JeffAtwoodとJoeCelkoは、GUIDのコストは大したことではないと考えているようですが(Jeffのブログ投稿「PrimaryKeys:IDs vs GUIDs」、および「Identity Vs.Uniqueidentifier」というタイトルのこのニュースグループスレッドを参照)、他の専門家–より具体的には、SQL Serverスペースに焦点を当てたインデックスとアーキテクチャの専門家は、意見が一致しない傾向があります。たとえば、キンバリー・トリップは、「ディスクスペースは安い-それは重要ではありません!」という投稿で詳細を説明しています。この記事では、影響はディスクスペースと断片化だけでなく、より重要なのはインデックスサイズとメモリにあると説明しています。フットプリント。
キンバリーが言っていることは本当に真実です。私は常にGUIDの「ディスクスペースが安い」という正当化に出くわします(先週の例)。データベースの外部で(場合によっては行が実際に作成される前に)一意の識別子を生成する必要があることや、個別の分散システム間で一意の識別子が必要なこと(およびID範囲が実用的でない場合)など、GUIDには他にも理由があります。しかし、GUIDはそれほどコストがかからないという神話を払拭したいと思います。なぜなら、GUIDはコストがかかるため、これらのコストを考慮して決定する必要があるからです。
私はこのミッションに着手し、同じデータを同じ行数、同じインデックス、ほぼ同じワークロードでテストしました(*正確に*同じワークロードを再生するのは非常に難しい場合があります)。インデックスのサイズやインデックスの断片化などの基本的なものだけでなく、次のようなこれらの影響も測定したかったのです。
- バッファプールの使用への影響
- 「悪い」ページ分割の頻度
- 現実的なワークロード期間への全体的な影響
- 個々のクエリの平均実行時間への影響
- アフタートリガーの実行時間への影響
- tempdbの使用への影響
拡張イベント、デフォルトトレース、tempdb関連のDMV、SQL Sentry Performance Advisorなど、さまざまな手法を使用してこのデータを調査します。
セットアップ
まず、組み込みのSQL Serverメタデータを使用して、シードテーブルに入れる100万人の顧客を作成しました。これにより、「ランダムな」顧客が各テストを通じて同じ自然データで構成されることが保証されます。
CREATE TABLE dbo.CustomerSeeds(rn INT PRIMARY KEY CLUSTERED、FirstName NVARCHAR(64)、LastName NVARCHAR(64)、EMail NVARCHAR(320)NOT NULL UNIQUE、Active BIT); INSERT dbo.CustomerSeeds WITH(TABLOCKX)(rn、FirstName、LastName、EMail、[Active])SELECT rn =ROW_NUMBER()OVER(ORDER BY n)、fn、ln、em、aFROM(SELECT TOP(1000000)fn、ln 、em、a =MAX(a)、n =MAX(NEWID())FROM(SELECT fn、ln、em、a、r =ROW_NUMBER()OVER(PARTITION BY em ORDER BY em)FROM(SELECT TOP(2000000) fn =LEFT(o.name、64)、ln =LEFT(c.name、64)、em =LEFT(o.name、LEN(c.name)%5 + 1)+'。'+ LEFT(c。名前、LEN(o.name)%5 + 2)+'@' + RIGHT(c.name、LEN(o.name + c.name)%12 + 1)+ LEFT(RTRIM(CHECKSUM(NEWID()) )、3)+'.com'、a =CASE WHEN c.name LIKE'%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID())AS x) AS y WHERE r =1 GROUP BY fn、ln、em ORDER BY n)AS z ORDER BY rn; GO SELECT TOP(10)* FROM dbo.CustomerSeeds ORDER BY rn; GO
マイレージは異なる場合がありますが、私のシステムでは、この人口は86秒かかりました。代表的な10行(クリックして拡大):
次に、ユースケースごとにシードデータを格納するためのテーブルと、ある種の現実をシミュレートするためのいくつかの追加のインデックスが必要でした。後ですべての種類の診断を簡単にするために、短いサフィックスを考え出しました。
| データ型 | デフォルト | 圧縮 | ユースケースの接尾辞 |
|---|---|---|---|
| INT | IDENTITY | なし | 私 |
| INT | IDENTITY | ページ+行 | Ic |
| BIGINT | IDENTITY | なし | B |
| BIGINT | IDENTITY | ページ+行 | Bc |
| UNIQUEIDENTIFIER | NEWID() | なし | G |
| UNIQUEIDENTIFIER | NEWID() | ページ+行 | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | なし | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | ページ+行 | Sc |
表1:ユースケース、データ型、サフィックス
8つのテーブルがすべて伝えられ、すべて同じテンプレートから作成されています(ユースケースに一致するようにコメントを変更し、$use_case$を置き換えます 上記の表の適切な接尾辞を付けて):
CREATE TABLE dbo.Customers_ $ use_case $-I、Ic、B、Bc、G、Gc、S、Sc(CustomerID INT NOT NULL IDENTITY(1,1)、--CustomerID BIGINT NOT NULL IDENTITY(1、 1)、-CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID()、-CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID()、FirstName NVARCHAR(64)NOT NULL、LastName NVARCHAR(64)NOT NULL、EMail NVARCHAR(320)NOT NULL、アクティブBIT NOT NULL DEFAULT 1、作成されたDATETIME NOT NULL DEFAULT SYSDATETIME()、更新されたDATETIME NULL、CONSTRAINT C_PK_Customers_ $ use_case $ PRIMARY KEY(CustomerID))--WITH(DATA_COMPRESSION =PAGE)GO; CREATE UNIQUE INDEX C_Email_Customers_ $ use_case $ONdbo。 Customers_ $ use_case $(EMail)--WITH(DATA_COMPRESSION =PAGE); GOCREATE INDEX C_Active_Customers_ $ use_case $ ON dbo.Customers_ $ use_case $(FirstName、LastName、EMail)WHERE Active =1 --WITH(DATA_COMPRESSION =PAGE); GOCREATE INDEX C_Name_Customers_ $ use_case $ ON dbo.Customers_ $ use_case $(LastName、FirstName)INCLUDE(EMail)--WITH(DATA_COMPRESSION =PAGE); GOテーブルが作成されたら、テーブルにデータを入力し、上記で触れたメトリックの多くを測定しました。各テストの合間にSQLServerサービスを再起動して、すべてが同じベースラインから開始されていること、DMVがリセットされることなどを確認しました。
競合のない挿入物
私の最終的な目標は、テーブルを1,000,000行で埋めることでしたが、最初に、競合のない生の挿入に対するデータ型と圧縮の影響を確認したいと思いました。次のクエリを生成し、テーブルに最初の200,000の連絡先、一度に2000行を入力し、各テーブルに対して実行しました。
DECLARE @i INT =1; WHILE @i <=100BEGIN INSERT dbo.Customers_ $ use_case $(FirstName、LastName、Email、Active)SELECT FirstName、LastName、Email、Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 *(@ i-1)ROWS FETCH NEXT2000ROWSのみ。 SET @i + =1; END結果(クリックして拡大):
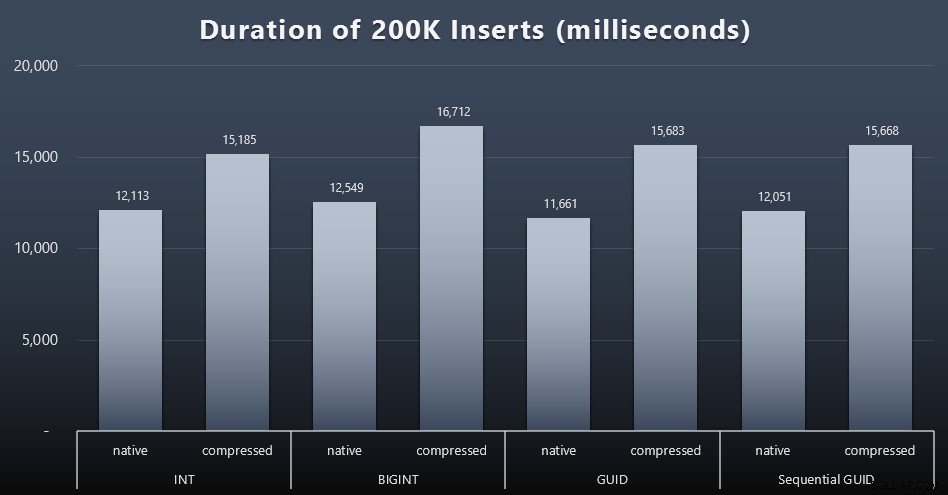
それぞれのケースで約12秒(圧縮なし)と16秒(圧縮あり)かかり、どちらのストレージモードでも明確な勝者はありませんでした。圧縮の効果(主にCPUオーバーヘッド)はかなり一貫していますが、これは高速SSDで実行されているため、さまざまなデータ型のI/Oへの影響はごくわずかです。実際、BIGINTに対する圧縮が最大の影響を及ぼしているように見えました(20億未満のすべての値が圧縮されるため、これは理にかなっています)。
より論争の多いワークロード
次に、混合ワークロードがリソースをめぐって競合し、一般的に各データ型に対してどのように実行されるかを確認したいと思いました。そこで、これらのプロシージャを作成しました(
$use_case$を置き換えます) および$data_type$各テストに適切に):-複数のインデックスのデータに対するランダムなシングルトン更新CREATEPROCEDURE[dbo]。[Customers_$use_case $ _RandomUpdate] @Customers_ $ use_case $ $ data_type $ ASBEGIN SET NOCOUNT ON; UPDATE dbo.Customers_ $ use_case $ SET LastName =COALESCE(STUFF(LastName、4、1、'x')、'x')WHERE CustomerID =@ Customers_ $ use_case $; ENDGO --reads( "pagination")-複数をサポート並べ替え-動的SQLを使用してクエリ統計を個別に追跡しますCREATEPROCEDURE[dbo]。[Customers_$use_case $ _Page] @PageNumber INT =1、@ PageSize INT =100、@ sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX)=N'SELECT CustomerID、FirstName、LastName、Email、Active、Created、Updated FROM dbo.Customers_ $ use_case $ ORDER BY' + @sort + N'OFFSET((@ pn-1)* @ ps)ROWS FETCH NEXT @ps ROWS ONLY;'; EXEC sys.sp_executesql @ sql、N'@ pn INT、@ ps INT'、@ PageNumber、@ PageSize; ENDGO次に、これらのプロシージャを少し遅れて繰り返し呼び出すジョブを作成し、同時に、残りの800,000件の連絡先への入力を完了しました。このスクリプトは、32個のジョブすべてを作成し、後で特定のテストのすべてのジョブを非同期的に呼び出すために使用できる出力を出力します。
USE msdb; GO DECLARE @typ TABLE(use_case VARCHAR(2)、data_type SYSNAME); INSERT @typ(use_case、data_type)VALUES('I'、N'INT')、('Ic'、N'INT ')、(' B'、N'BIGINT')、(' Bc'、N'BIGINT')、(' G'、N'UNIQUEIDENTIFIER')、(' Gc'、N'UNIQUEIDENTIFIER')、(' S '、N' UNIQUEIDENTIFIER')、(' Sc'、N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME、cmd NVARCHAR(MAX)); INSERT @jobs(name、cmd)VALUES(N'ランダム更新ワークロード'、N'DECLARE @CustomerID $ data_type $、@i INT =1; WHILE @i <=500 BEGIN SELECT TOP(1)@CustomerID =CustomerID FROM dbo.Customers_ $ use_case $ ORDER BY NEWID(); EXEC dbo.Customers_ $ use_case $ _RandomUpdate @ Customers_ $ use_case $ =@CustomerID; WAITFOR DELAY'' 00:00 :01''; SET @i + =1; END')、(N' Populate Customers'、N' SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_ $ use_case $ (FirstName、LastName、Email、Active)SELECT FirstName、LastName、Email、Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 *(@ i-1)ROWS FETCH NEXT 2000 ROWS ONLY; WAITFOR DELAY'' 00:00: 01''; SET @i + =1; END')、(N'ページングワークロード1'、N'DECLARE @i INT =1、@sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN --sort by CustomerID SET @sql =N '' EXEC dbo.Customers_ $ use_case $ _Page @PageNumber =@i、@sort =N'''' CustomerID'''';''; EXEC sys.sp_executesql @sql、N'' @ i INT''、@ i; WAITFOR DELAY'' 00:00:01''; SET @i + =2; END')、(N'ページングワークロード2'、N'DECLARE @i INT =1、@sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN-LastName、FirstNameで並べ替えSET @sql =N''EXEC dbo.Customers_ $ use_case $ _Page @PageNumber =@i、@sort =N'''' LastName、FirstName'''';''; EXEC sys.sp_executesql @sql、N'' @ i INT''、@i; WAITFOR DELAY'' 00:00:01''; SET @i + =2; END'); DECLARE @n SYSNAME、@ c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N'' + j.name、cmd =REPLACE(REPLACE(j.cmd、N'$ use_case $'、t.use_case)、N'$ data_type $'、t .data_type)FROM @typ AS t CROSS JOIN @jobs AS j; OPEN c; FETCH c INTO @ n、@ c; WHILE @@ FETCH_STATUS <> -1BEGIN IF EXISTS(SELECT 1 FROM msdb.dbo.sysjobs WHERE name =@n)BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n、@enabled =0、@ notify_level_eventlog =0、@ category_id =0、@ owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@ n、@ step_name =@ n、@ command =@c、@ database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n、@server_name =N'(ローカル)'; PRINT'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n +''';'; FETCH c INTO @ n、@ c; ENDいずれの場合もジョブのタイミングを測定するのは簡単でした。
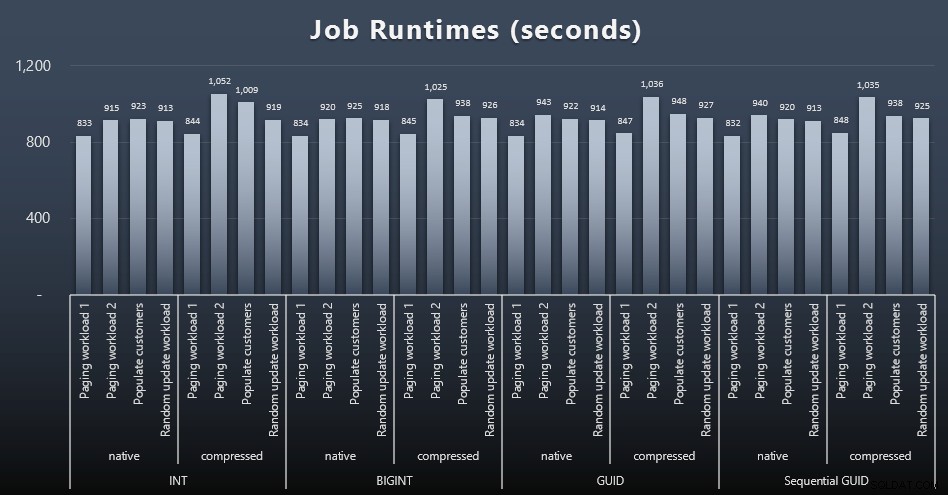
msdb.dbo.sysjobhistoryで開始日と終了日を確認できました。 または、SQL SentryEventManagerからそれらをプルします。結果は次のとおりです(クリックして拡大):
また、ダイジェストを少し減らしたい場合は、4つのジョブの平均実行時間と最大実行時間を確認してください(クリックして拡大):
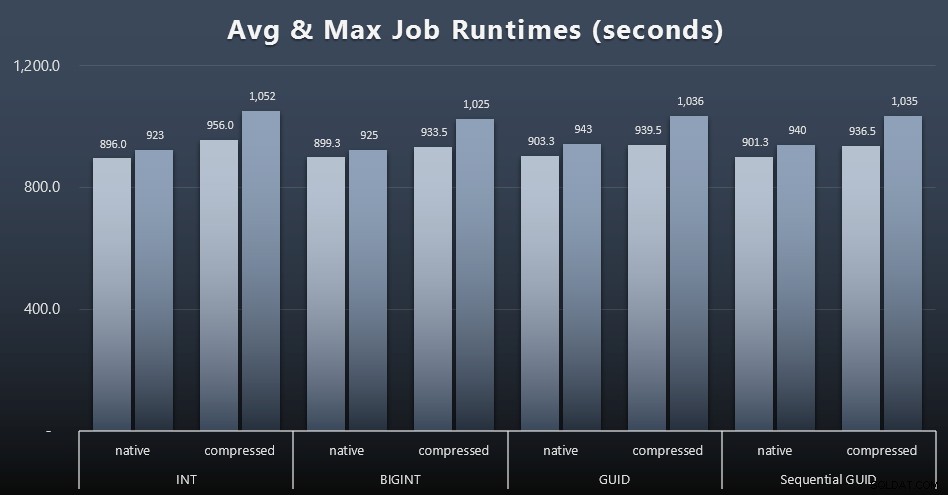
しかし、この2番目のグラフでも、いずれのアプローチにも賛成または反対の説得力のある主張をするのに十分な差異はありません。
クエリランタイム
sys.dm_exec_query_statsからいくつかの指標を取得しました およびsys.dm_exec_trigger_stats個々のクエリに平均してかかった時間を判断します。
人口
最初の200,000の顧客は、競合するワークロードがないため、非常に迅速に(20秒未満で)ロードされました。ただし、4つのジョブが同時に実行されると、同時実行性のために書き込み期間に大きな影響がありました。残りの800,000行は、平均して完了するのに少なくとも1桁長い時間が必要でした。 2,000件の顧客挿入を平均した結果は次のとおりです(クリックして拡大):
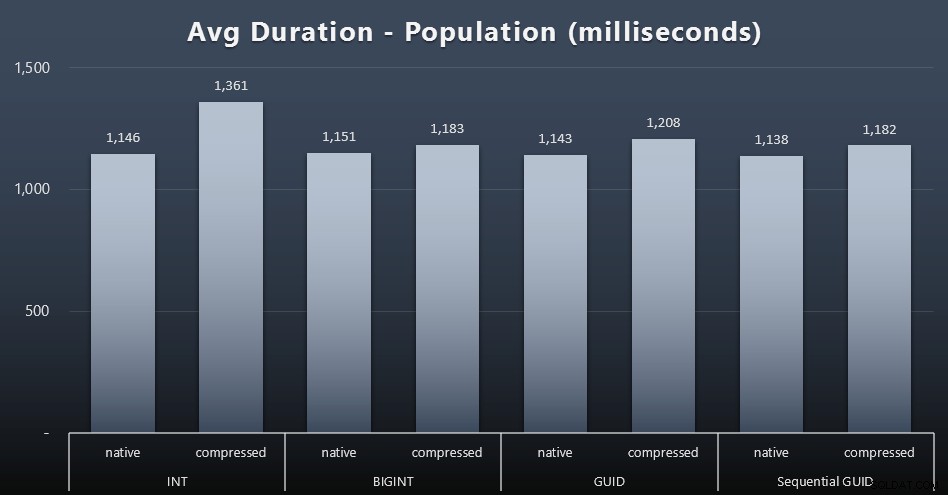
ここで、INTの圧縮が唯一の実際の外れ値であることがわかります。これについてはいくつかの理論がありますが、決定的なものはまだありません。
ページングワークロード
ページングクエリの平均実行時間も、単独でのテスト実行と比較して、同時実行性の影響を大きく受けているようです。結果は次のとおりです(クリックして拡大):
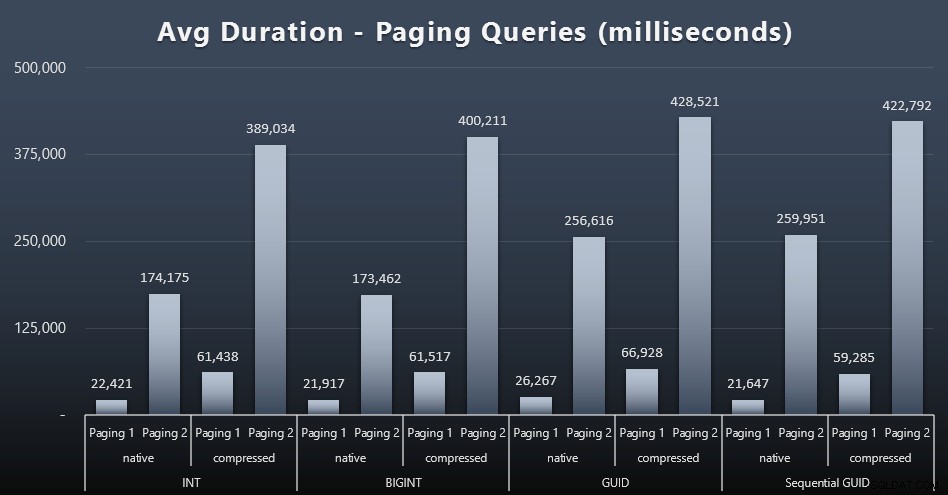
(ページング1 =CustomerIDによる順序、ページング2 =LastName、FirstNameによる順序)
ページング1(CustomerIDによる順序)とページング2(名前による順序)の両方で、圧縮により実行時間に大きな影響があることがわかります(最大700%)。どちらのGUIDもこのレースで最も遅い馬のようで、NEWID()のパフォーマンスが最も低くなっています。
ワークロードの更新
シングルトンの更新は、同時実行性が高い場合でも非常に高速でしたが、圧縮による顕著な違いがあり、データ型間で驚くべき違いがありました(クリックして拡大):
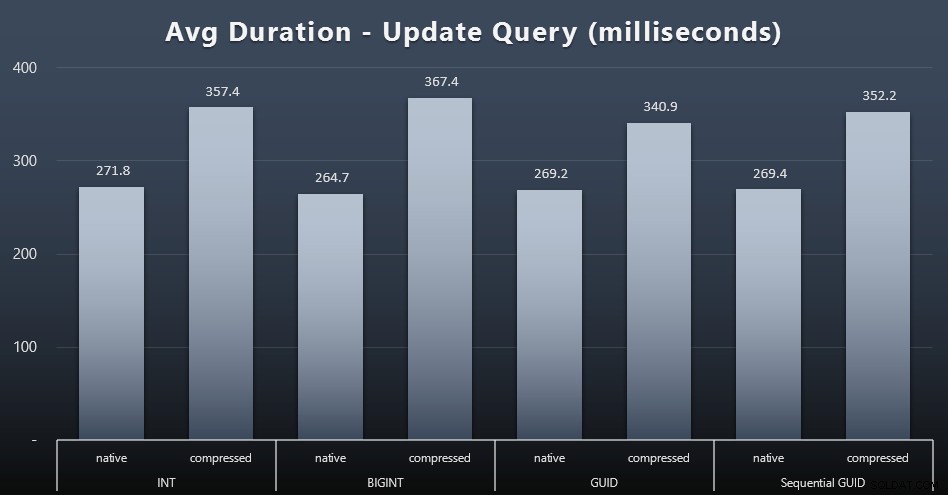
最も注目すべきは、GUID値を含む行の更新が実際には高速であったことです。 圧縮が使用されていた場合、INT/BIGINTを含む更新よりも。ネイティブストレージでは、違いはそれほど顕著ではありませんでした(ただし、INTは依然として敗者でした)。
トリガー統計
それぞれの場合の単純なトリガーの平均および最大実行時間は次のとおりです(クリックして拡大):
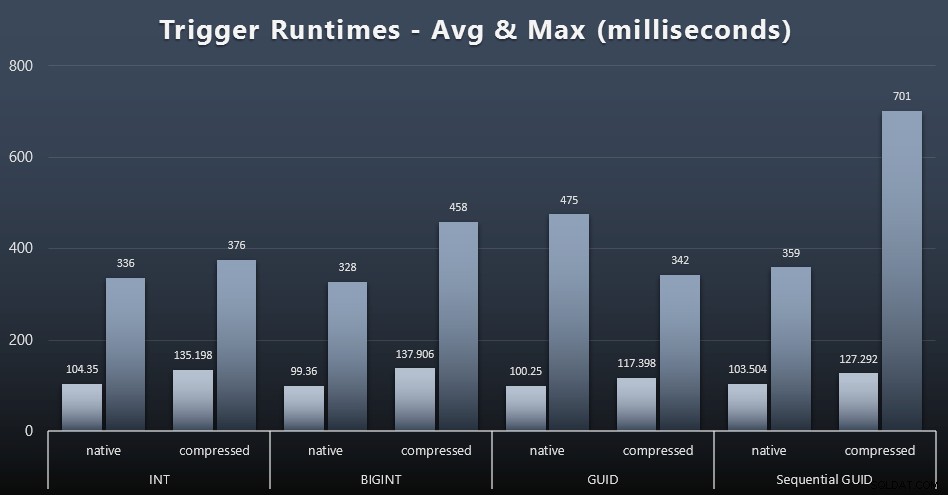
ここでは、圧縮はデータ型の選択よりもはるかに大きな影響を与えるようです(ただし、更新ワークロードの一部が単一行のシークだけで構成されるのではなく、多くの行を更新した場合、これはより顕著になる可能性があります)。シーケンシャルGUIDの最大値は、明らかに私が調査しなかったある種の外れ値です(平均がまだ全面的に並んでいることに基づいて、それは重要ではないと言えます)。
これらのクエリは何を待っていましたか?
各ワークロードの後で、システムでの上位の待機、明らかなキュー/タイマーの待機(Paul Randalによる説明)、および監視ソフトウェア(TRACEWRITEなど)からの無関係なアクティビティも確認しました。 )。それぞれの場合の上位3つの待機は次のとおりです(クリックして拡大):
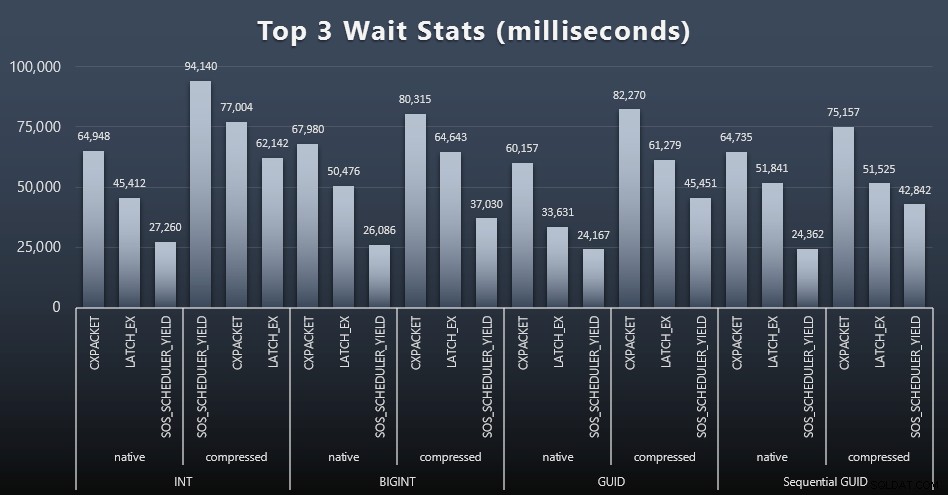
ほとんどの場合、待機はCXPACKET、LATCH_EX、SOS_SCHEDULER_YIELDの順になりました。ただし、整数と圧縮を含むユースケースでは、SOS_SCHEDULER_YIELDが引き継ぎました。これは、整数を圧縮するアルゴリズムの非効率性を意味します(これは、BIGINTをINTに圧縮するために使用されるアルゴリズムとは完全に無関係である可能性があります)。これについてはこれ以上調査しませんでした。また、個々のクエリごとに待機を追跡する理由も見つかりませんでした。
ディスクスペース/フラグメンテーション
私はそれがディスクスペースに関するものではないことに同意する傾向がありますが、それでも提示する価値のあるメトリックです。テーブルが1つだけで、キーが他のすべての関連テーブル(実際のアプリケーションに確実に存在する)に存在しないというこの非常に単純なケースでも、違いは重要です。まず、reservedを見てみましょう。 sp_spaceusedの列 (クリックして拡大):
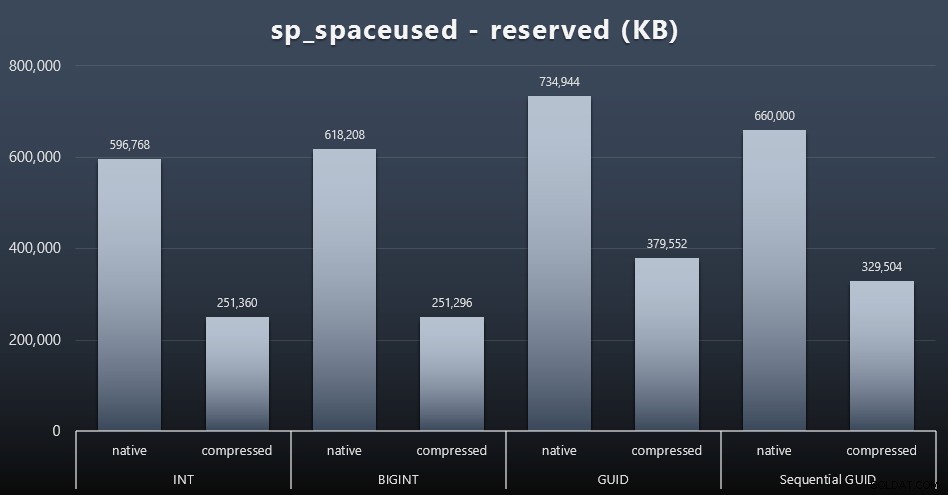
ここで、BIGINTはINTよりも少しだけ多くのスペースを取り、GUID(予想どおり)はより大きなジャンプをしました。シーケンシャルGUIDでは、使用されるスペースの増加がそれほど大きくなく、従来のGUIDよりもはるかに圧縮率が高くなっています。繰り返しになりますが、ここで驚くことはありません。GUIDは数値よりも大きく、終止符です。さて、GUIDの支持者は、ディスク容量に関して支払う価格はそれほど高くないと主張するかもしれません(圧縮なしのBIGINTより18%、圧縮ありの場合は約50%)。ただし、これは100万行の単一のテーブルであることを忘れないでください。 1,000万人の顧客がいて、その多くが10、30、または500の注文がある場合に、それがどのように推定されるか想像してみてください。これらのキーは、他の12のテーブルで繰り返され、各行で同じ余分なスペースを占める可能性があります。
このクエリを使用して、各ワークロード(インデックスのメンテナンスは実行されていないことを思い出してください)の後に断片化を調べたところ、次のようになりました。
SELECT index_id、FROM sys.dm_db_index_physical_stats(DB_ID()、OBJECT_ID('dbo.Customers_ $ use_case $')、-1、0、'DETAILED');
結果は、はるかに面白くないビジュアルになりました。 すべて 非クラスター化インデックスは99%以上断片化されていました。ただし、クラスター化インデックスは非常に断片化されているか、まったく断片化されていません(クリックして拡大):
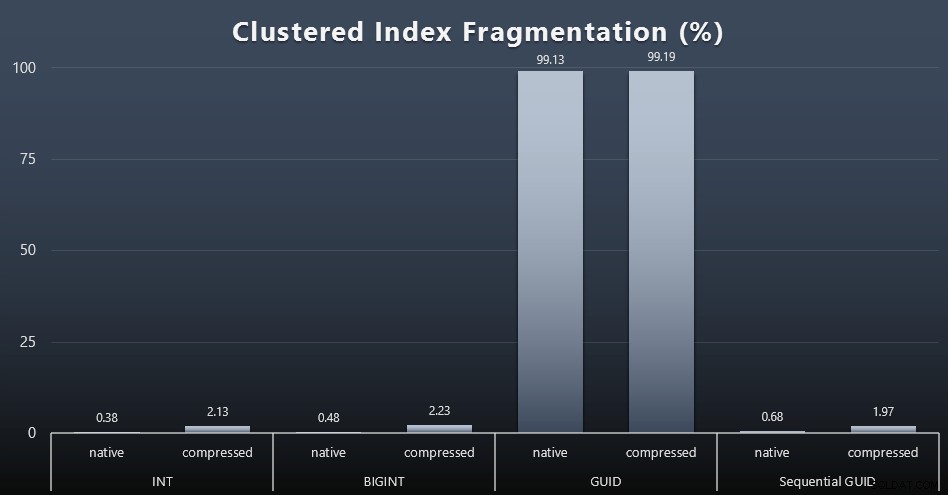
断片化は、SSDについて話しているときに意味がはるかに少ない別の指標ですが、すべてのシステムが断片化がI / Oパターンに与える影響を幸福に認識できるわけではないため、すべて同じことに注意することが重要です。非シーケンシャルGUIDを使用すると、よりI / Oバウンドのシステムで、この断片化の影響だけで、このテストの他のほとんどのメトリックで大幅に増幅されると思います。
バッファプールの使用
これは、テーブルで使用されるディスクスペースの量を慎重に検討することで実際に効果があります。テーブルが大きいほど、バッファープールで占めるスペースが多くなります。バッファプールにデータを出し入れするのはコストがかかります。これも非常に単純なケースであり、テストは個別に実行され、インスタンス上に貴重なメモリを奪い合う他のアプリケーションやデータベースはありませんでした。
これは、各ワークロードの最後にある次のクエリの簡単な尺度です。
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'バッファプール';
結果(クリックして拡大):
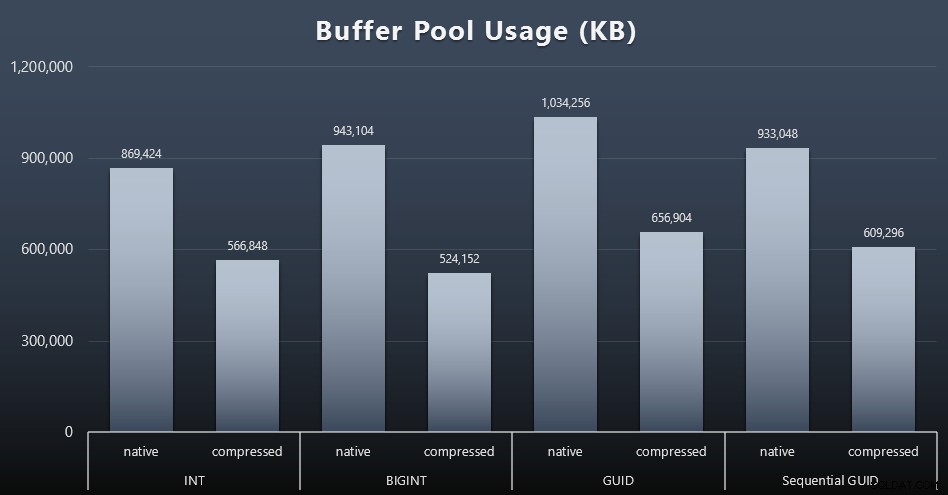
このグラフのほとんどはまったく驚くべきことではありませんが、GUIDはBIGINTよりも多くのスペースを取り、BIGINTはINTよりも多くのスペースを取ります。圧縮しなくても、シーケンシャルGUIDがBIGINTよりも少ないスペースを占めることは興味深いことです。ここでは、ページレベルのフォレンジックを実行して、ここでどのような効率が行われているのかを判断するようにメモしました。
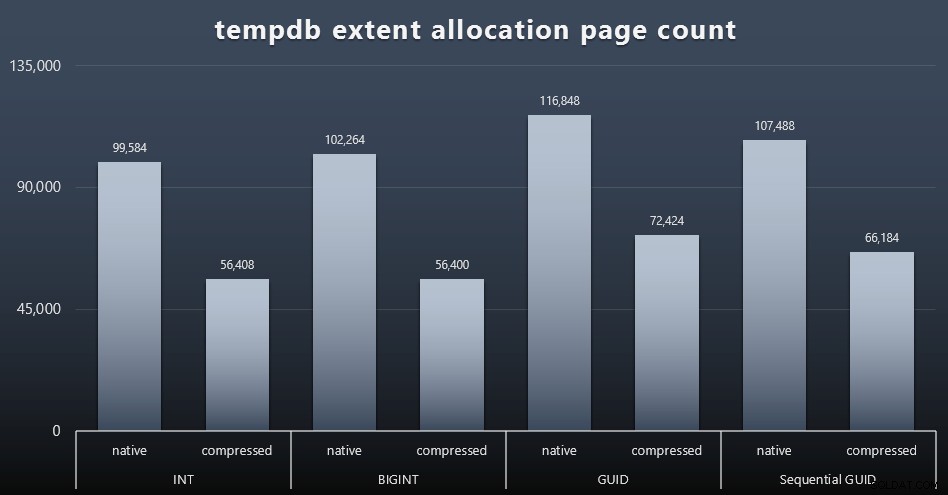
tempdbの使用法
ここで何を期待していたかはわかりませんが、各ワークロードの後に、3つのtempdb関連のスペース使用量DMV、sys.dm_db_file|session|task_space_usageのコンテンツを収集しました。 。データ型に基づいて変動性を示していると思われるのは、sys.dm_db_file_space_usageだけでした。 のextent_allocation_page_count 。これは、少なくとも私の構成とこの特定のワークロードでは、GUIDがtempdbをもう少し徹底的なワークアウトにかけることを示しています(クリックして拡大):
「悪い」ページ分割
私が測定したかったことの1つは、ページ分割への影響でした。通常のページ分割(新しいページを追加するとき)ではなく、実際にページ間でデータを移動して行を増やす必要がある場合です。 Jonathan Kehayiasは、ブログ投稿「SQL Server 2012拡張イベントで問題のあるページ分割を追跡する–今回は実際にはありません!」でこれについて詳しく説明しています。これは、データのキャプチャに使用した拡張イベントセッションの基礎にもなります。
CREATE EVENT SESSION [BadPageSplits] ON SERVER ADD EVENT sqlserver.transaction_log(WHERE operation =11 AND database_id =10)ADD TARGET package0.histogram(SET filtering_event_name ='sqlserver.transaction_log'、source_type =0、source ='alloc_unit_id' ); GOALTER EVENT SESSION [BadPageSplits] ON SERVER STATE =START; GO
そして、私がそれをプロットするために使用したクエリ:
SELECT t.name、SUM(tab.split_count)FROM(SELECT n.value('(value)[1]'、'bigint')AS alloc_unit_id、n.value('(@ count)[1]' 、'bigint')AS split_count FROM(SELECT CAST(target_data as XML)target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histogram')AS x CROSS APPLY target_data.nodes('HistogramTarget / Slot')as q(n))AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS pONau。 container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id=t。[object_id]GROUPBY t.name;
結果は次のとおりです(クリックして拡大):
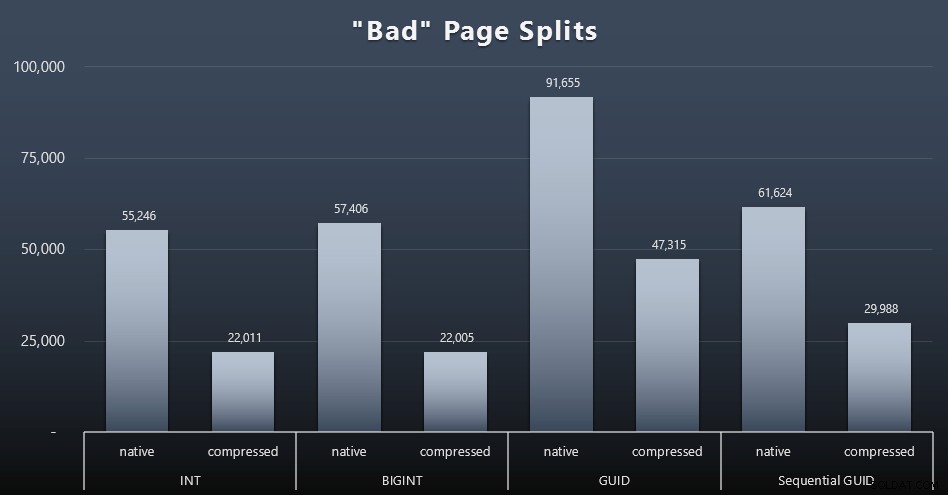
私のシナリオ(高速SSDで実行している場合)では、I / Oアクティビティの明白な違いが全体の実行時間に直接影響しないことはすでに述べましたが、これは、特に次の場合に考慮したいメトリックです。 SSDがない場合、またはワークロードがすでにI/Oバウンドになっている場合。
結論
これらのテストにより、最近のハードウェアによって長期にわたる認識がどのように変化したかについて少し目を向けることができましたが、ディスクやメモリのスペースを無駄にすることにはまだかなり固執しています。バランスを示してGUIDを輝かせようとしましたが、パフォーマンスの観点から、INT/BIGINTからいずれかの形式のUNIQUEIDENTIFIERへの切り替えをサポートするものはほとんどありません。アプリケーションまたは異種システム間で一意のキー値を維持する)。簡単な要約。NEWID()は、実質的な違いがあった多くのメトリックの中で最悪の選択であることが示されています(ほとんどの場合、NEWSEQUENTIALID()は2番目に近い値でした)):
| メトリック | 敗者をクリアしますか? |
|---|---|
| 競合のない挿入物 | –描画– |
| 同時ワークロード | –描画– |
| 個別のクエリ–人口 | INT(圧縮) |
| 個別のクエリ–ページング | NEWID()/ NEWSEQUENTIALID() |
| 個別のクエリ–更新 | INT(ネイティブ)/ BIGINT(圧縮) |
| 個別のクエリ–トリガー後 | –描画– |
| ディスク容量 | NEWID() |
| クラスター化されたインデックスの断片化 | NEWID() |
| バッファプールの使用量 | NEWID() |
| tempdbの使用法 | NEWID() |
| 「不正な」ページ分割 | NEWID() |
表2:最大の敗者
これらのことを自分で自由にテストしてください。自分の環境でスクリプトを実行したい場合は、スクリプトのフルセットを組み立てることができます。この投稿全体の短期間での目的は非常に単純です。ディスクスペースへの予測可能な影響以外に考慮すべき重要な指標が多数あるため、どちらの方向の議論としても単独で使用しないでください。
さて、私はこの考え方をキー自体に限定したくありません。データ型の選択が行われるときはいつでも、それは本当に考えられるべきです。 datetimeが表示されます たとえば、dateのみの場合など、頻繁に選択されます またはsmalldatetime が必要です。トランザクションテーブルでは、これも多くの無駄なディスクスペースを生み出す可能性があり、これはこれらの他のリソースの一部にも影響を及ぼします。
将来のテストでは、はるかに大きなテーブル(> 20億行)の結果を比較したいと思います。 IDシードを-20億に設定し、最大40億行を許可することで、INTを使用してこれをシミュレートできます。また、ワークロードとディスクスペース/メモリフットプリントの比較には、複数のテーブルを含める必要があります。スキニーキーの利点の1つは、そのキーが数十の関連テーブルで表される場合です。自動拡張イベントを監視していましたが、データベースが拡張に対応できる大きさで事前にサイズ設定されていて、既存のログファイル内の実際のログ使用量を測定することを考えていなかったため、何もありませんでした。テストしたいと思います。ここでも、ログサイズと自動拡張のデフォルトを使用し、今回はDBCC SQLPERF(LOGSPACE);を測定します。 。また、これらの操作の結果として、時間の再構築とログ使用量の測定も興味深いでしょう。最後に、メカニカルハードディスクを搭載したサーバーを見つけることで、I / Oをより適切な要素にしたいと思います。そこにはたくさんあることはわかっていますが、一部のショップではかなり不足しています。