現在、レプリケーションは、使用しているほとんどすべてのデータベーステクノロジーに対して、高可用性とフォールトトレラント環境で提供されています。これは私たちが何度も見たトピックですが、決して古くなることはありません。
TimescaleDBを使用している場合、最も一般的なタイプのレプリケーションはストリーミングレプリケーションですが、どのように機能しますか?
このブログでは、レプリケーションに関連するいくつかの概念を確認し、基盤となるPostgreSQLエンジンから継承された機能であるTimescaleDBのストリーミングレプリケーションに焦点を当てます。次に、ClusterControlがどのように構成に役立つかを確認します。
したがって、ストリーミングレプリケーションは、WALレコードを送信し、それらをスタンバイサーバーに適用することに基づいています。それでは、まず、WALとは何かを見てみましょう。
WAL
ログ先行書き込み(WAL)は、データの整合性を確保するための標準的な方法であり、デフォルトで自動的に有効になります。
WALは、TimescaleDBのREDOログです。しかし、REDOログとは何ですか?
REDOログには、データベースで行われたすべての変更が含まれ、レプリケーション、リカバリ、オンラインバックアップ、およびポイントインタイムリカバリ(PITR)で使用されます。データページに適用されていない変更は、REDOログからやり直すことができます。
WALを使用すると、トランザクションによって変更されたすべてのデータファイルではなく、トランザクションがコミットされたことを保証するためにログファイルのみをディスクにフラッシュする必要があるため、ディスク書き込みの数が大幅に減少します。
WALレコードは、データに加えられた変更をビットごとに指定します。各WALレコードはWALファイルに追加されます。挿入位置は、ログへのバイトオフセットであるログシーケンス番号(LSN)であり、新しいレコードごとに増加します。
WALは、データディレクトリの下のpg_walディレクトリに保存されます。これらのファイルのデフォルトサイズは16MBです(サーバーの構築時に--with-wal-segsize設定オプションを変更することでサイズを変更できます)。これらには、「000000010000000000000000」という形式の一意の増分名があります。
pg_walに含まれるWALファイルの数は、postgresql.conf構成ファイルのmin_wal_sizeパラメーターとmax_wal_sizeパラメーターに割り当てられた値によって異なります。
すべてのTimescaleDBインストールを構成するときに設定する必要があるパラメーターの1つは、wal_levelです。これは、WALに書き込まれる情報の量を決定します。デフォルト値は最小で、クラッシュまたは即時シャットダウンから回復するために必要な情報のみを書き込みます。アーカイブは、WALアーカイブに必要なロギングを追加します。 hot_standbyは、スタンバイサーバーで読み取り専用クエリを実行するために必要な情報をさらに追加します。そして最後に、論理は論理デコードをサポートするために必要な情報を追加します。このパラメータは再起動が必要なため、それを忘れた場合、実行中の本番データベースで変更するのは難しい場合があります。
ストリーミングレプリケーション
ストリーミングレプリケーションは、ログ配布方法に基づいています。 WALレコードは、あるデータベースサーバーから別のデータベースサーバーに直接移動されて適用されます。継続的なPITRと言えます。
この転送は、WALレコードを一度に1つのファイル(WALセグメント)に転送する(ファイルベースのログ配布)方法と、WALレコード(WALファイルはWALレコードで構成される)をオンザフライで転送する(レコードベース)という2つの異なる方法で実行されます。ログ配布)、マスターサーバーと1つまたは複数のスレーブサーバー間で、WALファイルがいっぱいになるのを待たずに。
実際には、スレーブサーバーで実行されているWALレシーバーと呼ばれるプロセスは、TCP/IP接続を使用してマスターサーバーに接続します。マスターサーバーには、WAL送信者という名前の別のプロセスが存在し、WALレジストリをスレーブサーバーに送信する役割を果たします。
ストリーミングレプリケーションは、次のように表すことができます。
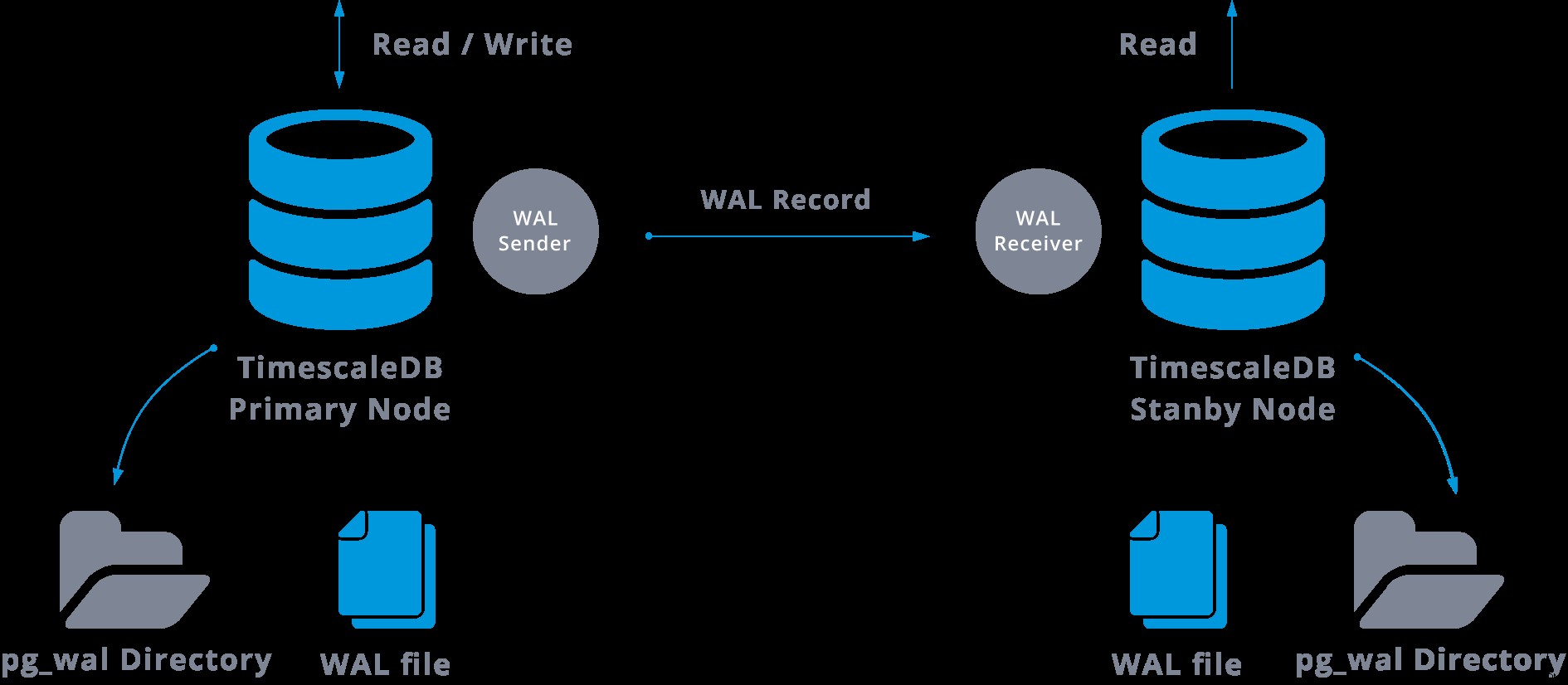
上の図を見ると、WAL送信者とWAL受信者の間の通信が失敗するとどうなるでしょうか。
ストリーミングレプリケーションを構成するときに、WALアーカイブを有効にするオプションがあります。
この手順は実際には必須ではありませんが、メインサーバーがまだスレーブに適用されていない古いWALファイルをリサイクルすることを回避する必要があるため、堅牢なレプリケーションセットアップにとって非常に重要です。これが発生した場合は、レプリカを最初から再作成する必要があります。
継続的なアーカイブを使用してレプリケーションを構成する場合、バックアップから開始し、マスターとの同期状態に到達するには、バックアップ後に発生したWALでホストされているすべての変更を適用する必要があります。このプロセス中、スタンバイは最初にアーカイブの場所で使用可能なすべてのWALを復元します(restore_commandを呼び出すことによって実行されます)。最後にアーカイブされたWALレコードに到達すると、restore_commandは失敗するため、その後、スタンバイはpg_walディレクトリを調べて、そこに変更が存在するかどうかを確認します(これは、マスターサーバーがクラッシュしたときのデータ損失を回避するために実際に行われます。すでにレプリカに移動され、そこに適用された変更は、まだアーカイブされていません。
それが失敗し、要求されたレコードがそこに存在しない場合、ストリーミングレプリケーションを介してマスターとの通信を開始します。
ストリーミングレプリケーションが失敗すると、手順1に戻り、アーカイブからレコードが再度復元されます。アーカイブから取得するこのループpg_walは、サーバーが停止するか、トリガーファイルによってフェイルオーバーがトリガーされるまで続きます。
これはそのような構成の図になります:
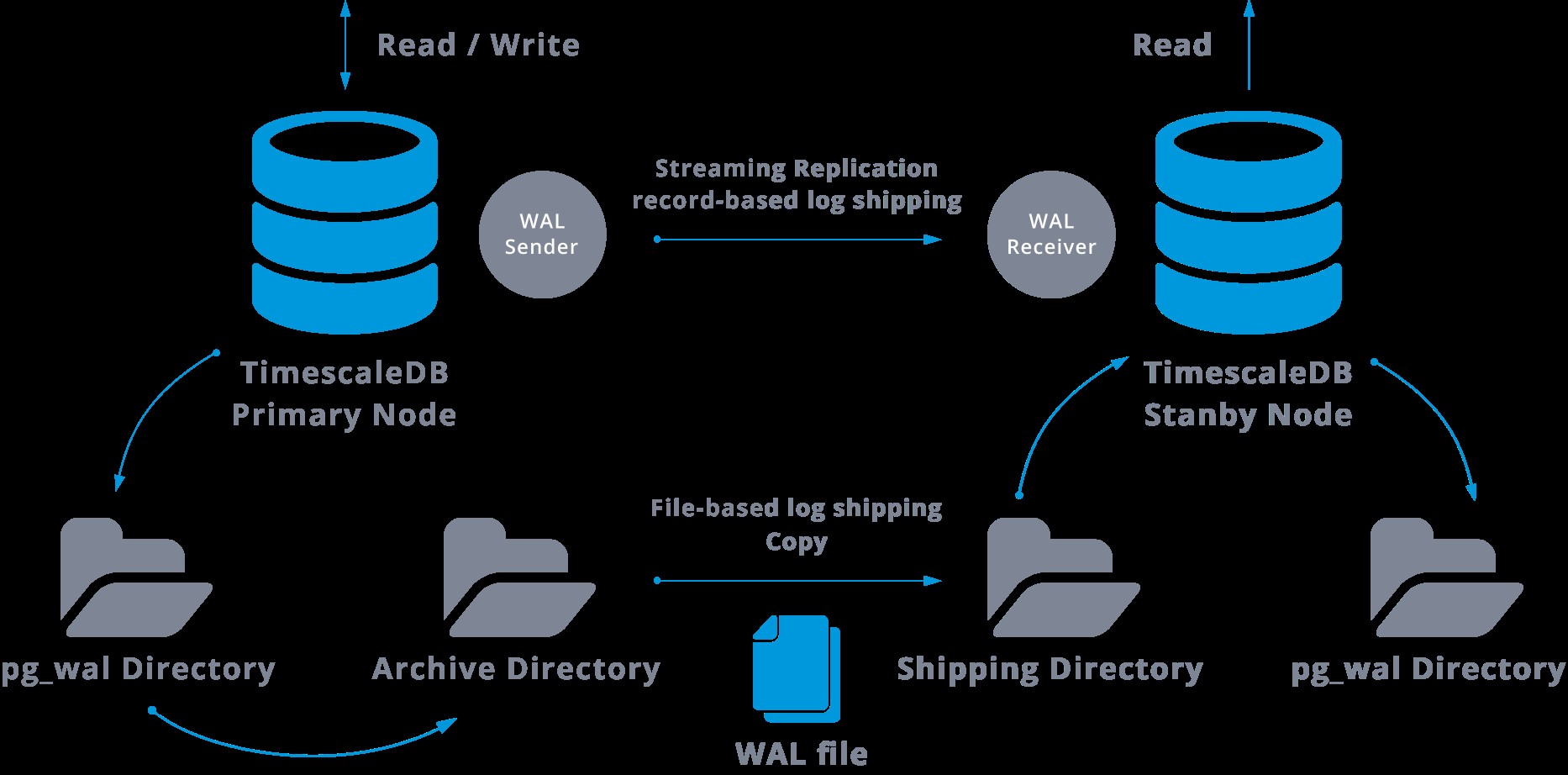
ストリーミングレプリケーションはデフォルトで非同期であるため、ある時点で、マスターでコミットでき、スタンバイサーバーにまだレプリケートされていないトランザクションが発生する可能性があります。これは、潜在的なデータ損失を意味します。
ただし、レプリカサーバーが負荷に対応できるほど強力であると仮定すると、コミットとレプリカの変更の影響との間のこの遅延は非常に小さい(数ミリ秒)と想定されます。
わずかなデータ損失のリスクさえ許容できない場合は、同期レプリケーション機能を使用できます。
同期レプリケーションでは、書き込みトランザクションの各コミットは、コミットがプライマリサーバーとスタンバイサーバーの両方のディスクの先行書き込みログに書き込まれたという確認が受信されるまで待機します。
この方法では、データ損失の可能性を最小限に抑えることができます。その場合、マスターとスタンバイの両方で同時に障害が発生する必要があります。
この構成の明らかな欠点は、すべての関係者が応答するまで待機する必要があるため、各書き込みトランザクションの応答時間が長くなることです。したがって、コミットの時間は、少なくともマスターとレプリカの間のラウンドトリップです。読み取り専用トランザクションはその影響を受けません。
同期レプリケーションを設定するには、各スタンバイサーバーでrecovery.confファイルのprimary_conninfoにapplication_nameを指定する必要があります。primary_conninfo='... aplication_name=slaveX'。
また、同期レプリケーションに参加するスタンバイサーバーのリストを指定する必要があります:synchronous_standby_name ='slaveX、slaveY'。
1つまたは複数の同期サーバーをセットアップできます。このパラメーターは、リストされているものから同期スタンバイを選択する方法(FIRSTおよびANY)も指定します。
ストリーミングレプリケーションセットアップ(同期または非同期)でTimescaleDBを展開するには、ここに示すようにClusterControlを使用できます。
レプリケーションを構成し、稼働させたら、監視とバックアップ管理のためのいくつかの追加機能が必要になります。 ClusterControlを使用すると、外部ツールを使用せずに、同じ場所からTimescaleDBクラスターのバックアップ/保持を監視および管理できます。
TimescaleDBでストリーミングレプリケーションを構成する方法
ストリーミングレプリケーションの設定は、いくつかの手順を完全に実行する必要があるタスクです。手動で構成する場合は、このトピックに関するブログをフォローしてください。
ただし、現在のTimescaleDBをClusterControlにデプロイまたはインポートしてから、数回クリックするだけでストリーミングレプリケーションを構成できます。どうすればそれができるか見てみましょう。
このタスクでは、TimescaleDBクラスターがClusterControlによって管理されていることを前提としています。 ClusterControl-> Select Cluster-> Cluster Actions-> AddReplicationSlaveに移動します。
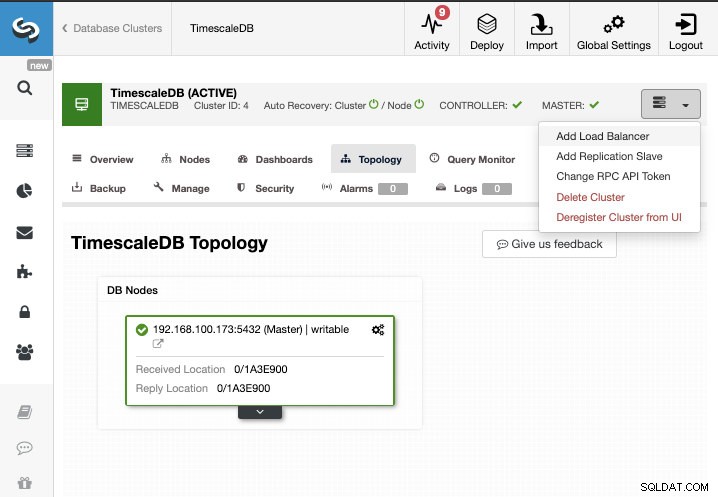
新しいレプリケーションスレーブ(スタンバイ)を作成することも、既存のレプリケーションスレーブをインポートすることもできます。この場合、新しいものを作成します。
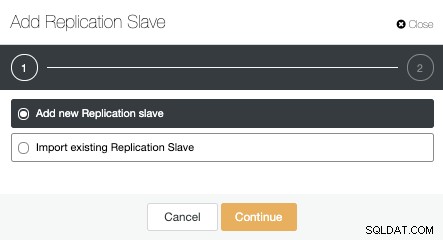
次に、マスターノードを選択し、新しいスタンバイサーバーのIPアドレスまたはホスト名、およびデータベースポートを追加する必要があります。 ClusterControlにソフトウェアをインストールするかどうか、および同期または非同期のストリーミングレプリケーションを構成するかどうかを指定することもできます。
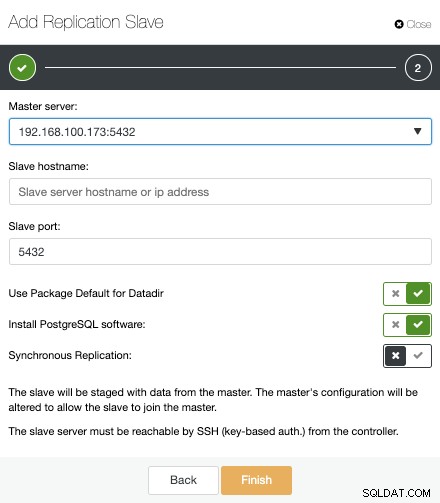
それで全部です。 ClusterControlがジョブを終了するまで待つ必要があるだけです。アクティビティセクションからステータスを監視できます。
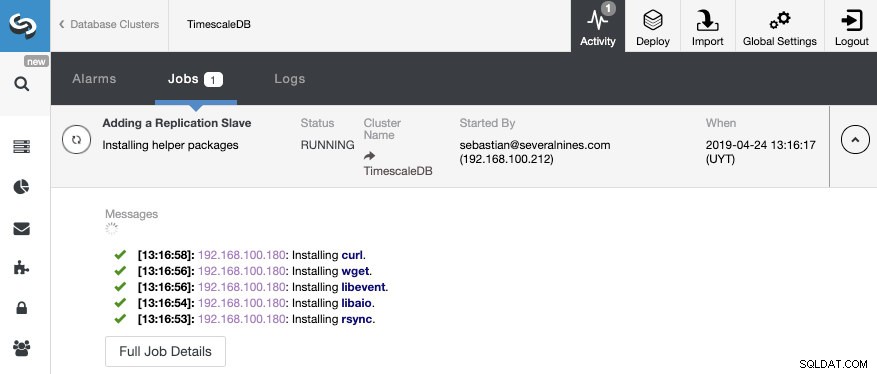
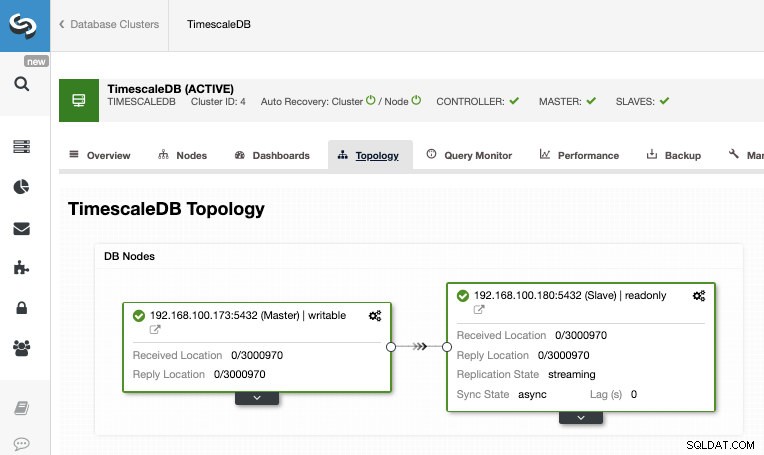
ジョブが終了したら、ストリーミングレプリケーションを構成し、ClusterControlトポロジビューセクションで新しいトポロジを確認できます。
ClusterControlを使用すると、バックアップ、監視とアラート、自動フェイルオーバー、ノードの追加、ロードバランサーの追加など、TimescaleDBでいくつかの管理タスクを実行することもできます。
フェイルオーバー
ご覧のとおり、TimescaleDBは、先行書き込みログ(WAL)レコードのストリームを使用して、スタンバイデータベースの同期を維持します。メインサーバーに障害が発生した場合、スタンバイにはメインサーバーのほぼすべてのデータが含まれ、すぐに新しいマスターデータベースサーバーにすることができます。これは同期または非同期にすることができ、データベースサーバー全体に対してのみ実行できます。
高可用性を効果的に確保するには、マスタースタンバイアーキテクチャを用意するだけでは不十分です。また、何らかの自動形式のフェイルオーバーを有効にする必要があるため、何かが失敗した場合でも、通常の機能を再開する際の遅延を最小限に抑えることができます。
TimescaleDBには、マスターデータベースの障害を識別し、所有権を取得するようにスレーブに通知する自動フェイルオーバーメカニズムが含まれていないため、DBA側で少し作業が必要になります。また、サーバーは1つしか機能しないため、マスタースタンバイアーキテクチャを再作成する必要があります。これにより、問題が発生する前と同じ通常の状況に戻ります。
ClusterControlには、TimescaleDBの自動フェイルオーバー機能が含まれており、高可用性環境での平均修復時間(MTTR)を改善します。障害が発生した場合、ClusterControlは最も高度なスレーブをマスターに昇格させ、残りのスレーブを再構成して新しいマスターに接続します。 HAProxyは、アプリケーションに単一のデータベースエンドポイントを提供するために自動的にデプロイすることもできるため、マスターサーバーの変更による影響を受けません。
制限
関連リソースTimescaleDBのClusterControlTimescaleDBPostgreSQLストリーミングレプリケーションを簡単にデプロイする方法-詳細ストリーミングレプリケーションを使用する場合、いくつかのよく知られた制限があります:
- 別のバージョンやアーキテクチャに複製することはできません
- スタンバイサーバーでは何も変更できません
- 複製できるものについては、細分性があまりありません
したがって、これらの制限を克服するために、論理レプリケーション機能があります。このレプリケーションタイプの詳細については、次のブログを確認してください。
結論
マスタースタンバイトポロジには、分析、バックアップ、高可用性、フェイルオーバーなど、さまざまな用途があります。いずれの場合も、ストリーミングレプリケーションがTimescaleDBでどのように機能するかを理解する必要があります。また、すべてのクラスターを管理し、このトポロジーを簡単な方法で作成できるようにするシステムがあると便利です。このブログでは、ClusterControlを使用してそれを実現する方法を確認し、ストリーミングレプリケーションに関するいくつかの基本的な概念を確認しました。