スケーラビリティは、リソースを追加することで増大する需要を処理するシステムの特性です。この量の要求の理由は、たとえば、顧客または従業員の増加のために販売の割引を開始する場合、または永続的な場合など、一時的なものである可能性があります。いずれの場合も、リソースを追加または削除して、必要に応じてこれらの変更を管理したり、トラフィックを増やしたりできるはずです。
- 水平スケーリング (スケールアウト):データベースクラスターを作成または増加するデータベースノードを追加することによって実行されます。これは、ノード間のトラフィックのバランスをとる読み取りパフォーマンスを向上させるのに役立ちます。
- 垂直スケーリング (スケールアップ):既存のデータベースノードにハードウェアリソース(CPU、メモリ、ディスク)を追加することで実行されます。 PostgreSQLが新しいまたはより優れたハードウェアリソースを使用できるように、いくつかの構成パラメーターを変更する必要がある場合があります。
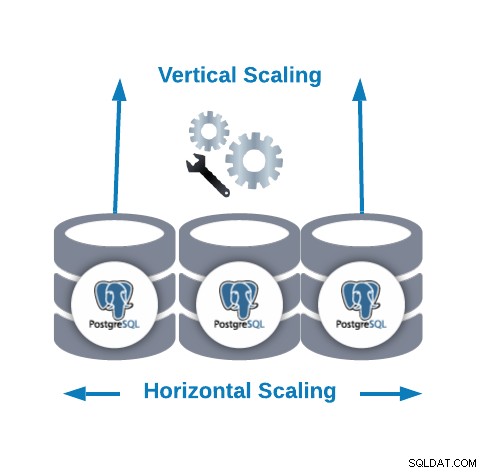
水平スケーリングと垂直スケーリングの両方で、パフォーマンスを向上させるデータベースの負荷を軽減するための外部ツールを追加すると便利な場合があります。多分それは十分ではありませんが、それは良い出発点です。このためには、接続プールとロードバランサーを実装することをお勧めします。さまざまな役割のために設計されているため、「および」と言いました。
接続プールは、接続のプールを作成して再利用する方法であり、データベースへの新しい接続を常に開かないようにします。これにより、アプリケーションのパフォーマンスが大幅に向上します。 PgBouncerは、PostgreSQL用に設計された人気のある接続プールです。
ロードバランサーの使用は、データベーストポロジで高可用性を実現する方法であり、使用可能なノード間のトラフィックのバランスをとることでパフォーマンスを向上させるのにも役立ちます。このため、HAProxyは、TCPおよびHTTPベースのアプリケーションの高可用性、負荷分散、およびプロキシを実装するために使用できるオープンソースプロキシであるため、PostgreSQLに適したオプションです。
HAProxy、PgBouncer、およびPostgreSQLの組み合わせを実装する方法
HAProxyとPgBouncerの両方のテクノロジーを組み合わせることは、PostgreSQL環境のパフォーマンスを拡張および改善するための最良の方法です。したがって、次のアーキテクチャを使用して実装する方法を説明します。
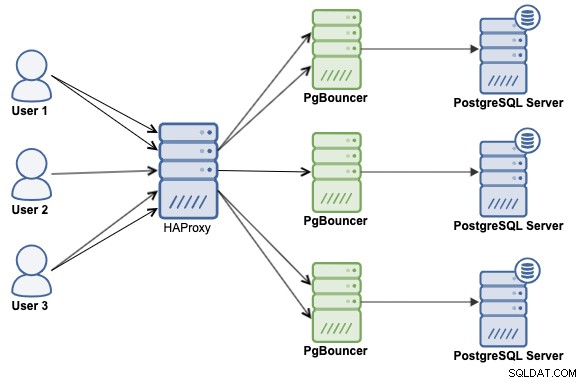
ClusterControlがインストールされていると想定します。インストールされていない場合は、次のURLにアクセスできます。公式サイト、または公式ドキュメントを参照してインストールしてください。
まず、HAProxyを前に置いてPostgreSQLクラスターをデプロイする必要があります。このためには、このブログ投稿の手順に従って、ClusterControlを使用してPostgreSQLとHAProxyの両方をデプロイしてください。
この時点で、次のようになります。
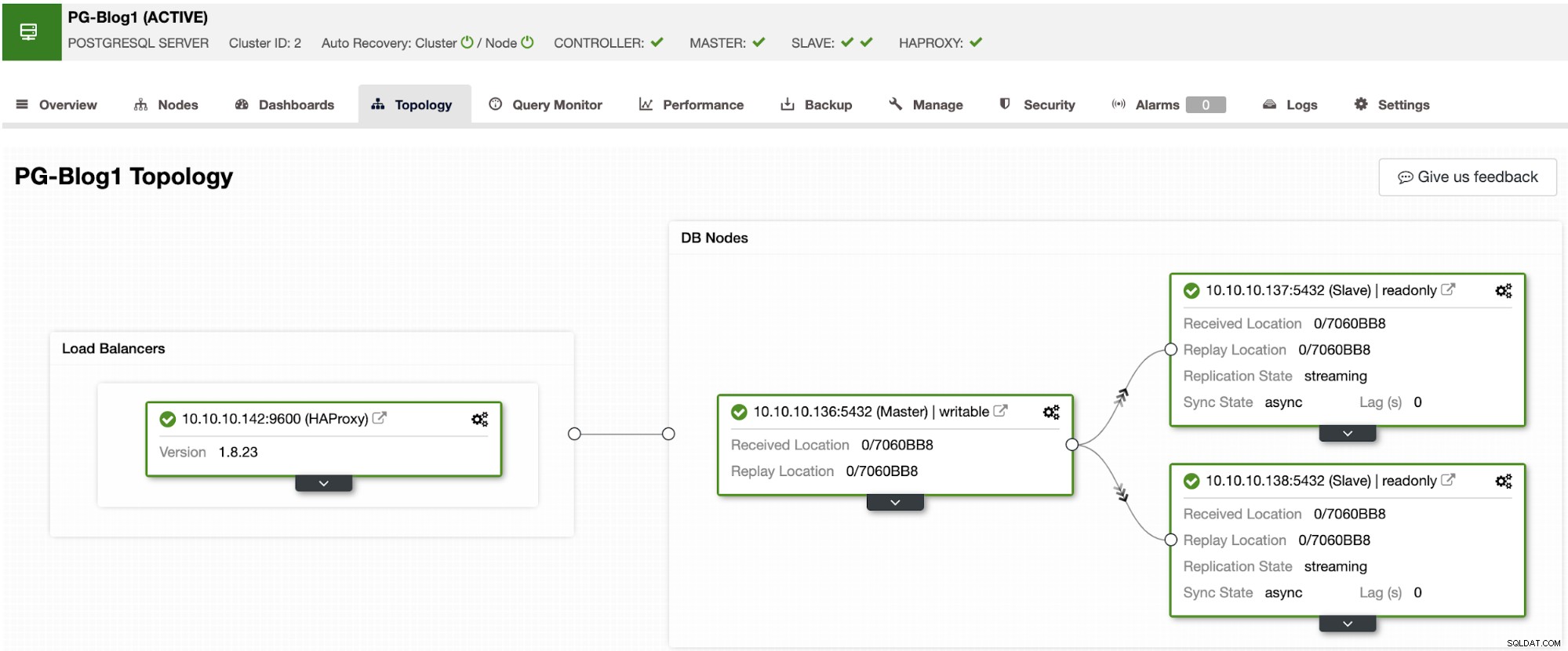
これで、各データベースノードまたは外部マシンにPgBouncerをインストールできます。 。
PgBouncerソフトウェアを入手するには、PgBouncerダウンロードセクションに移動するか、RPMまたはDEBリポジトリを使用します。この例では、CentOS 8を使用し、公式のPostgreSQLリポジトリからインストールします。
まず、PostgreSQLサイトから対応するリポジトリをダウンロードしてインストールします(まだインストールしていない場合):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpm次に、PgBouncerパッケージをインストールします。
$ yum install pgbouncer完了すると、/ etc / pgbouncer/pgbouncer.iniに新しい構成ファイルが作成されます。デフォルトの構成ファイルとして、次の例を使用できます。
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbそして認証ファイル:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"したがって、この場合、同じデータベースノードにPgBouncerをインストールし、すべてのIPアドレスをリッスンし、「world」と呼ばれるPostgreSQLデータベースに接続します。また、userlist.txtファイルで許可されているユーザーを、必要に応じて暗号化できるプレーンテキストのパスワードで管理しています。
PgBouncerサービスを開始するには、次のコマンドを実行する必要があります。
$ pgbouncer -d /etc/pgbouncer/pgbouncer.ini次に、ローカル情報(ポート、ホスト、ユーザー名、データベース名)を使用して次のコマンドを実行し、PostgreSQLデータベースにアクセスします。
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#PgBouncerとその使用方法の詳細については、このブログ投稿を参照してください。
PostgreSQLクラスターをスケーリングする必要がある場合は、HAProxyとPgBouncerを追加すると、トラフィックのバランスをとるためにホットスタンバイノードを追加できるため、スケールアウトとスケールアップを同時に行うことができます。開いた接続を再利用するとパフォーマンスが向上します。
ClusterControlは、監視、アラート、自動フェイルオーバー、バックアップ、ポイントインタイムリカバリ、バックアップ検証から、リードレプリカのスケーリングまで、幅広い機能を提供します。これは、使いやすく直感的なUIからPostgreSQLデータベースを水平方向または垂直方向にスケーリングするのに役立ちます。