自分自身や組織の多くのお金、時間、問題を節約するには、データモデリングが必要です。データモデルがどのように魔法をかけるかを知るために読んでください。
データモデリングは、データベースに含まれる、または含まれるべき情報の概念的なビューを作成するプロセスです。このプロセスの結果として、データモデルが作成され、データオブジェクト(情報が格納されるすべてのエンティティ)、それらの間の関連付けまたは関係、およびデータベースに入力される情報を管理するルールまたは制限が形成されます。 。
とてもいいですが、データモデルを操作する必要が本当にありますか?この手順をスキップして時間を節約し、データベースにオブジェクトを直接作成することはできませんか?データベースモデリングのコースでこれらの質問に答えることができますが、要約が必要な場合は、データベースに保存されている情報を操作する必要があるときはいつでも、データモデルを手元に用意する十分な理由を説明します。この記事を読み終える頃には、適切なモデルなしでデータベースを操作することは、適切な基盤なしで家を建てたり、超高層ビルを建てたりすることと同じであることに同意するでしょう。
まず、データモデリングが主に行われる2つのコンテキストについて考えてみましょう。
- 戦略的モデリング。これは、組織の一般的な情報システム戦略の一部として実行されます。
- データベース設計。これは、ソフトウェア開発プロセスの設計フェーズの一部です。
どちらの状況でも、データモデリングを行う理由はたくさんあります。最初に、情報システム戦略に関係するもの、次にソフトウェア開発に関係するものを見ていきます。
より高い情報品質
メタデータで明確さと一貫性を提供するには、データモデルが不可欠です。 、データベースを構成するオブジェクトの定義。これは、情報品質の向上に貢献します。たとえば、データモデルでは、電話番号やZIPコードなどのデータ要素に正しい形式が使用されていることを確認できます。また、顧客データが保存されているデータベースでは、各顧客が少なくとも1つの住所を持っていることを確認できます。
>有効なデータのみがテーブルに入力されるようにルールを適用することにより、データベースに格納されている情報の品質を保証することもできます。データモデルを設計するときにこれを行うには、各フィールドに値ドメインを設定し、値が必要なフィールドと空のままにしておくことができるフィールドを区別します。
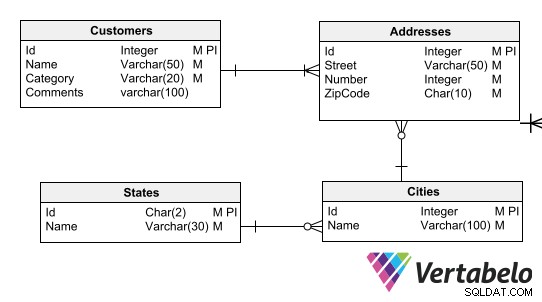
データモデル定義により、ビジネスルール。たとえば、各クライアントに正しい郵便番号形式の住所を設定したり、各住所を都市に関連付けたり、各都市を州に関連付けたりすることができます。
情報の品質は、参照整合性を確保し、エンティティ間の関係で意図されたカーディナリティを維持する制限を課すことによっても改善されます。これらの制限は、適切なデータモデルからのみ導き出すことができます。
データ資産の再利用
新しいシステムを開発したり、既存のシステムに新しい機能を追加したりする場合、新しい開発に必要なデータエンティティの一部はデータベースにすでに存在しているため、再利用できるのが一般的です。すでに存在するエンティティを見つける唯一の方法は、組織で使用されているデータベースの構造を適切に記述した最新のデータモデルを参照することです。
再利用可能なデータ資産を簡単に検出できるように、さまざまなレベルの抽象化を備えたビューを提供するために、概念的、論理的、および物理的なデータモデルを維持する必要があります。 Vertabeloプラットフォームなどの特殊な設計ツールを活用して、さまざまなタイプのデータモデルの作成を容易にし、さらには別のモデルから派生させることもできます。
このグッドプラクティスは、異なるスキーマで冗長データを生成することを回避します。これにより、遅かれ早かれ情報の一貫性が失われます(これについては以下で詳しく説明します)。
クラウド環境への移行
クラウド内のDaaS(Data as a Service)インフラストラクチャまたはデータベースでは、データベースのプライバシーなどの特定の要件 、動的スケーラビリティ 、および複数のテナントの管理効率 、より重要になります。
データモデルは、スキーマ設計がそれらに準拠していることの検証を容易にするため、これらの要件を満たすための非常に貴重なツールです。次に、スキーマのパーティションとそのストレージ要件を定義できます。これは、データベースがプライベートクラウドまたはパブリッククラウドに存在する場合に必要なサービスレベルと予想されるストレージの増加を適切に評価するために不可欠です。
ERダイアグラムなどのデータベース設計アーティファクトは、クラウド環境への移行の準備をするときに選択するツールです。 ERダイアグラムの使用方法に関するガイドでは、データベースの移行におけるERダイアグラムの有用性を垣間見ることができます。
ビッグデータとNoSQLのデータベースモデリング
NoSQLや次元スキーマなどの非リレーショナルデータベースは、従来のリレーショナルマインドセットを(少なくともしばらくの間)脇に置くことを余儀なくされる可能性があります。しかし、それはデータモデルなしでできるという意味ではありません。それどころか、データモデリングはさらに重要になります。
ビッグデータを操作する必要がある場合、通常、情報の巨大なサイロに直面します。これらの情報は、自分またはデータアナリストがそこから戦略的な洞察を得ることができるように、分解、改良、および構造化する必要があります。洗練された情報リポジトリまたはデータウェアハウスと、データクレンジングおよびデータ構造化プロセスに使用されるステージングリポジトリの両方で、慎重なスキーマ設計が必要です。
NoSQLデータベースはスキーマを使用しないため、データモデルを必要としないという誤解が主にプログラマーによってあります。真実から遠く離れたものはありません。 NoSQLテクノロジーはメタデータを表示するための標準化された方法を提供しないため(すべてのRDBMSが行うこと)、データベースに保存されている情報を人々が使用および共有できるようにするためにデータモデルが不可欠になります。
合併と買収
2つの組織間の合併は、それぞれのIT部門に大きな課題をもたらします。この課題の重要な部分は、データベースの統合です。両方の組織が最新のデータモデルを使用している場合、この統合はデータベースで直接行うのではなく、モデルで行うことができるため、タスクに費やす労力が大幅に削減されます。
これまで、組織のIT戦略計画に関連するデータモデリングの利点を見てきました。これらの理由でデータモデリングの重要性を納得させるのに十分でない場合は、それがソフトウェア開発にもたらすメリットも見てみましょう。
開発コストの削減
予算が分析されている開発プロジェクトの初期段階では、データモデルの構築に力を注ぐ必要性が疑問視される可能性があります。プロジェクトリーダーとマネージャーが十分に賢い場合は、データモデルの構築と維持にかかる費用と、節約される費用を比較して、モデルの構築に賛成することを決定します。
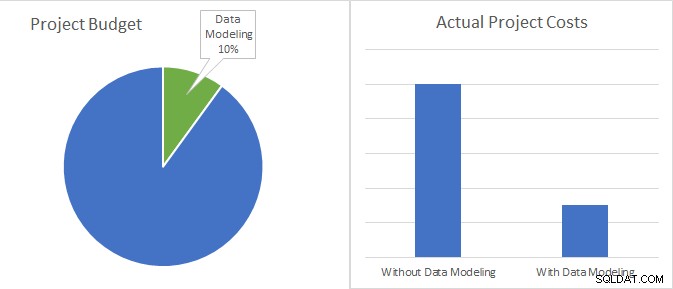
データモデリングはわずか10%です開発プロジェクトの予算の3分の1未満に実際のプロジェクトのコストを削減する可能性があります。
次のことを考慮してください。ほとんどの場合、データモデリングのコスト(つまり、モデルの構築と保守に必要な労力のコスト)は、ソフトウェアプロジェクトの総予算の10%未満です。比較すると、データモデルの使用に関連するコスト削減は、コーディングとメンテナンスの時間の短縮により、最大70%です。
したがって、ソフトウェア開発において、データモデリングを行う最初の最も重要な理由は、疑う余地のないROI(投資収益率)です。これは、プロジェクトリーダーがすべてのプロジェクトの初期段階で考慮する必要があります。
要件のより良い定義
ソフトウェア開発では、データモデリングアクティビティが要件の収集と並行して実行される場合、開発されるシステムの理解を深めることができます。要件はより完全で正確になります。
データモデリングは、データの整合性を確保しながら、要件エンジニアリング中にビジネスルールを明らかにし、質問をするのに役立ちます。ユースケースの設計やワークフローの設計などのプロセスモデリングアクティビティよりも効果的であり、ビジネスルールの散文の説明よりも明らかに表現力があり、冗長性が低くなります。
より迅速な開発
開発者が適切なデータモデルを手元に持っている場合、開発者はより少ないエラーで仕事をすることができます。データモデリングツールは、データベーススキーマを自動的に生成および維持し、開発者が手動で生成するには長すぎ、複雑で、面倒なデータ定義言語(DDL)スクリプトを作成します。
次に、これらのツールは、モデルを開発者間で共有できるようにすることでコラボレーションを促進します。変更が必要な場合は、データモデルで変更を加えて、すべての開発者に通知し、何も壊さずにデータベースに適用できるようにすることができます。
これらすべてにより、システムをより早く、より少ないバグで提供できます。
アジャイル手法の強化
アジャイル方法論は、実用的なソフトウェアの提供に注力し、官僚主義、過剰な文書化、および次々に実行されるフェーズを回避することにより、開発プロセスをスピードアップすることを目的としています。
アジャイル環境で作業する場合、データベースモデリングは大きな課題に直面します。設計者は「全体像」に取り組む必要があり、開発者は各ユーザーストーリーに必要なデータオブジェクトのみを必要とするからです。データモデラーと開発者の間でコンセンサスを得るには、アジャイル手法でサンドボックスなどの手法を使用します。 および分岐 。
サンドボックスは、各開発者の作業環境です。設計者は、各開発者のサンドボックス内のメインデータモデルのブランチを操作できます。開発者は、フィードバックを提供してモデルを改良します。各段階(またはスプリント)の終わりに、データベース設計者はさまざまなブランチをマージして、完全なモデルを最新の状態に保ちます。
データモデリングはアジャイルチームの速度を低下させ、開発者はモデルが作業を開始する準備ができるまで待たなければならないと思うかもしれません。しかし実際には、サンドボックス化や分岐などの手法を使用すると、敏捷性の原則が維持され、同時に上記の速度の向上が達成されます。
データモデルを使用しない場合はどうなりますか?
時間を節約するために、これまでに説明したデータモデルの利点がなくても生き残ることができると思うかもしれません。ただし、データモデリングに反対する場合は、次のような深刻な問題が発生するリスクがあります。
- 不要な冗長性:データオブジェクトを明確に表示するモデルがないため、同じオブジェクトの異なるバージョンが異なる情報で表示されます。たとえば、在庫システムは先月500ユニットのアイテムが販売されたと報告し、ロジスティクスシステムは同じ期間に1000ユニットのアイテムが出荷されたと報告する場合があります。どちらが正しいですか?誰が知っている。
- アプリの動作が遅い:データモデルがないため、最適化タスクが難しくなり、アプリケーションの応答性が低下します。
- 品質基準を満たせない:データモデルがない場合、データベースは文書化されません。これは、データベースの移行などのシナリオでは必須です。
- ソフトウェアの品質が低い:ソフトウェア開発の要件が低く、ユーザーは必要なアプリケーションや必要なアプリケーションを利用できません。
- より高い開発コスト:データモデルを使用することで開発プロジェクトで達成できる大幅なコスト削減については、すでに説明しました。それらを使用しないことを選択した場合は、追加の開発および保守コストを誰が支払うかを決定する必要があります。そして、締め切りに間に合わなかったときに誰が言い訳をするのか。
まだ納得できませんか?
これまで読んだ内容だけではデータモデリングの重要性を納得させることができない場合は、データがあらゆる種類の組織にとってますます価値のある資産になりつつあることを忘れないでください。情報を活用するための構造のモデル化は、今日では前例のない関連性を持っています。
これを考えてみてください。ゴールドラッシュの最中に最も多くのお金を稼いだのは、金塊を掘る人ではなく、金を抽出するためのツールを提供する人でした。 2021年には、金のナゲットは洞察に満ちた情報の形で提供され、そのような貴重な資料を抽出する鉱夫にはデータモデルを提供する必要があります。