昨年10月、PyBitesの視聴者に、DailyPythonTipフィードをより適切にナビゲートするためのWebアプリを作成するように依頼しました。この記事では、私が構築して学んだことを共有します。
この記事では、次のことを学びます。
- プロジェクトリポジトリのクローンを作成してアプリを設定する方法。
- Tweepyモジュールを介してTwitterAPIを使用してツイートを読み込む方法。
- SQLAlchemyを使用してデータ(ヒントとハッシュタグ)を保存および管理する方法。
- Flaskに似たマイクロウェブフレームワークであるBottleを使用してシンプルなウェブアプリを構築する方法。
- pytestフレームワークを使用してテストを追加する方法。
- BetterCodeHubのガイダンスがどのようにしてより保守しやすいコードにつながったか。
コードを詳細に読んで(そしておそらく貢献して)フォローしたい場合は、リポジトリをフォークすることをお勧めします。始めましょう。
プロジェクトの設定
まず、名前空間は素晴らしいアイデアの1つです それでは、仮想環境で作業を行いましょう。 Anacondaを使用して、次のように作成します:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Postgresで本番データベースとテストデータベースを作成します:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
データベースとTwitterAPIに接続するためのクレデンシャルが必要です(最初に新しいアプリを作成します)。ベストプラクティスに従って、構成はコードではなく環境に保存する必要があります。次の環境変数を〜/ virtualenvs / pytip / bin / activateの最後に配置します 、仮想環境のアクティブ化/非アクティブ化を処理するスクリプト。環境の変数を必ず更新してください。
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
同じスクリプトの非アクティブ化関数で、それらの設定を解除して、仮想環境を非アクティブ化(離脱)するときにシェルスコープから外れるようにします:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
今が仮想環境をアクティブ化する良い機会です:
$ source ~/virtualenvs/pytip/bin/activate
リポジトリのクローンを作成し、仮想環境を有効にして、要件をインストールします。
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
次に、ツイートのコレクションを次のようにインポートします:
$ python tasks/import_tweets.py
次に、テーブルが作成され、ツイートが追加されたことを確認します。
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
それでは、テストを実行しましょう:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
最後に、Bottleアプリを次のコマンドで実行します:
$ python app.py
http:// localhost:8080とvoilàを参照してください。人気の降順で並べ替えられたヒントが表示されます。左側のハッシュタグリンクをクリックするか、検索ボックスを使用して、簡単にフィルタリングできます。ここにパンダが表示されます 例のヒント:
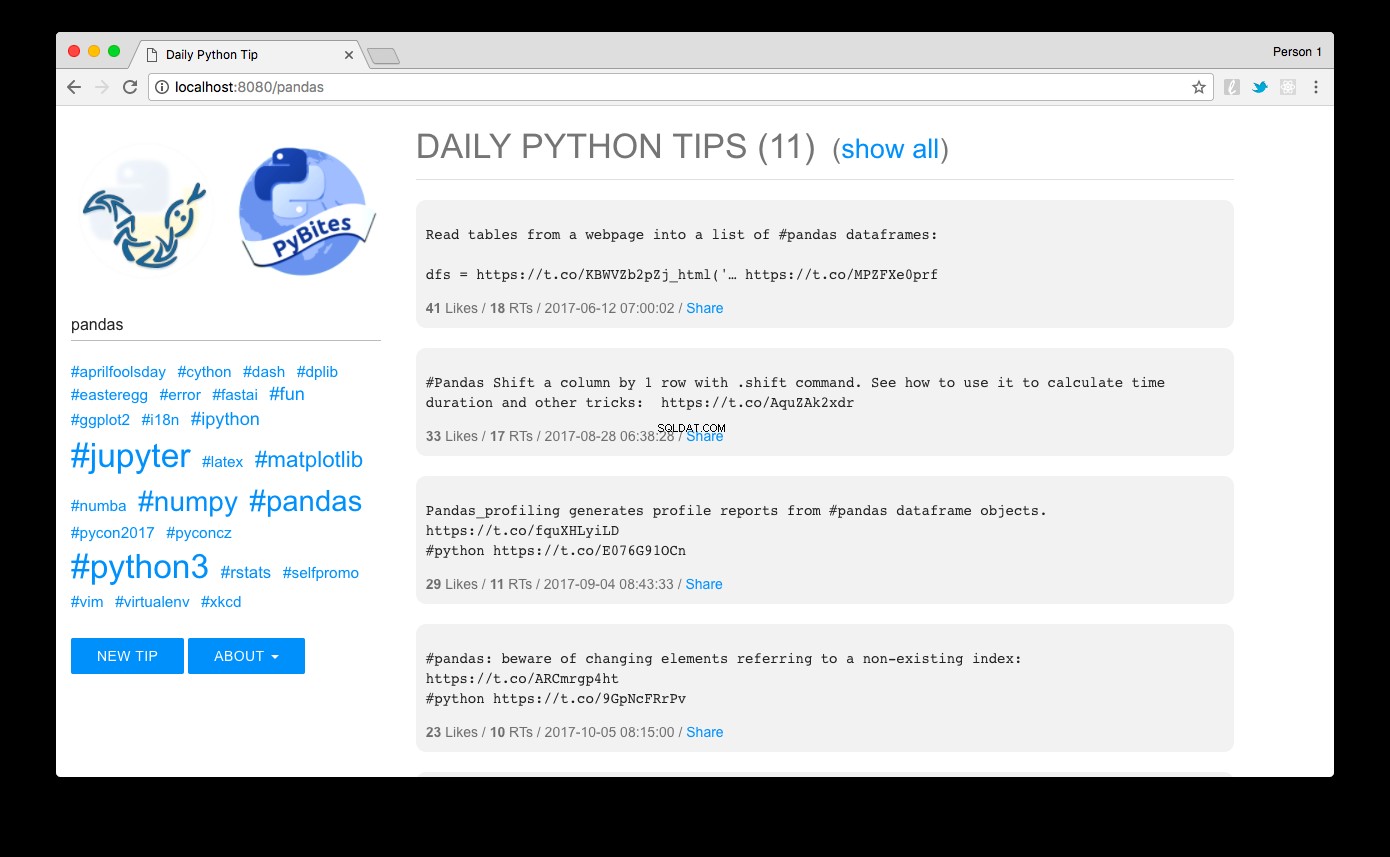
MUIで作成したデザイン-Googleのマテリアルデザインガイドラインに従った軽量のCSSフレームワーク。
実装の詳細
DBとSQLAlchemy
SQLAlchemyを使用してDBとインターフェイスし、大量の(冗長な)SQLを記述しなくても済むようにしました。
Tips / models.py 、モデルを定義します-Hashtag およびTip -SQLAlchemyがDBテーブルにマップすること:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
Tips / db.py 、これらのモデルをインポートしました。これで、たとえばHashtagとのインターフェースなど、DBを簡単に操作できるようになりました。 モデル:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
そして:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
TwitterAPIをクエリする
Twitterからデータを取得する必要があります。そのために、 tasks / import_tweets.pyを作成しました 。これをタスクにパッケージ化しました 新しいヒントを探し、既存のツイートの統計(いいねやリツイートの数)を更新するために、毎日のcronジョブで実行する必要があるためです。簡単にするために、テーブルを毎日再作成しています。他のテーブルとのFK関係に依存し始めた場合は、delete+addではなくupdateステートメントを選択する必要があります。
このスクリプトは、プロジェクトのセットアップで使用しました。それが何をするのかをもっと詳しく見てみましょう。
まず、tweepy.Cursorに渡すAPIセッションオブジェクトを作成します。 APIのこの機能は非常に優れています。つまり、タイムラインを反復処理するページネーションを処理します。ヒントの量(これを書いている時点では222)については、非常に高速です。 exclude_replies=True およびinclude_rts=False 引数は、Daily Python Tipの独自のツイートのみが必要なので便利です(リツイートは必要ありません)。
ヒントからハッシュタグを抽出するのに必要なコードはごくわずかです。
まず、タグの正規表現を定義しました:
TAG = re.compile(r'#([a-z0-9]{3,})')
次に、findallを使用しました すべてのタグを取得します。
それらをcollections.Counterに渡しました。これは、タグをキーとして持つdictのようなオブジェクトを返し、値の降順(最も一般的)で値としてカウントします。結果を歪める可能性のあるあまりにも一般的なPythonタグを除外しました。
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
最後に、import_* tasks / import_tweets.pyの関数 add_*を呼び出して、ツイートとハッシュタグの実際のインポートを行います ヒントのDBメソッド ディレクトリ/パッケージ。
ボトルを使用してシンプルなウェブアプリを作成する
この事前作業が完了すると、Webアプリの作成は驚くほど簡単になります(または、以前にFlaskを使用したことがある場合はそれほど驚くことではありません)。
まず、ボトルに会います:
Bottleは、Python用の高速でシンプルかつ軽量なWSGIマイクロWebフレームワークです。単一のファイルモジュールとして配布され、Python標準ライブラリ以外の依存関係はありません。
良い。結果として得られるWebアプリは<30LOCで構成され、app.pyにあります。
この単純なアプリの場合、必要なのはオプションのタグ引数を持つ単一のメソッドだけです。 Flaskと同様に、ルーティングはデコレータで処理されます。タグを付けて呼び出すと、タグのヒントがフィルタリングされます。それ以外の場合は、すべてが表示されます。ビューデコレータは、使用するテンプレートを定義します。 Flask(およびDjango)と同様に、テンプレートで使用するためのdictを返します。
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
ドキュメントによると、静的ファイルを操作するには、インポート後に次のスニペットを上部に追加します。
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
最後に、ローカルホストでデバッグモードでのみ実行するようにします。したがって、APP_LOCATION プロジェクト設定で定義した環境変数:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
ボトルテンプレート
ボトルには、SimpleTemplateと呼ばれる高速で強力で習得しやすい組み込みのテンプレートエンジンが付属しています。
ビューサブディレクトリで、 header.tplを定義しました 、 index.tpl 、および footer.tpl 。タグクラウドについては、タグサイズをカウントごとに増やす単純なインラインCSSを使用しました。 header.tplを参照してください。 :
タグ内のタグの% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
index.tpl内 ヒントをループします:
ヒントのヒントの% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
FlaskとJinja2に精通している場合、これは非常に精通しているように見えるはずです。 Pythonの埋め込みはさらに簡単で、入力が少なくて済みます— (% ... vs {% ... %} 。
すべてのcss、画像(および使用する場合はJS)は静的サブフォルダーに入ります。
これで、Bottleを使用して基本的なWebアプリを作成できます。データレイヤーを適切に定義すると、非常に簡単になります。
pytestでテストを追加
次に、いくつかのテストを追加して、このプロジェクトをもう少し堅牢にします。 DBをテストするには、pytestフレームワークをもう少し掘り下げる必要がありましたが、最終的にはpytest.fixtureデコレータを使用して、いくつかのテストツイートを含むデータベースをセットアップおよび破棄しました。
Twitter APIを呼び出す代わりに、 tweets.jsonで提供される静的データを使用しました。 。そして、ライブDBを使用するのではなく、 Tips / db.py 、pytestが呼び出し元であるかどうかを確認します(sys.argv[0] )。もしそうなら、私はテストDBを使用します。 Bottleは構成ファイルの操作をサポートしているため、おそらくこれをリファクタリングします。
ハッシュタグの部分はテストが簡単でした(test_get_hashtag_counter )複数行の文字列にハッシュタグを追加するだけでよいからです。備品は必要ありません。
コードの品質が重要-より良いコードハブ
より良いコードハブは、より良いコードを書くためのガイドです。テストを書く前に、プロジェクトは7点を獲得しました:
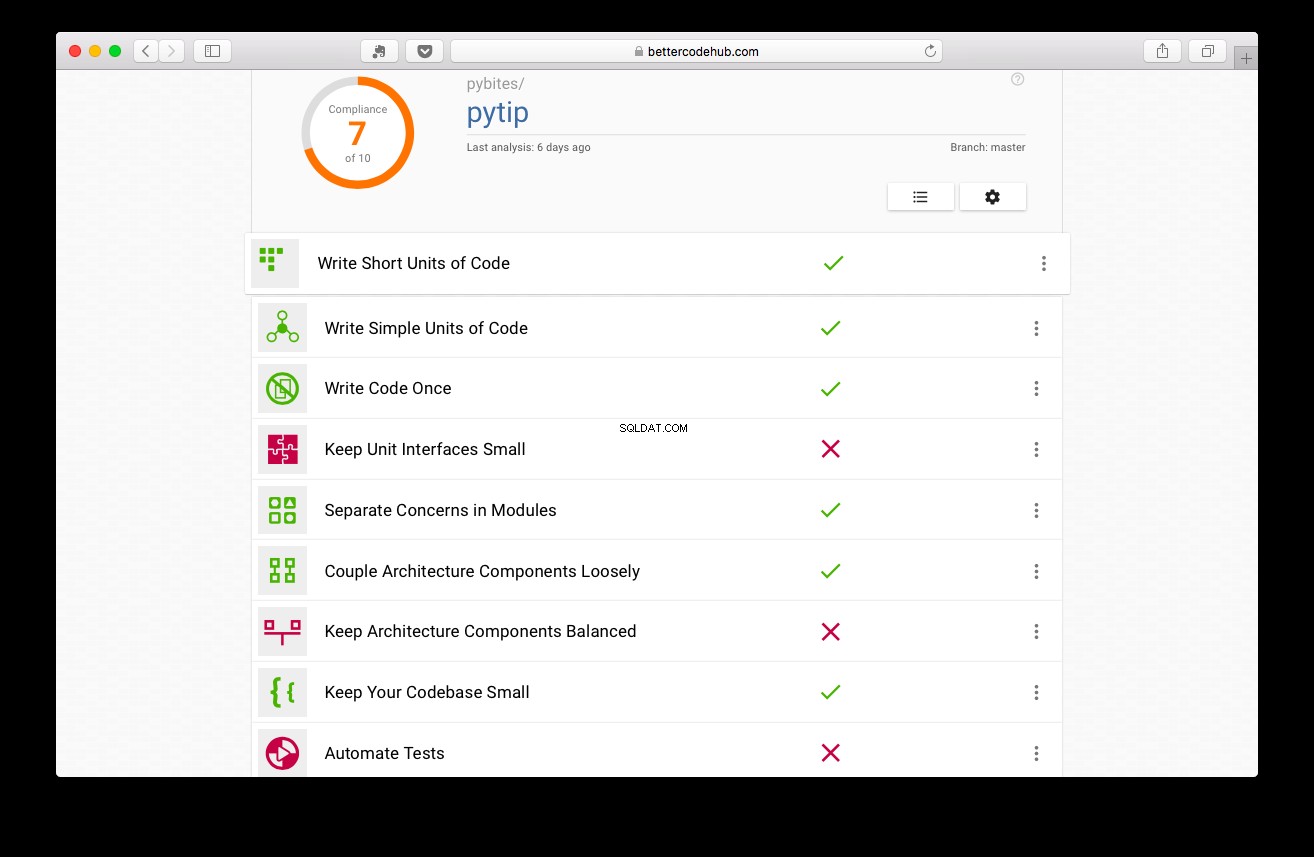
悪くはありませんが、もっとうまくやることができます:
-
コードをよりモジュール化して、app.py(Webアプリ)からDBロジックを取り出し、tipsフォルダー/パッケージ(リファクタリング1および2)に配置することで、9に上げました。
-
次に、テストを実施して、プロジェクトのスコアは10になりました:
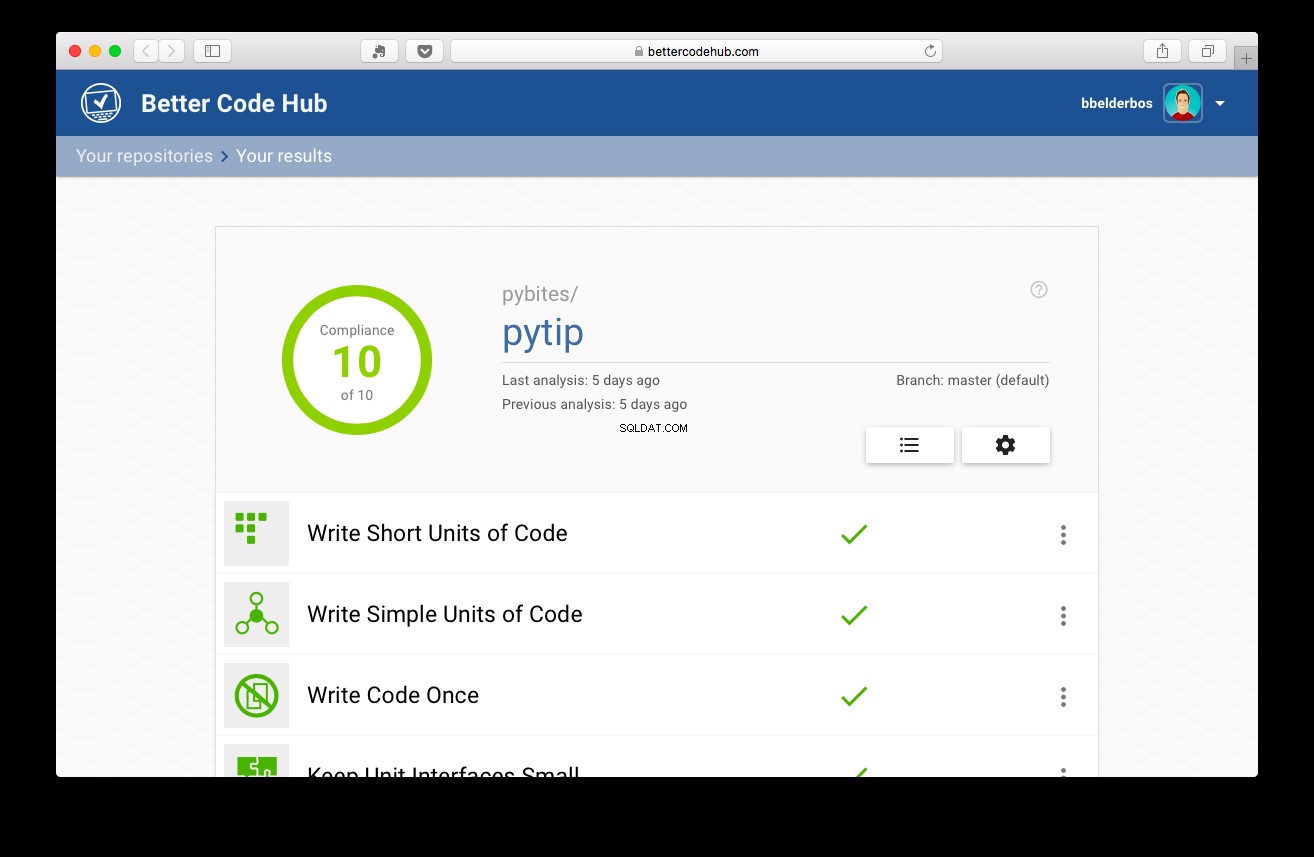
結論と学習
コードチャレンジ#40は、いくつかの優れた実践を提供しました:
- 拡張できる便利なアプリを作成しました(APIを追加したい)。
- Tweepy、SQLAlchemy、Bottleなどの探索する価値のあるいくつかのクールなモジュールを使用しました。
- DBとの相互作用をテストするためのフィクスチャが必要だったため、もう少しpytestを学びました。
- 何よりも、コードをテスト可能にする必要があるため、アプリはよりモジュール化され、保守が容易になりました。このプロセスでは、BetterCodeHubが非常に役立ちました。
- ステップバイステップガイドを使用して、アプリをHerokuにデプロイしました。
私たちはあなたに挑戦します
コーディングスキルを学び、向上させるための最良の方法は、練習することです。 PyBitesでは、Pythonコードの課題を整理することで、この概念を固めました。増え続けるコレクションをチェックして、リポジトリをフォークし、コーディングを入手してください!
あなたがあなたの仕事のプルリクエストをすることによってあなたが何かクールなものを作るかどうか私たちに知らせてください。私たちは、人々がこれらの課題を本当に乗り越えているのを見てきました。私たちもそうしました。
ハッピーコーディング!