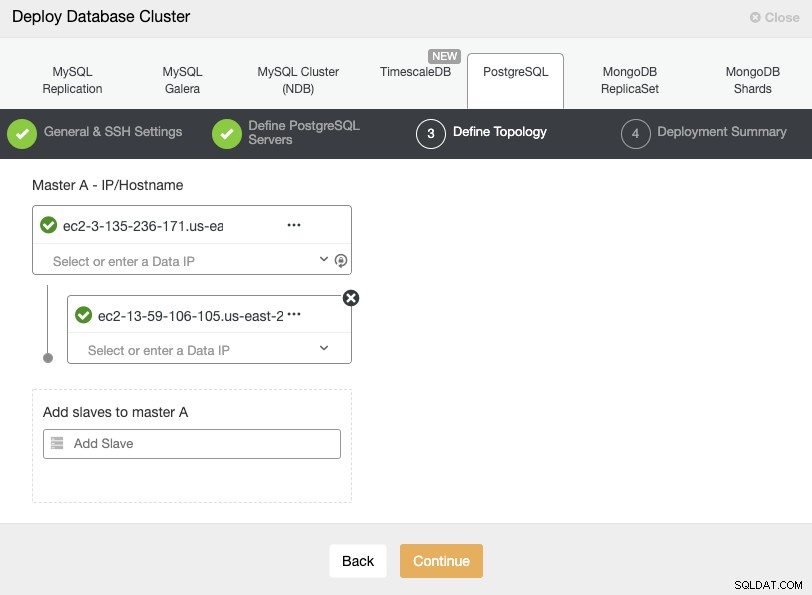
サーバーを追加するときに、IPまたはホスト名を入力できます。このステップでは、ClusterControlに使用するネットワークに関する制限がないため、セカンダリクラウドプロバイダーに配置されたノードを追加することもできますが、より明確にするために、次のセクションで追加します。ここでの唯一の要件は、ノードへのSSHアクセスが必要です。
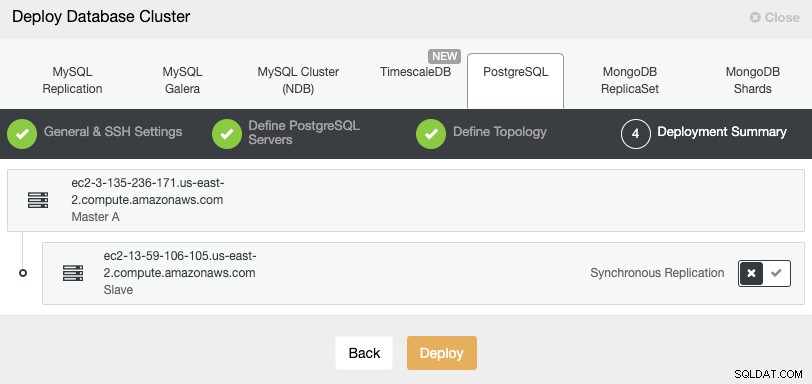
最後のステップで、レプリケーションを同期にするか、同期するかを選択できます。非同期。
ここにリモートノードを追加する場合は、非同期レプリケーションを使用することが重要です。使用しない場合、クラスターは遅延またはネットワークの問題の影響を受ける可能性があります。
ClusterControlアクティビティモニターで作成ステータスを監視できます。
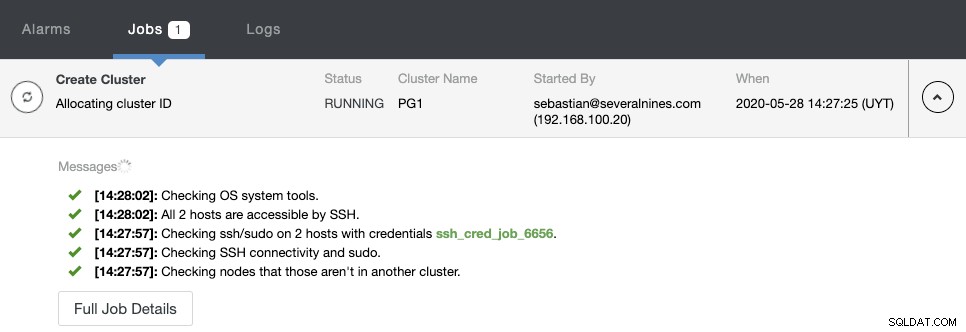
タスクが完了すると、新しいPostgreSQLクラスターがClusterControlのメイン画面。

クラスターを作成したら、ロードバランサーやレプリケーションスレーブノードのデプロイ/インポートなど、いくつかのタスクを実行できます。
クラスターアクションに移動し、[レプリケーションスレーブの追加]を選択します:
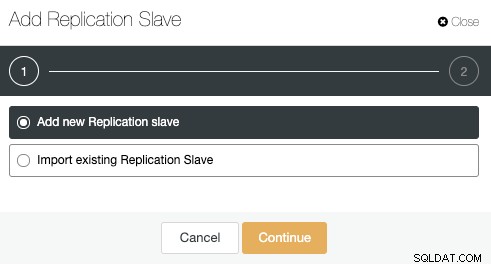
「新しいレプリケーションスレーブを追加」オプションを使用してみましょう。リモートノードは新規インストールです。そうでない場合は、代わりに[既存のレプリケーションスレーブのインポート]オプションを使用できます。
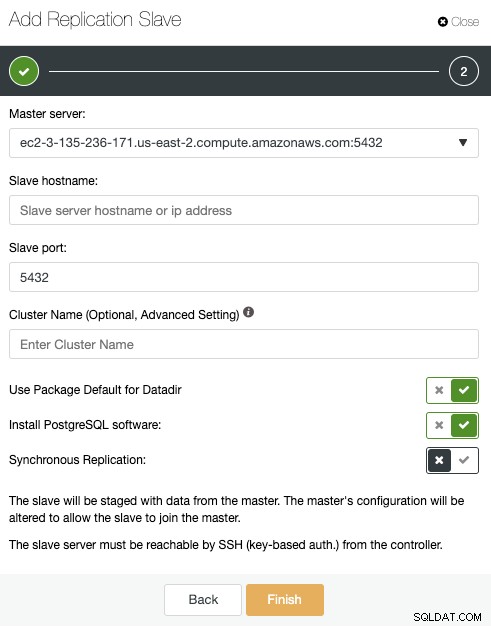
ここでは、マスターサーバーを選択するだけで、IPアドレスを入力できます新しいスレーブサーバーとデータベースポート用。次に、ClusterControlにソフトウェアをインストールするかどうか、およびレプリケーションスレーブを同期にするか非同期にするかを選択できます。繰り返しになりますが、別のデータセンターにノードを追加する場合は、ネットワークパフォーマンスに関連する問題を回避するために、非同期レプリケーションを使用する必要があります。
このようにして、必要な数のレプリカを追加し、ClusterControlで実装できるロードバランサーを使用してそれらの間で読み取りトラフィックを分散できます。
ClusterControlアクティビティモニターでレプリケーションスレーブの作成を監視できます。
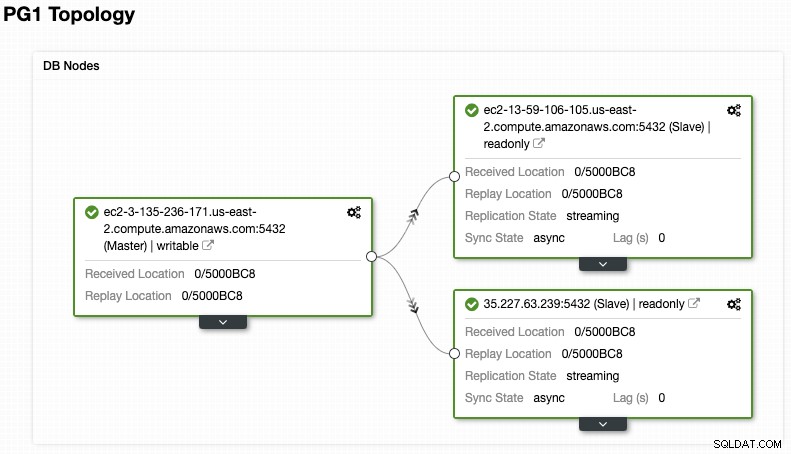
トポロジビューセクションで最終的なトポロジを確認します。
マルチクラウド環境で「レプリケーションスレーブの追加」オプションを使用する代わりに、ClusterControlクラスター間レプリケーション機能を使用してリモートクラスターを追加できます。現時点では、この機能にはPostgreSQLの制限があり、リモートノードを1つだけ持つことができるため、以前の方法と非常によく似ていますが、将来のリリースでその制限を取り除くよう取り組んでいます。
新しいスレーブクラスターを作成するには、ClusterControl->[クラスター]->[クラスターアクション]->[スレーブクラスターの作成]に移動します。
スレーブクラスターは、現在のマスタークラスターからデータをストリーミングすることによって作成されます。
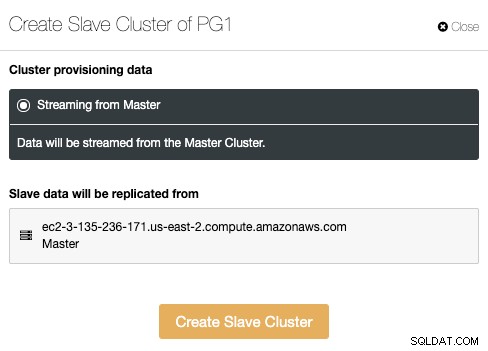
このセクションでは、現在のクラスターのマスターノードを次の場所から選択する必要があります。データが複製されます。
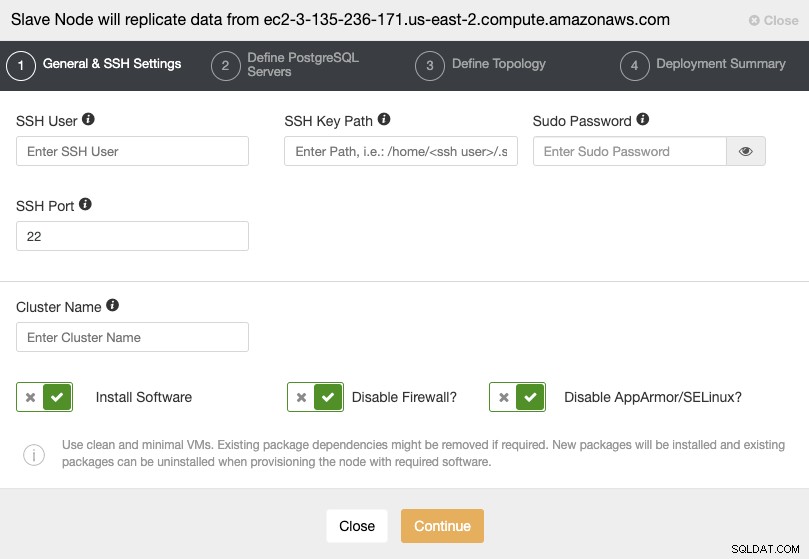
次の手順に進むときは、ユーザー、キー、またはを指定する必要がありますパスワード、およびSSHでサーバーに接続するためのポート。また、スレーブクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
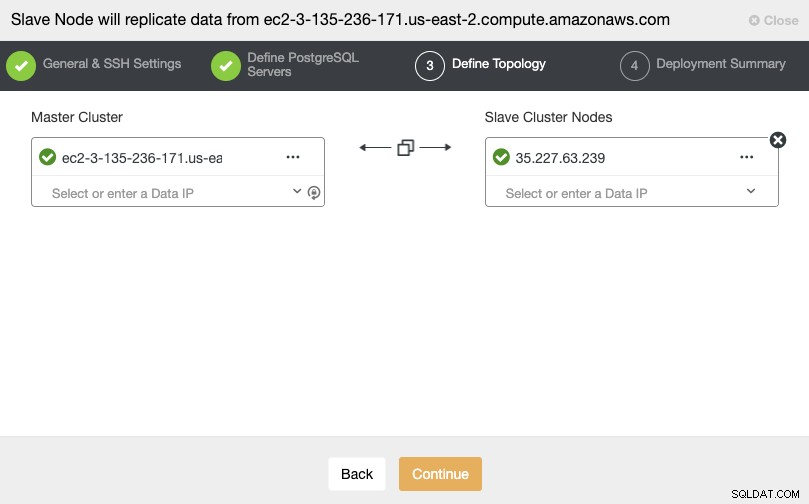
SSHアクセス情報を設定した後、データベースのバージョンを定義する必要があります。 datadir、port、およびadminの資格情報。ストリーミングレプリケーションを使用するため、マスタークラスターで使用されているものと同じデータベースバージョンと資格情報を使用していることを確認してください。使用するリポジトリを指定することもできます。
このステップでは、新しいスレーブクラスターのサーバーを追加する必要があります。このタスクでは、データベースノードのIPアドレスまたはホスト名の両方を入力できます。
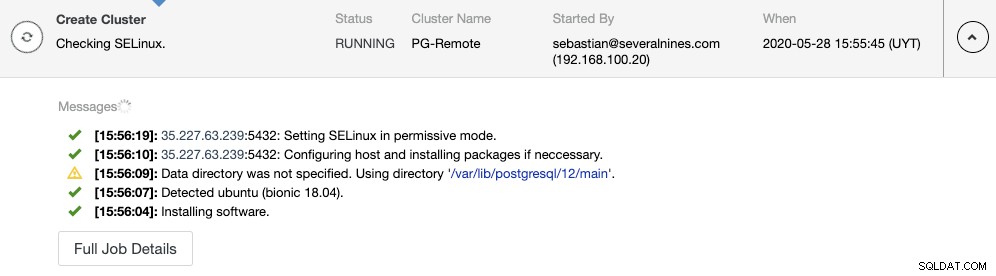
ClusterControlアクティビティモニターでスレーブクラスターの作成を監視できます。タスクが完了すると、ClusterControlのメイン画面にクラスターが表示されます。
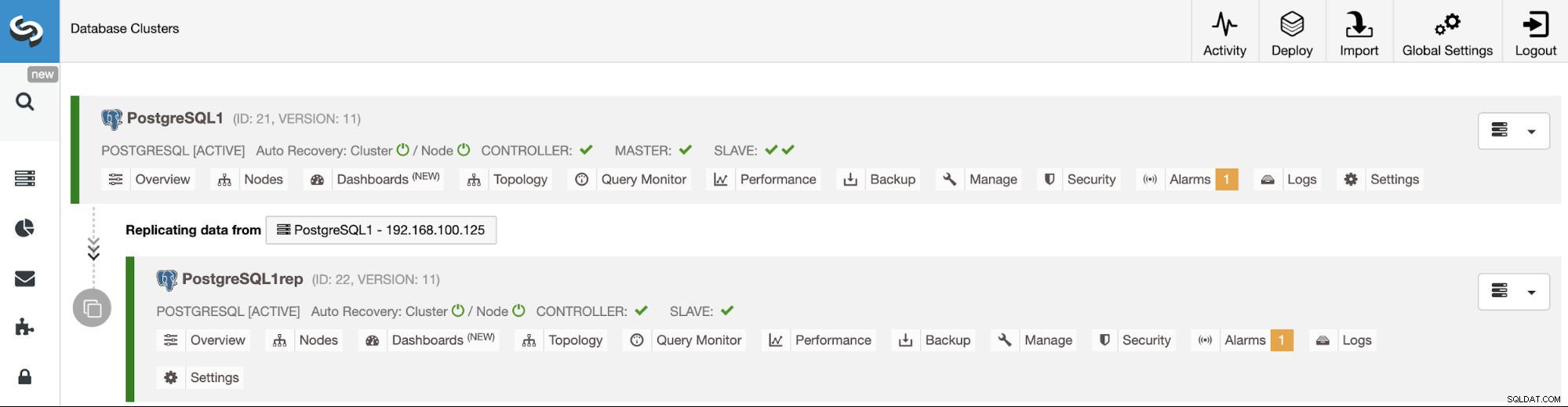
これらのClusterControl機能を使用すると、PostgreSQLデータベース(およびさまざまなテクノロジー)のさまざまなクラウドプロバイダー間でレプリケーションをすばやくセットアップし、簡単で使いやすい方法でセットアップを管理できます。クラウドプロバイダー間の通信については、セキュリティ上の理由から、既知のソースからのトラフィックのみを制限する必要があります。つまり、クラウドプロバイダー1からクラウドプロバイダー2へ、またはその逆のトラフィックのみを制限する必要があります。