SQL UNIONで苦労していませんか?組み合わせた結果によってSQLServerが停止した場合に発生します。または、以前に機能していたレポートが赤いXアイコンの付いたボックスをポップアップします。 UNIONのある行を指す「オペランドタイプの衝突」エラーが発生します。 「火」が始まります。おなじみですか?
SQL UNIONをしばらく使用している場合でも、始めたばかりの場合でも、虎の巻や簡潔なメモのセットは問題ありません。これは、この投稿で今日取得するものです。このリストは、初心者とベテランの両方に役立つ10のヒントを提供します。また、例といくつかの高度な議論があります。

[sendpulse-form id =” 11900”]
ただし、最初のポイントに入る前に、用語を明確にしましょう。
UNIONは、2つ以上の結果セットを組み合わせるSQLの集合演算子の1つです。さまざまなソースからの名前や月次統計などを組み合わせる必要がある場合に便利です。また、SQL Server、MySQL、またはOracleのいずれを使用する場合でも、目的、動作、および構文は非常に似ています。しかし、それはどのように機能しますか?
1。 SQLUNIONを使用して一意を組み合わせる 記録
UNIONを使用して結果セットを結合すると、重複が削除されます。
これが重要な理由
ほとんどの場合、重複した結果は必要ありません。行が重複しているレポートでは、ハードコピーでインクと紙が無駄になります。そして、これはあなたのユーザーを怒らせます。
使い方
SELECTステートメントの結果をUNIONと組み合わせます。
例を始める前に、サンプルデータを準備しましょう。
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
上記のコードによって生成されたデータは、3番目のヒントまで使用します。準備ができたので、以下に例を示します。
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
同じ顧客の名前のコピーが3つあり、一意のレコードがなくなると予想されます。結果を見る:
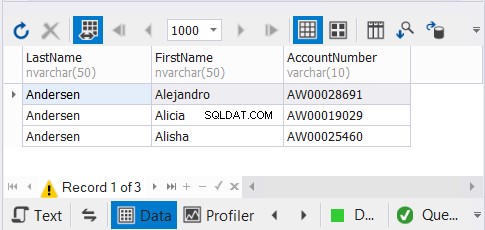
この例で使用するdbForgeStudiofor SQL Serverソリューションは、3つのレコードのみを示しています。 9だった可能性があります。UNIONを適用することで、重複を削除しました。
どのように機能しますか?
dbForge Studioの計画図は、SQLServerが図1に示す結果をどのように生成するかを示しています。 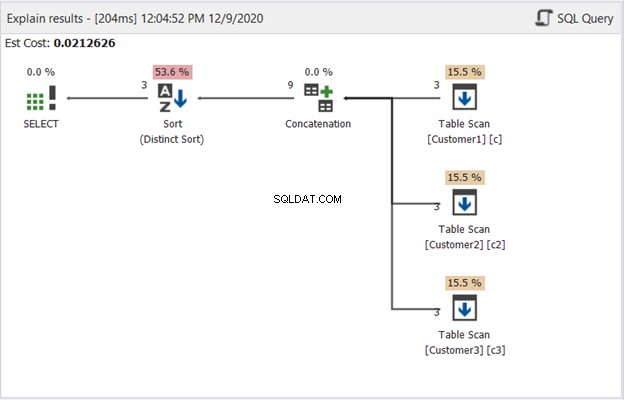
図2を解釈するには、右から左に始めます。
- 各テーブルスキャンオペレーターから3つのレコードを取得しました。これらは、上記の例の3つのSELECTステートメントです。そこから出る各行には、それぞれ3つのレコードを意味する「3」が表示されます。
- 連結演算子は結果の結合を行います。そこから出ている行は「9」を示しています。これは、結果を組み合わせた9つのレコードの出力です。
- Distinct Sort演算子は、一意のレコードが最終出力になるようにします。そこから出ている行は「3」を示しています。これは、図1のレコード数と一致しています。
上の図は、UNIONがSQLServerによってどのように処理されるかを示しています。使用される演算子の数とタイプは、クエリと基になるデータソースによって異なる場合があります。しかし、要約すると、UNIONは次のように機能します。
- 各SELECTステートメントの結果を取得します。
- 結果を連結演算子で結合します。
- 結合された結果が一意でない場合、SQLServerは重複を除外します。
UNIONで成功した例はすべて、次の基本的な手順に従います。
2。 SQL UNION ALLを使用して、レコードを重複と組み合わせる
UNION ALLを使用すると、結果セットと重複が含まれます。
これが重要な理由
結果セットを組み合わせて、後で処理するために重複したレコードを取得することをお勧めします。このタスクは、データをクリーンアップするのに役立ちます。
使い方
SELECTステートメントの結果をUNIONALLと組み合わせます。例を見てください:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
上記のコードは、図3に示すように9つのレコードを出力します。
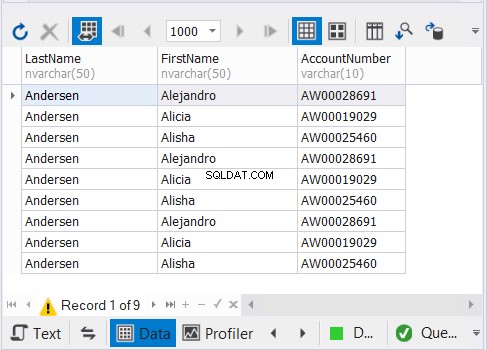
どのように機能しますか?
以前と同様に、計画図を使用して、これがどのように機能するかを確認します。
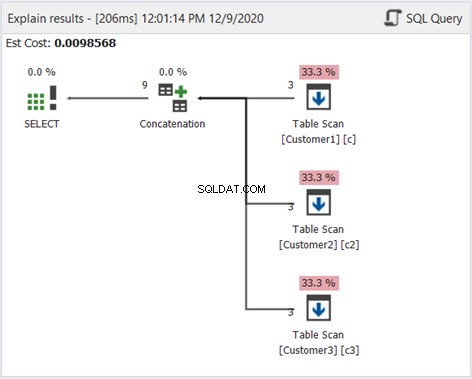
図2のSortDistinctを除いて、上の図は同じです。重複を除外したくないので、これは適切です。
上の図は、UNIONALLがどのように機能するかを示しています。要約すると、SQLServerが実行する手順は次のとおりです。
- 各SELECTステートメントの結果を取得します。
- 次に、結果を連結演算子と組み合わせます。
UNION ALLで成功した例は、このパターンに従います。
3。 SQLUNIONとUNIONALLを混在させることができますが、括弧でグループ化することもできます
少なくとも3つのSELECTステートメントでUNIONとUNIONALLの使用を混在させることができます。
使い方は?
SELECTステートメントの結果をUNIONまたはUNIONALLのいずれかと組み合わせます。括弧は結果をまとめてグループ化します。次の例でも同じデータを使用しましょう:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
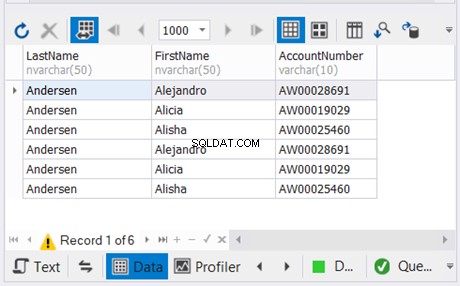
上記の例では、最後の2つのSELECTステートメントの結果を重複せずに組み合わせています。次に、それを最初のSELECTステートメントの結果と組み合わせます。結果は下の図5にあります:
4。各SELECTステートメントの列には互換性のあるデータ型が必要です
UNIONを使用する各SELECTステートメントの列は、異なるデータ型を持つことができます。互換性があり、暗黙的な変換が可能である限り、許容されます。結合された結果の最終的なデータ型は、優先順位が最も高いデータ型を使用します。また、最終的なデータサイズの基準は、最大サイズのデータです。文字列の場合、文字数が最も多いデータを使用します。
これが重要な理由
UNIONの結果をテーブルに挿入する必要がある場合、最終的なデータ型とサイズによって、ターゲットテーブルの列に収まるかどうかが決まります。そうでない場合、エラーが発生します。たとえば、UNIONの列の1つの最終タイプはNVARCHAR(50)です。ターゲットテーブルの列がVARCHAR(50)の場合、それをテーブルに挿入することはできません。
どのように機能しますか?
例よりも説明するのに良い方法はありません:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
上記のサンプルには、英語、韓国語、タイ語の文字名のデータが含まれています。タイ語と韓国語はUnicode文字です。英語の文字はそうではありません。では、最終的なデータ型とサイズはどうなると思いますか? dbForge Studioは、結果セットにそれを表示します:
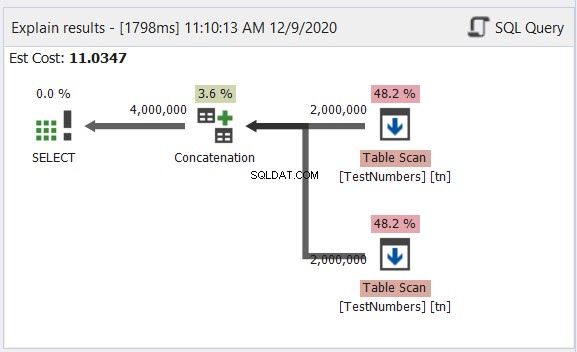
図6の最終的なデータ型に気づきましたか? Unicode文字のため、VARCHARにすることはできません。したがって、NVARCHARである必要があります。一方、最大文字数のデータは14文字であるため、サイズは14未満にすることはできません。図6の赤いキャプションを参照してください。dbForgeStudioの列ヘッダーにデータ型とサイズを含めることをお勧めします。
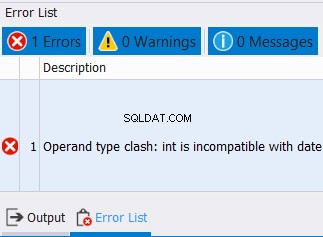
これは、文字列データ型だけではありません。数字と日付にも適用されます。一方、互換性のないデータ型のデータを結合しようとすると、エラーが発生します。以下の例を参照してください:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
日付と整数を1つの列に結合することはできません。したがって、次のようなエラーが発生する可能性があります。
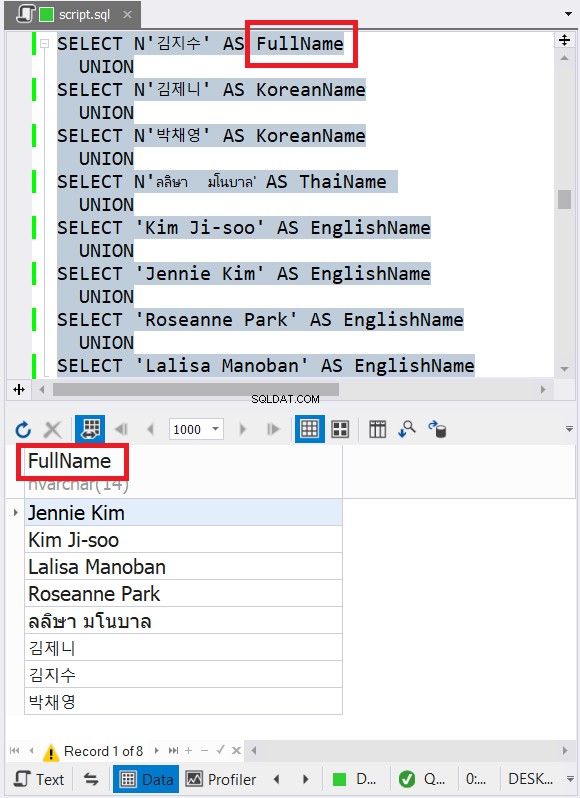
5。結合された結果の列名は、最初のSELECTステートメントの列名を使用します
この問題は、前のヒントに関連しています。ヒント4のコードの列名に注意してください。 SELECTステートメントごとに異なる列名があります。ただし、前の図6の結合結果には、最終的な列名が表示されています。したがって、基本は最初のSELECTステートメントの列名です。
これが重要な理由
これは、UNIONの結果を一時テーブルにダンプする必要がある場合に便利です。後続のステートメントでその列名を参照する必要がある場合は、名前を確認する必要があります。 IntelliSenseで高度なコードエディタを使用していない限り、T-SQLコードで別のエラーが発生します。
どのように機能しますか?
dbForge Studioを使用した明確な結果については、図8を参照してください。
6。 SQLUNIONを使用して最後のSELECTステートメントにORDERBYを追加し、結果を並べ替えます
組み合わせた結果を並べ替える必要があります。 UNIONを間に挟んだ一連のSELECTステートメントでは、最後のSELECTステートメントのORDERBY句を使用してそれを行うことができます。
これが重要な理由
ユーザーは、アプリ、ウェブページ、レポート、スプレッドシートなどで好みの方法でデータを並べ替えたいと考えています。
使い方
最後のSELECTステートメントでORDERBYを使用します。次に例を示します:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
上記のサンプルでは、最後のSELECTステートメントでのみ並べ替えが行われているように見えます。しかし、そうではありません。結合された結果に対して機能します。各SELECTステートメントに配置すると問題が発生します。結果を見る:
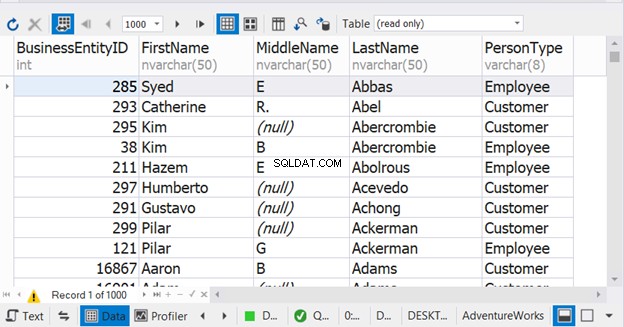
ORDER BYがない場合、結果セットにはすべてのEmployee PersonTypeが含まれます。 最初にすべての顧客PersonTypeが続きます 。ただし、図9は、名前が結合された結果のソート順になることを示しています。
並べ替えるために各SELECTステートメントにORDERBYを配置しようとすると、次のようになります。
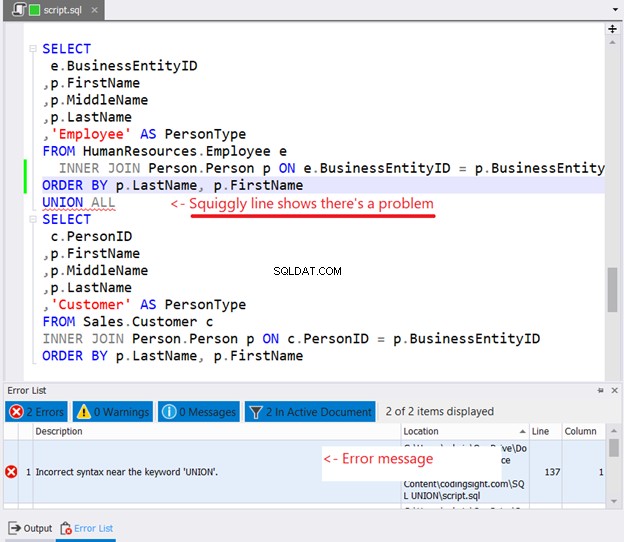
図10の波線を見ましたか?警告です。気づかずに続行すると、dbForgeStudioのエラーリストウィンドウにエラーが表示されます。
7。 WHERE句とGROUPBY句は、SQLUNIONを使用する各SELECTステートメントで使用できます
ORDER BY句は、UNIONを間に挟んだ各SELECTステートメントでは機能しません。ただし、WHERE句とGROUPBY句は機能します。
これが重要な理由
データをフィルタリング、カウント、または要約するさまざまなクエリの結果を組み合わせることができます。たとえば、これを実行して、2012年1月の総販売注文を取得し、2013年1月、2014年1月などと比較できます。
使い方
WHERE句やGROUPBY句を各SELECTステートメントに配置します。以下の例を確認してください:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
上記のコードは、3年連続の1月の注文数を組み合わせたものです。次に、出力を確認します:
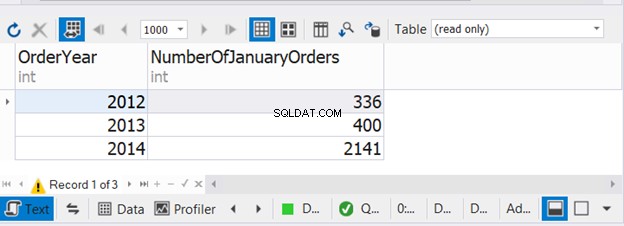
この例は、UNIONで3つのSELECTステートメントのそれぞれでWHEREとGROUPBYを使用できることを示しています。
8。 SELECTINTOはSQLUNIONで動作します
SQL UNIONを使用したクエリの結果をテーブルに挿入する必要がある場合は、SELECTINTOを使用して挿入できます。
これが重要な理由
UNIONを使用したクエリの結果を、さらに処理するためにテーブルに配置する必要がある場合があります。
使い方
INTO句を最初のSELECTステートメントに配置します。次に例を示します:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
最初のSELECTステートメントにはINTO句を1つだけ配置することを忘れないでください。
どのように機能しますか
SQL Serverは、UNIONの処理パターンに従います。次に、結果をINTO句で指定されたテーブルに挿入します。
9。 SQLUNIONとSQLJOINを区別する
SQLUNIONとSQLJOINはどちらもテーブルデータを結合しますが、構文と結果の違いは昼と夜のようです。
これが重要な理由
レポートまたは要件にJOINが必要であるが、UNIONを実行した場合、出力は正しくありません。
SQLUNIONとSQLJOINの使用方法
SQLUNIONとJOINです。これは、SQL UNIONについて学習するときに、初心者がGoogleで行う関連する検索クエリと質問の1つです。違いの表は次のとおりです:
| SQL UNION | SQL JOIN | |
| 結合されるもの | 行 | 列(キーを使用) |
| テーブルあたりの列数 | すべてのテーブルで同じ | 変数(すべての列/テーブルに対してゼロ) |
私が参加したすべてのプロジェクトでは、SQLJOINがほとんどの場合適用されます。 SQLUNIONを使用したケースはごくわずかでした。しかし、これまで見てきたように、SQLUNIONは役に立たないというわけではありません。
10。 SQLUNIONALLはUNIONよりも高速です
前の図2と図4の計画図は、UNIONが独自の結果を保証するために追加のオペレーターを必要とすることを示唆しています。そのため、UNIONALLの方が高速です。
これが重要な理由
あなた、あなたのユーザー、あなたの顧客、あなたの上司はすべて、迅速な結果を望んでいます。 UNION ALLがUNIONよりも高速であることを知っていると、独自の組み合わせ結果が必要な場合にどうすればよいか疑問に思います。後で説明するように、1つの解決策があります。
SQLUNIONALLとUNIONのパフォーマンス
図2と図4は、どちらが速いかをすでに示しています。ただし、使用されるコードサンプルは単純で、結果セットは小さくなっています。説得力のあるものにするために、何百万ものレコードを使用してさらにいくつかの比較を追加しましょう。
まず、データを準備しましょう:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
これは200万レコードです。それが十分に説得力があることを願っています。それでは、次の2つのクエリサンプルを以下に示します。
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
これらのクエリに関連するプロセスを、より高速なものから調べてみましょう。
計画図分析
図12の図は、UNIONALLプロセスの典型的なものです。ただし、結果は合計で400万件になります。連結演算子から出る矢印を参照してください。それでも、それは通常、重複を処理しないためです。
それでは、図13のUNIONクエリの図を見てみましょう。
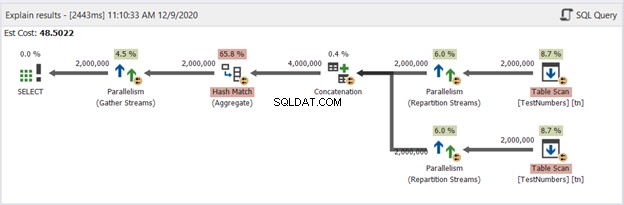
これはもはや典型的ではありません。このプランは、400万行の重複の削除を処理する並列クエリプランになります。並列クエリプランは、SQLServerがプロセスを使用可能なプロセッサコアの数で割る必要があることを意味します。
右の演算子から左に向かって解釈してみましょう:
- テーブルをそれ自体に結合しているため、SQLServerはテーブルを2回取得する必要があります。それぞれ200万レコードの2つのテーブルスキャンをご覧ください。
- パーティションストリームオペレータは、次に使用可能なスレッドへの各行の分散を制御します。
- 連結により、結果は2倍の400万になります。これはまだプロセッサコアの数を考慮しています。
- 重複を削除するには、ハッシュマッチが適用されます。これは、65.8%のオペレーターコストを伴う高価なプロセスです。その結果、200万件のレコードが破棄されました。
- Gather Streamsは、各プロセッサコアまたはスレッドで実行された結果を1つに再結合します。
プロセスが複数のスレッドに分割されている場合でも、これは大変な作業です。したがって、実行速度が遅くなると結論付けます。しかし、UNION ALLを使用して、これよりも高速に一意のレコードを取得するソリューションがある場合はどうなりますか?
UNION ALLを使用すると、独自の結果が得られますが、修正が速くなります–どのように?
私はあなたを待たせません。コードは次のとおりです:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
これは不完全な解決策になる可能性があります。しかし、図14の計画図を確認してください:
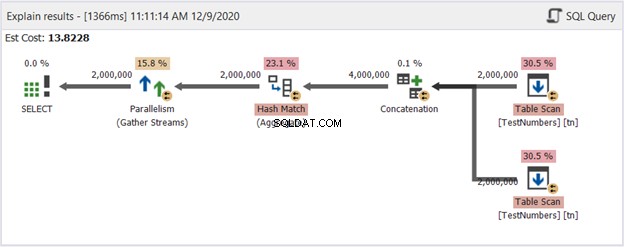
それで、何がそれをより良くしたのですか?図13と比較すると、再パーティションストリーム演算子がなくなっていることがわかります。ただし、それでもジョブを実行するために複数のスレッドを利用します。一方、クエリオプティマイザは、UNIONを使用したクエリよりもこのプロセスを実行する方が簡単であると見なしていることを意味します。
UNIONの使用を避け、代わりにこのアプローチを使用する必要があると安全に結論付けることができますか?全くない! 実行計画図を常に確認してください! それは常にSQLServerに何を提供したいかによって異なります。これは、パフォーマンスの壁にぶつかった場合に、クエリのアプローチを変更する必要があることを示しているだけです。
I / O統計はどうですか?
SQLServerがクエリの例を処理するために必要なリソースの量を無視することはできません。そのため、彼らのSTATISTICSIOも調べる必要があります。上記の3つのクエリを比較すると、以下の論理的な読み取りが得られます。
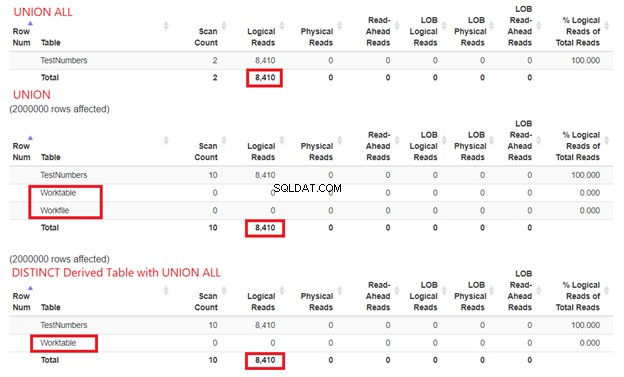
図15から、論理読み取りは同じですが、UNIONALLはUNIONよりも高速であると結論付けることができます。 Worktableの存在 およびワークファイル tempdbを使用したショー 仕事を成し遂げるために。一方、UNIONALLで派生テーブルからSELECTDISTINCTを使用すると、 tempdb UNIONに比べて使用量が少ないです。これにより、以前の計画図からの分析が正しいことがさらに再確認されます。
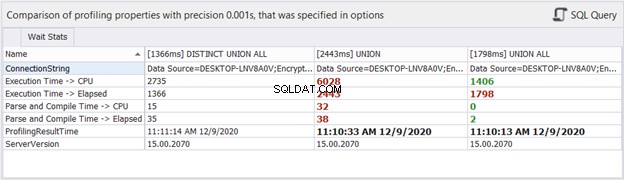
時間統計はどうですか?
経過時間は、同じクエリに対して実行するたびに変化する可能性がありますが、それは私たちにいくつかのアイデアを与え、分析にさらに証拠を追加することができます。 dbForge Studioは、上記の3つのクエリの時差を表示します。この比較は、以前に行った分析と一致しています。
結論
SQLUNIONおよびUNIONALLを使用するために必要なものを提供するために、多くの背景を説明しました。この投稿を読んだ後はすべてを覚えていない可能性があるため、必ずこのページをブックマークしてください。
投稿が気に入ったら、ソーシャルメディアで自由に共有してください。