以前のブログで、同僚と私は、パフォーマンスの監視、クラスターの管理と展開、バックアップの実行、さらにはTimescaleDBの自動フェイルオーバーを有効にする方法を紹介しました。
このブログでは、いくつかの簡単な手順で、単一のTimescaleDBインスタンスをマルチノードクラスターにスケーリングする方法を紹介します。
一般的なセットアップ、CentosOSで実行される単一ノードインスタンスから始めます。ノードは稼働中であり、ClusterControlによってすでに監視および管理されています。
TimescaleDBインスタンスをデプロイまたはインポートする方法を知りたい場合は、同僚のSebastianInsaustiが書いたブログ「TimescaleDBを簡単にデプロイする方法」を確認してください。
セットアップは次のようになります...
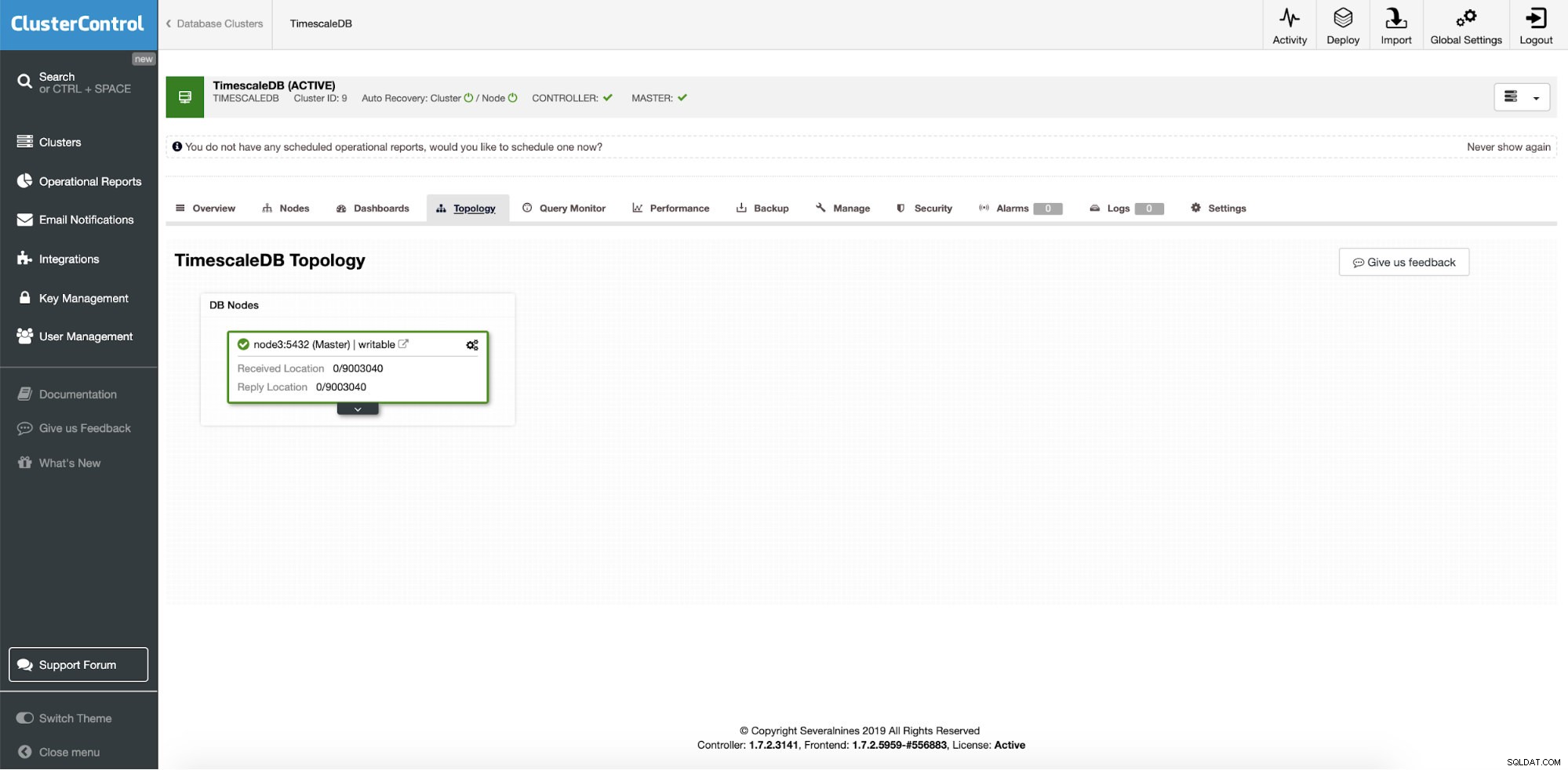 ClusterControl:単一インスタンスTimescaleDB
ClusterControl:単一インスタンスTimescaleDB したがって、これは単一の本番インスタンスであり、ダウンタイムのないクラスターに変換したいと考えています。私たちの主な目標は、アプリケーションの読み取り操作を他のマシンに拡張し、サーバーのクラッシュを書き込むときにそれらをステージングHAサーバーとして使用するオプションを提供することです。
ノードを増やすと、アプリケーションのメンテナンスのダウンタイムも削減されます。ローリングリスタートモードで適用されるパッチのように、他のノードがデータベース接続を提供している間に、一度に1つのノードにパッチが適用されます。
最後の要件は、新しいクラスターに単一のアドレスを作成して、新しいノードが1か所からアプリケーションに表示されるようにすることです。

アクションプランを2つの主要なステップに要約できます。
- レプリカ読み取りの追加
- Haproxyをインストールして設定する
レプリカ読み取りの追加
クラスタアクションに移動して[レプリケーションスレーブの追加]を選択すると、新しいレプリカを最初から作成するか、既存のTimescaleDBデータベースをレプリカとして追加できます。
 ClusterControl:レプリケーションスレーブを追加します
ClusterControl:レプリケーションスレーブを追加します 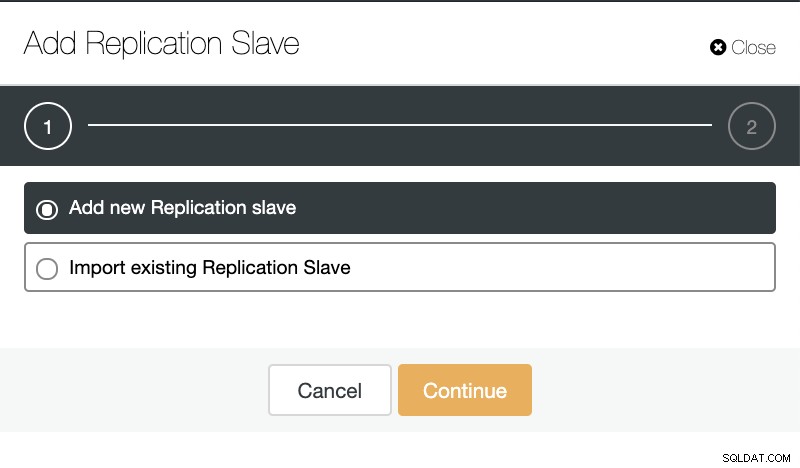 ClusterControl:新しいレプリケーションスレーブを追加し、既存のレプリケーションスレーブをインポートします
ClusterControl:新しいレプリケーションスレーブを追加し、既存のレプリケーションスレーブをインポートします 下の画像でわかるように、マスターサーバーを選択し、新しいスレーブサーバーのIPアドレスとデータベースポートを入力するだけです。
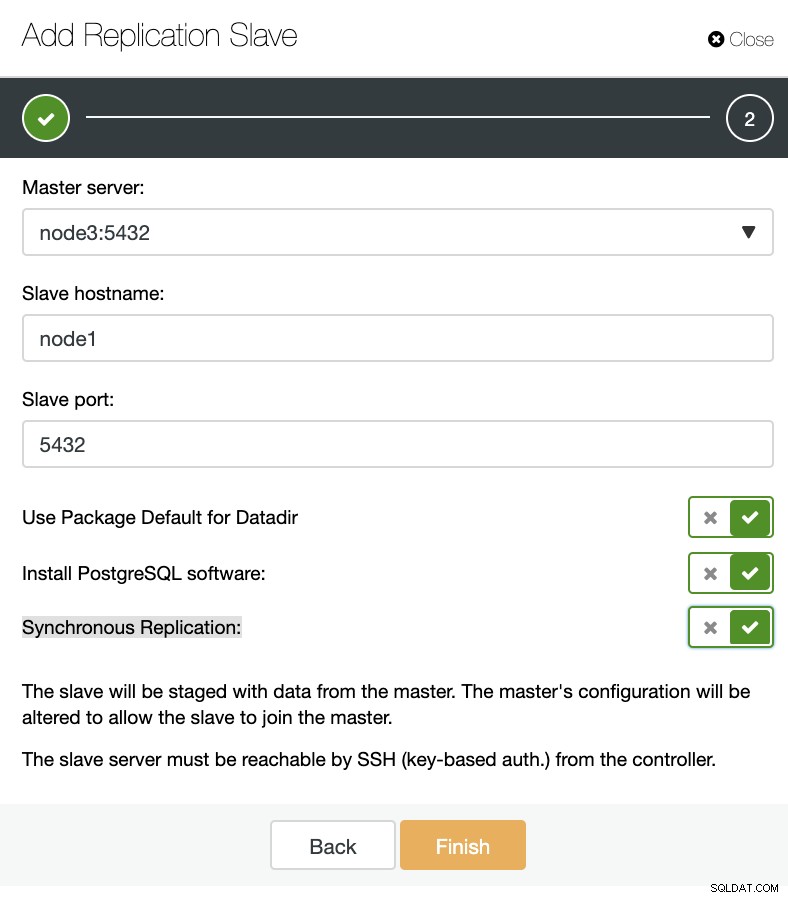 ClusterControl:レプリケーションスレーブを追加します
ClusterControl:レプリケーションスレーブを追加します 次に、ClusterControlにソフトウェアをインストールさせるかどうか、およびレプリケーションスレーブを同期にするか非同期にするかを選択できます。既存のスレーブサーバーをインポートする場合は、次のようにインポートオプションを使用できます。
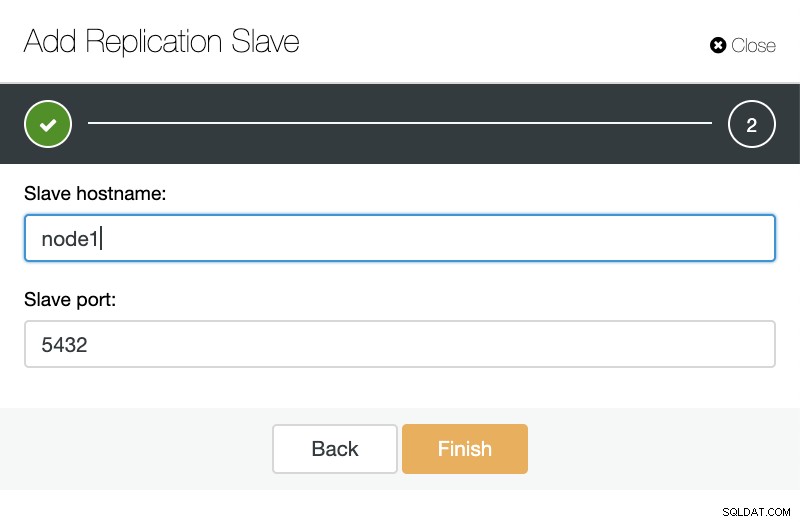 ClusterControl:TimescaleDBのレプリケーションスレーブをインポートします
ClusterControl:TimescaleDBのレプリケーションスレーブをインポートします どちらの方法でも、必要な数のレプリカを追加できます。この例では、2つのノードを追加します。 CusterControlは内部ジョブを作成し、必要なすべてのステップを一度に1つずつ実行します。
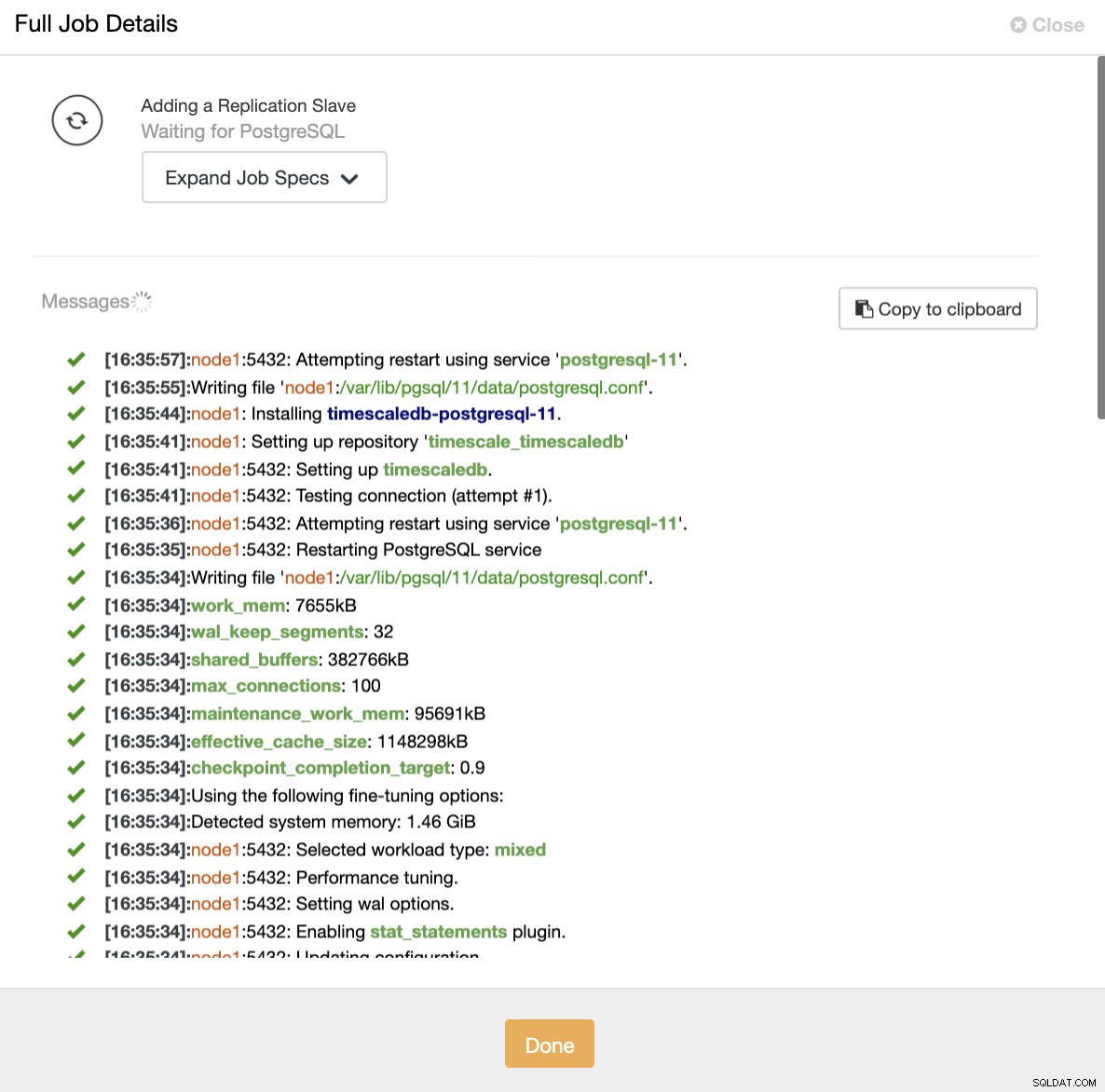 ClusterControl:リードレプリカを追加
ClusterControl:リードレプリカを追加 TimescaleDBへのロードバランサーの追加
この時点で、別の場所にレプリケーションスレーブノードを追加することを選択した場合、データは複数のノードまたはデータセンターに分散されます。クラスタは、2つの追加のリードレプリカノードでスケールアウトされます。
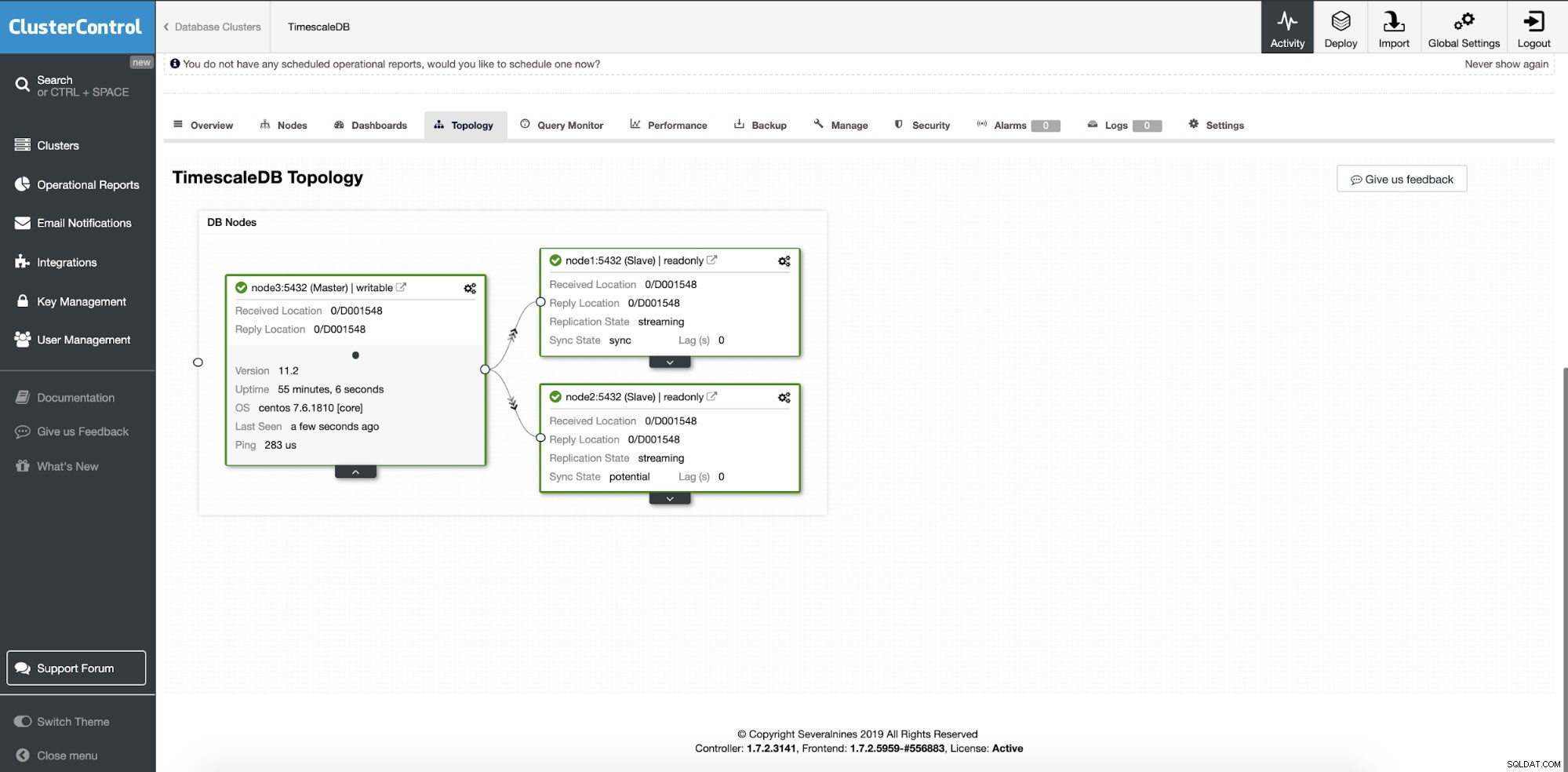 ClusterControl:2つのノードが追加されました
ClusterControl:2つのノードが追加されました 問題は、アプリケーションがどのデータベースノードにアクセスするかをどのように知るかということです。書き込みおよび読み取り操作には、HAProxyとさまざまなポートを使用します。
TimescaleDBクラスターから、コンテキストメニューでロードバランサーの追加を選択します。

次に、Haproxyをインストールするサーバーの場所、データベース接続に使用するポリシー、およびHaproxy構成に参加するノードを指定する必要があります。
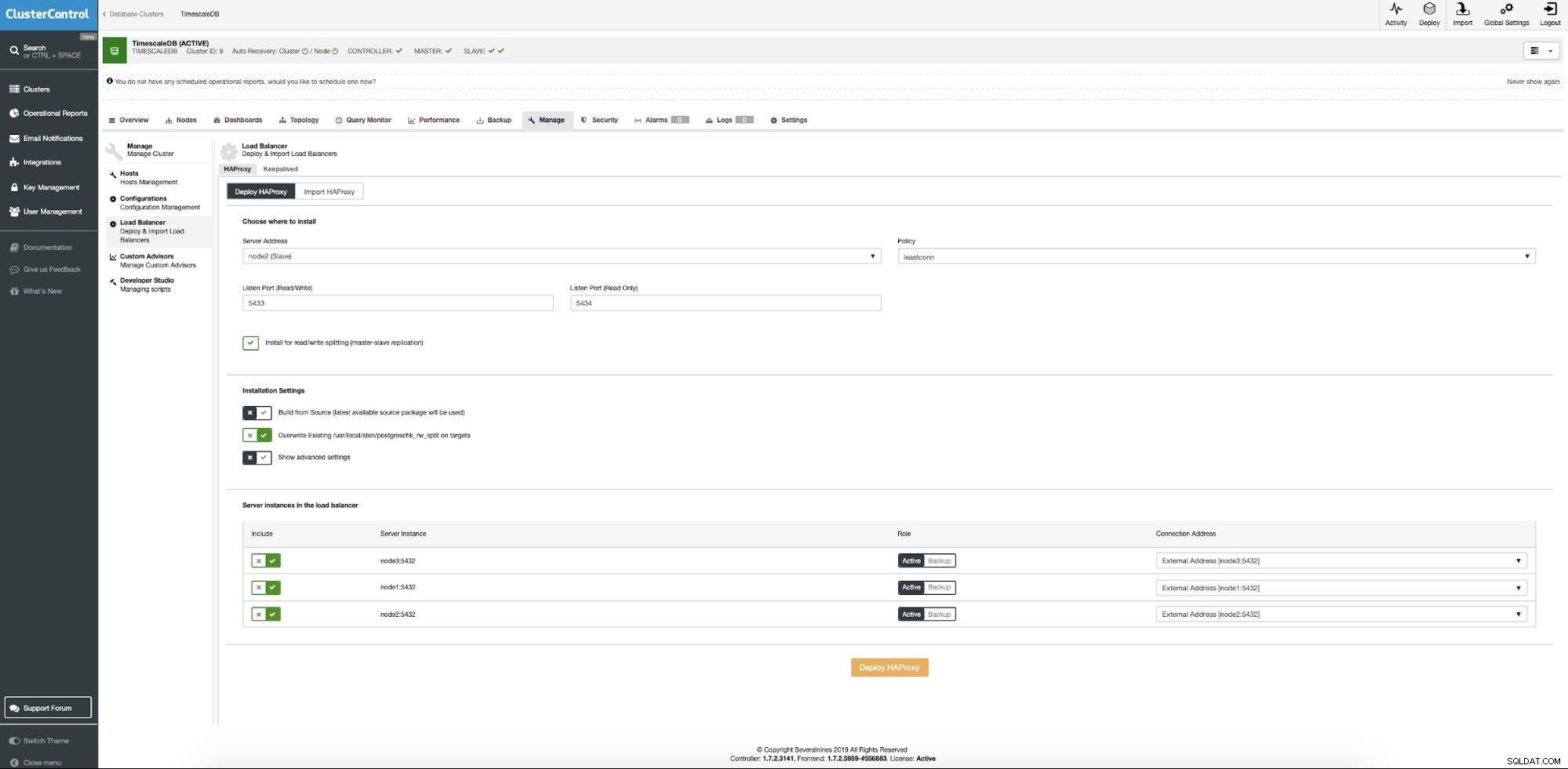
すべてが設定されたら、デプロイボタンを押します。数分後、クラスター構成の準備が整います。 ClusterControlは、ロードバランサーをデプロイするためのすべての前提条件と構成を処理します。
展開が成功すると、新しいクラスターのトポロジを確認できます。負荷分散と追加の読み取りノードを使用します。より多くのノードが搭載されているため、ClusterControlは自動的に自動回復を有効にします。このように、マスターノードがダウンすると、フェイルオーバー操作が自動的に開始されます。
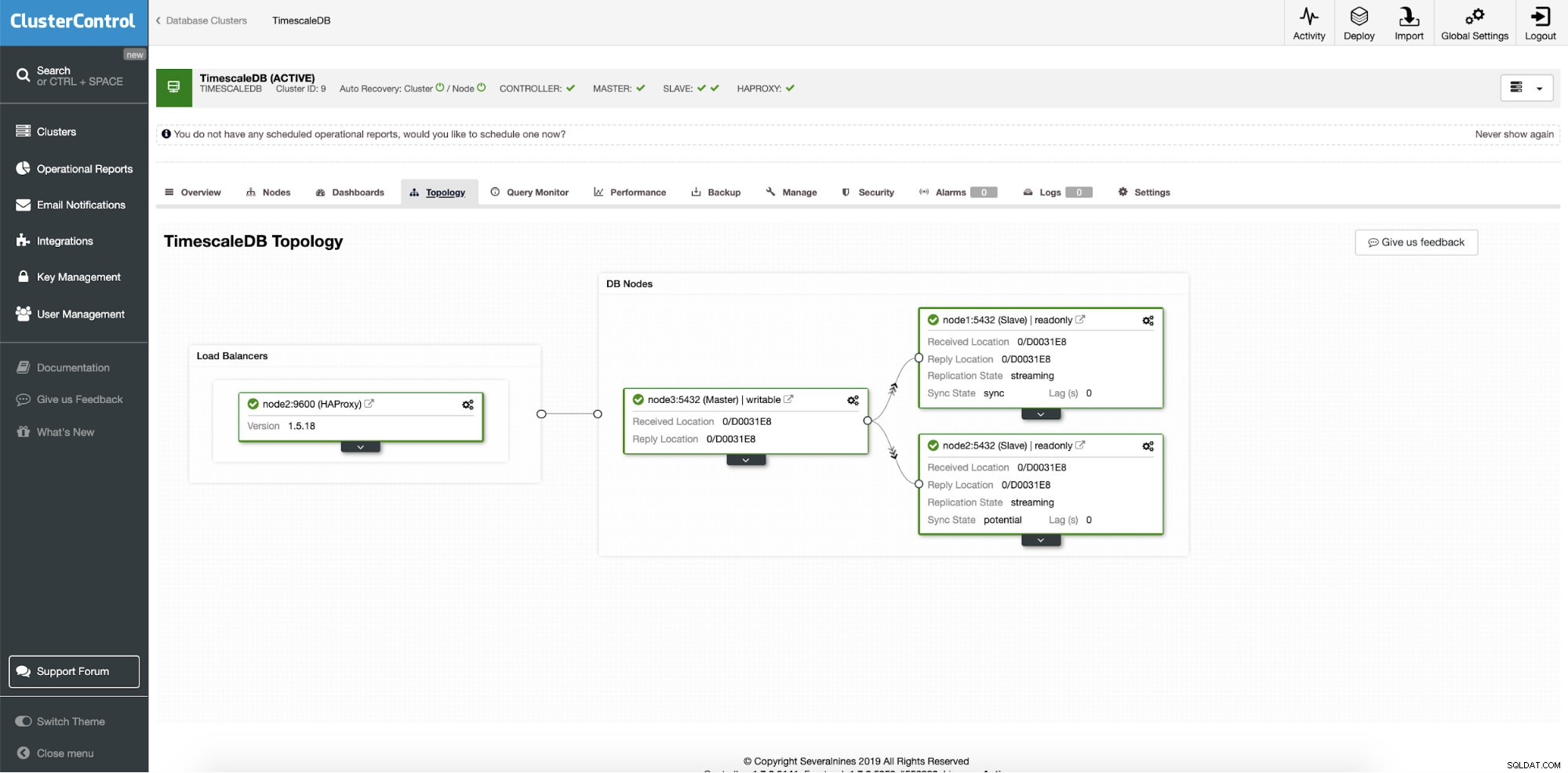 ClusterControl:最終トポロジ
ClusterControl:最終トポロジ 結論
TimescaleDBは、SQLを時系列データに対してスケーラブルにするために発明されたオープンソースデータベースです。クラスタを拡張する自動化された方法を持つことは、パフォーマンスと効率を達成するための鍵です。上で見たように、ClusterControlを使用してTimescaleDBを簡単にスケーリングできるようになりました。