しない インデックスを使用する 一意の単一の数字キーを除きます。
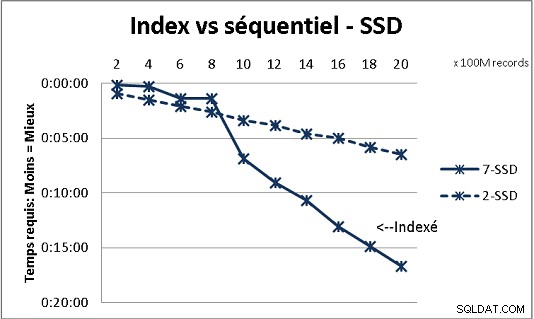
これは、私たちが受け取ったすべてのDB理論に適合するわけではありませんが、大量のデータを使用したテストで実証されています。これは、テーブル内の20億行に到達するために、一度に1億回のロードが行われた結果であり、そのたびに、結果のテーブルに対してさまざまなクエリが実行されます。最初のグラフィックは10ギガビットNAS(150MB / s)で、2番目はRAID0の4SSD(R / W @ 2GB / s)です。
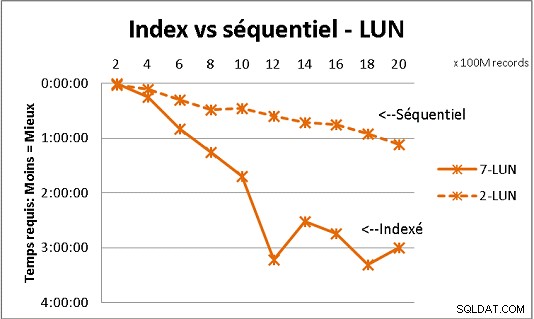
通常のディスクのテーブルに2億を超える行がある場合、インデックスを忘れると高速になります。 SSDでは、制限は10億です。
より良い結果を得るためにパーティションでもそれを行いましたが、PG9.2では、ストアドプロシージャを使用する場合にパーティションから利益を得るのは困難です。また、一度に1つのパーティションのみへの書き込み/読み取りを処理する必要があります。ただし、パーティションは、テーブルを10億行の壁より下に保つための方法です。また、大いに役立ちます 負荷をマルチプロセッシングします。 SSDを使用すると、単一のプロセスで18,000行/秒を挿入(コピー)できます(一部の処理作業が含まれます)。 6 CPUでのマルチプロセッシングでは、80,000行/秒に増加します。
テスト中にCPUとIOの使用状況を監視して、両方を最適化します。