TimescaleDBは、SQLを時系列データに対してスケーラブルにするために発明されたオープンソースデータベースです。これは比較的新しいデータベースシステムです。 TimescaleDBは2年前に市場に導入され、2018年9月にバージョン1.0に到達しました。それでも、成熟したRDBMSシステム上で設計されています。
TimescaleDBはPostgreSQL拡張機能としてパッケージ化されています。タイムスケールライセンス(TSL)の下でライセンスされた時系列エンタープライズ機能に関連する一部のソースコードを除いて、すべてのコードはApache-2オープンソースライセンスの下でライセンスされています。
時系列データベースとして、日付とキーの値を自動的に分割します。 TimescaleDBのネイティブSQLサポートは、時系列データの保存を計画していて、SQL言語に関する確かな知識をすでに持っている人に適したオプションです。
豊富なSQL、HA、堅牢なバックアップソリューション、レプリケーション、およびその他のエンタープライズ機能を使用できる時系列データベースをお探しの場合は、このブログが正しい道を歩む可能性があります。
TimescaleDBを使用する場合
TimescaleDBの機能を開始する前に、それがどこに適合するかを見てみましょう。 TimescaleDBは、時系列に重点を置いて、リレーショナルとNoSQLの両方の長所を提供するように設計されています。しかし、時系列データとは何ですか?
時系列データは、モノのインターネット、監視システム、および頻繁に変更されるデータに焦点を当てた他の多くのソリューションの中核です。 「時系列」という名前が示すように、私たちは時間とともに変化するデータについて話しています。このようなタイプのDBMSの可能性は無限大です。これは、製造、鉱業、石油およびガス、小売、ヘルスケア、開発監視、または金融情報セクターにわたるさまざまな産業用IoTユースケースで使用できます。また、機械学習パイプラインに、またはビジネスオペレーションとインテリジェンスのソースとして非常に適合します。
IoTなどのソリューションの需要が高まることは間違いありません。そうは言っても、さまざまな方法でデータを分析および処理する必要があると予想される場合もあります。通常、時系列データは追加されるだけです。古いデータを更新する可能性はほとんどありません。通常、特定の行を削除することはありませんが、時間の経過に伴うデータのある種の集約が必要になる場合があります。データが時間とともにどのように変化するかを保存するだけでなく、データを分析して学習したいと考えています。
新しいタイプのデータベースシステムの問題は、通常、独自のクエリ言語を使用することです。ユーザーが新しい言語を学ぶには時間がかかります。 TimescaleDBと他の一般的な時系列データベースの最大の違いは、SQLのサポートです。 TimescaleDBは、時間ベースの集計、結合、サブクエリ、ウィンドウ関数、セカンダリインデックスなど、SQL機能の全範囲をサポートしています。さらに、アプリケーションですでにPostgreSQLを使用している場合は、クライアントコードに変更を加える必要はありません。
アーキテクチャの基本
TimescaleDBはPostgreSQLの拡張機能として実装されています。つまり、タイムスケールデータベースはPostgreSQLインスタンス全体で実行されます。拡張モデルを使用すると、データベースは、信頼性、セキュリティ、さまざまなサードパーティツールへの接続など、PostgreSQLの多くの属性を利用できます。同時に、TimescaleDBは、PostgreSQLのクエリプランナー、データモデル、実行エンジンの奥深くにフックを追加することで、拡張機能で利用できる高度なカスタマイズを活用しています。
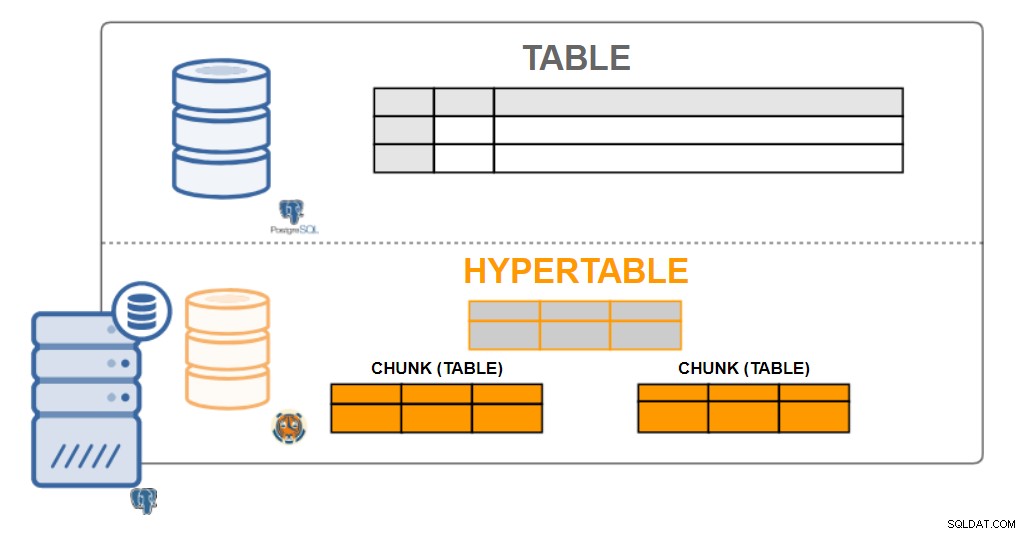 TimescaleDBアーキテクチャ
TimescaleDBアーキテクチャ Hypertables
ユーザーの観点からは、TimescaleDBデータはハイパーテーブルと呼ばれる単一のテーブルのように見えます。ハイパーテーブルは、チャンクと呼ばれるデータを保持する多くの個々のテーブルの概念または暗黙のビューです。ハイパーテーブルのデータは、1次元または2次元のいずれかです。時間間隔、および(オプションの)「パーティションキー」値で集計できます。
事実上、TimescaleDBとのすべてのユーザーインタラクションはハイパーテーブルを使用します。テーブルの作成、インデックス、テーブルの変更、データの選択、データの挿入...はすべてハイパーテーブルで実行する必要があります。
TimescaleDBは、単一ノード展開とクラスター化展開(開発中)の両方でこの広範なパーティショニングを実行します。パーティショニングは、従来、複数のマシン間でスケールアウトするためにのみ使用されていましたが、単一のマシンでも高い書き込みレート(および改善された並列クエリ)にスケールアップすることもできます。
リレーショナルデータのサポート
リレーショナルデータベースとして、SQLを完全にサポートしています。 TimescaleDBは、さまざまなユースケースに最適化できる柔軟なデータモデルをサポートしています。これにより、Timescaleは他のほとんどの時系列データベースとは多少異なります。 DBMSは、PostgreSQLに基づいて、高速な取り込みと複雑なクエリ用に最適化されており、必要に応じて、堅牢な時系列処理にアクセスできます。
インストール
TimescaleDBはPostgreSQLと同様に、Ubuntu、Debian、RHEL / Centos、Windows、クラウドプラットフォームへのインストールなど、さまざまなインストール方法をサポートしています。
TimescaleDBを操作する最も便利な方法の1つは、Dockerイメージです。
以下のコマンドは、Docker Hubがまだインストールされていない場合はDockerイメージをプルし、実行します。
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledb最初の使用
インスタンスが稼働しているので、最初のtimescaledbデータベースを作成します。以下に示すように、標準のPostgreSQLコンソールを介して接続するため、PostgreSQLクライアントツール(psqlなど)がローカルにインストールされている場合は、それらを使用してTimescaleDBdockerインスタンスにアクセスできます。
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;日常業務
使用と管理の両方の観点から、TimescaleDBはPostgreSQLのように見え、感じられ、そのように管理および照会できます。
日常業務の主な箇条書きは次のとおりです。
- PostgreSQLサーバー上で他のTimescaleDBおよびPostgreSQLデータベースと共存します。
- インターフェイス言語としてSQLを使用します。
- バックアップ、コンソールなどのサードパーティツールへの一般的なPostgreSQLコネクタを使用します。
TimescaleDB設定
PostgreSQLのすぐに使用できる設定は、通常、最新のサーバーやTimescaleDBには保守的すぎます。 timescaledb-tuneを使用するか、手動で行うことにより、postgresql.conf設定が調整されていることを確認する必要があります。
$ timescaledb-tuneスクリプトは、変更を確認するように求めます。これらの変更はpostgresql.confに書き込まれ、再起動時に有効になります。
それでは、TimescaleDBチュートリアルの基本的な操作をいくつか見てみましょう。これにより、新しいデータベースシステムの操作方法を理解できます。
ハイパーテーブルを作成するには、通常のSQLテーブルから始めて、関数create_hypertableを使用してハイパーテーブルに変換します。
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);ハイパーテーブルへの変換は次のように簡単です。
SELECT create_hypertable('conditions', 'time');ハイパーテーブルへのデータの挿入は、通常のSQLコマンドを介して行われます。
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);データの選択は、古き良きSQLです。
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;以下に示すように、group by、order by、および関数を実行できます。さらに、TimescaleDBには、バニラPostgreSQLには存在しない時系列分析用の関数が含まれています。
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;