世論データはどのように保存されますか?世論調査のデータモデルを確認します。
政治家や企業から、特定のトピックについて他の人がどう思うかを知りたい個人まで、誰もが一般の人々の考えを知りたがっています。この種の仕事は通常、そのタイプの研究を専門とする機関によって実行されます。
今日は、そのような機関が質問や事前定義された回答から実際のフィードバックまで、関連するすべての投票データを保存するために使用できるデータモデルを見ていきます。このデータは、後でさまざまなレポートを作成するために使用されます。それでは、始めましょう。
アイデア
投票はどこでも作成できます。それらはよく計画されていて、(人口統計に基づいて)一般の代表的なサンプルを含めることができます。または、その場で行うこともできます。サンプル(出口調査など)に基づいて選挙結果を予測したい場合は、投票所の人々にどのように投票したかを尋ねるでしょう。
一方、選挙前に同じ投票を作成したい場合は、サンプルを選択して、電話または直接個人に連絡することをお勧めします。通常、このタイプの世論調査には、人口統計をカバーする質問と、私たちが本当に興味を持っていることをカバーする質問があります。
ポーリングは、はるかに複雑になることもあります。特定の製品に関する世論を知りたい場合は、そのパフォーマンスからパッケージングまですべてをカバーします。
この記事では、サンプルセットを選択する方法については説明しません。むしろ、投票自体、その質問、および回答に焦点を当てます。
データモデル
世論機関のデータモデル
モデルは3つのサブジェクトエリアで構成されています:
PollsQuestions & AnswersResult
各サブジェクトエリアについて、記載されている順序で説明します。
ポール
質問を始める前に、興味のあることを定義する必要があります。このセクションでアンケートとアンケートを定義し、次のセクションで質問と回答を追加します。
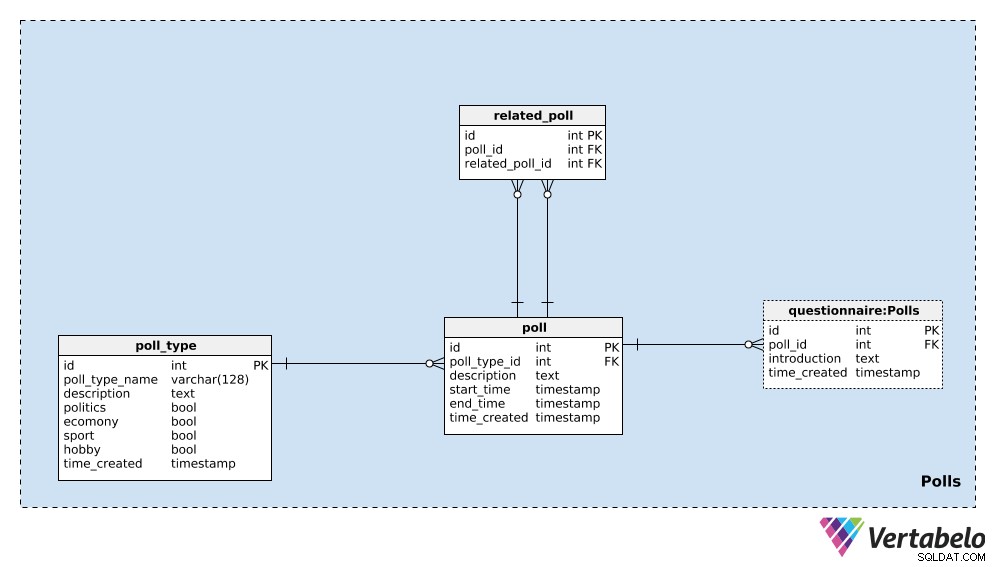
poll_type 辞書。ほとんど同じタイプのポーリングを繰り返すことが期待できます。最も一般的なタイプはおそらく選挙投票ですが、途中で新しい投票タイプを追加できるようにしたいと考えています。ポーリングタイプごとに、一意のpoll_type_nameを保存します descriptionを使用します 追加の詳細を提供する属性。
4つのフラグ–politics 、economy 、sport 、およびhobby –は、ポーリングのタイプを示すために使用されます。世論調査は、これらのトピックの1つ以上をカバーする可能性があります。必要に応じて、これらのカテゴリを別の辞書に分割し、その辞書とpoll_type テーブル。
このテーブルの最後の属性はtime_createdです。 。このテーブルに行が挿入された瞬間を示します。
次に行う必要があるのは、単一のpoll 。これは単一のインスタンスです。例: 「2020年米国大統領選挙–2020年4月の世論調査」 。投票ごとに、次の詳細を保存します:
-
poll_type_id–poll_type。 description–この投票に関連するすべての詳細(テキスト形式)。-
start_timeおよびend_time–このポーリングが行われる定義済みの開始時間と終了時間。 -
time_created–この投票が作成された実際の瞬間。
ポーリングは相互に関連付けることができます。 「2020年米国大統領選挙–2020年4月の世論調査」の例では 、次の月に同じ世論調査を行って、最新の意見を見ることができます。これを「2020年米国大統領選挙–2020年5月の世論調査」と呼びます 。これらの2つのポーリングは、結果が傾向を示しているため、関連しています。その関係を確立するために、related_poll モデルのテーブル。 poll_idのUNIQUEペアのみが含まれています – related_poll_id 、投票とその前身を示します。
このテーブルを使用して、先行/後続だけでなく、任意の方法で関連するすべてのポーリングを格納できることに注意してください。さまざまな関係を定義したい場合は、別の辞書を追加する必要がありますが、この記事ではそのようにはしません。
この主題分野の最後の表は、questionnaire テーブル。ほとんどの場合、各投票には1つの質問票がありますが、必要に応じて複数の質問票を用意できるという選択肢を残したいと思います。したがって、別のテーブルを使用しました。このテーブルには、関連する投票のID(poll_id)のみが格納されます。 )、introduction そのアンケートと、レコードが挿入されたときのタイムスタンプ(time_created 。
質問と回答
これで、すべてのアンケートの詳細を作成する準備が整いました。また、質問したいすべての質問と、事前に定義されたすべての回答を一覧表示することもできます。
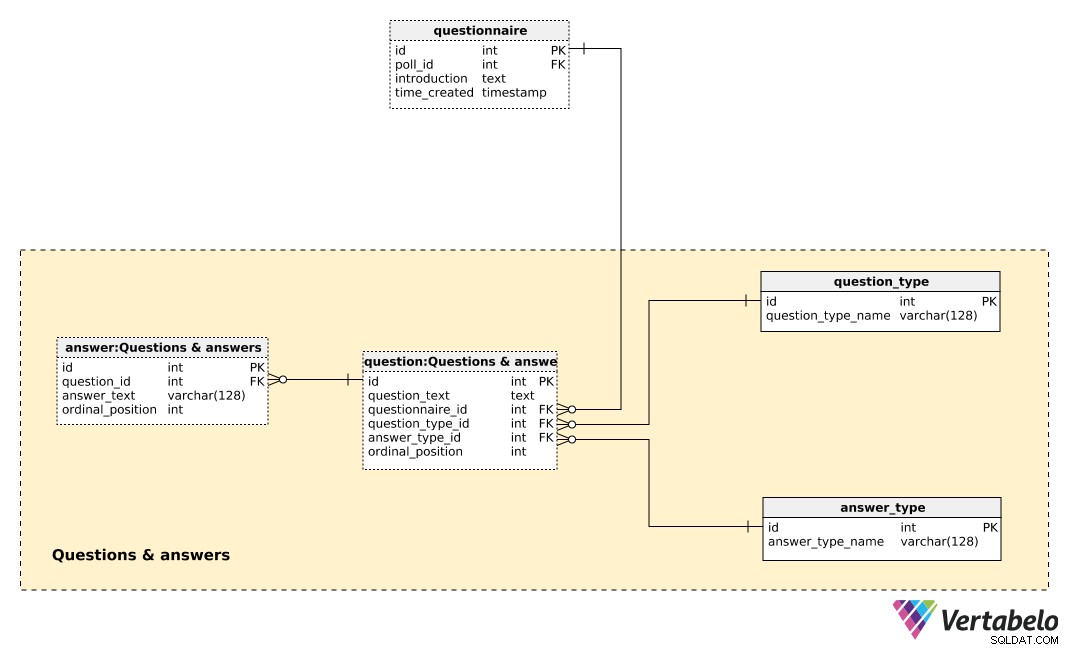
このサブジェクトエリアの中心的なテーブルは、question テーブル。各質問は、次の詳細によって定義されます。
-
question_text–ポーリングされる各個人に表示されるテキスト。 -
questionnaire_id–この質問の質問票を示す参照。 -
question_type_id–question_type、これはquestion_type_nameで一意に示されます 。これらは基本的にカテゴリです。 「人口統計」、「意見」、「管理」など。これらにより、人口統計と意見の質問を分離し、それらの間の相関関係を見つけることができます。 -
answer_type_id–この質問に使用される回答のタイプへの参照。各answer_typeanswer_type_nameによって一意に定義されます 答えがどのように表示されるかを示します。予想されるタイプには、「オープン」、「リスト」、「チェックボックス」、「複数」があります。 -
ordinal_position–この値は、質問表におけるこの質問の位置を示します。questionnaire_idと一緒に 、このテーブルの代替キーを形成します。
事前定義されたすべての回答のリストがanswer テーブル。質問の種類が開いていない場合(つまり、テキストが個人によって入力されない場合)、事前定義された回答のセットがあります。回答ごとに、それが属する質問を定義します(question_id )、answer_text 、およびordinal_position その質問の中のその答えの。もう一度、UNIQUEペア–今回はquestion_id – ordinal_position –このテーブルの代替キーを形成します。
結果
前の2つの主題分野では、投票を作成して質問を開始するために必要なすべてを定義しました。次に、実際の回答を格納するためのデータ構造を定義する必要があります。
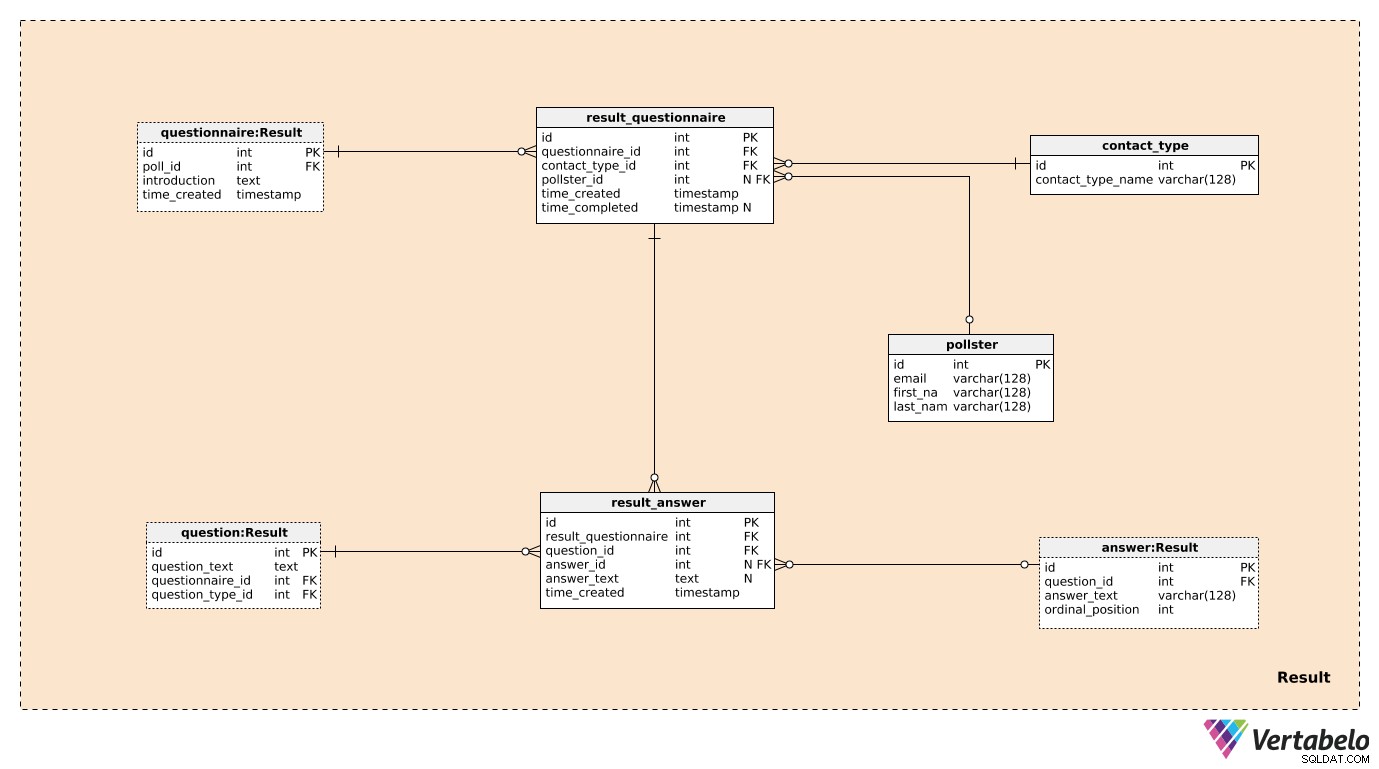
Result 主題分野は以前に言及され、説明された。これらはquestionnaire 、question 、およびanswer 。残りの4つのテーブルは、私たちが本当に興味を持っているものを保存するために使用されます。
result_questionnaire 投票に参加する各個人の表。 questionnaire_id 関連する投票に関するすべての情報をesusに提供します。 contact_type_id contact_type 辞書。この表の値は、私たちがこの人とやり取りした方法を表しています。これらの値は、contact_type_nameによって一意に定義されます 価値があり、「電話」、「対面」、「メール」、「ウェブフォーム」などのようなものである可能性があります。
pollster_id 属性はpollster 表には、実際の投票を行った人の情報が記載されています。 pollster 、一意のメールとfirst_nameのみを保存します およびlast_name 。 time_created 属性は、このレコードが作成された実際の時刻を示し、time_completed この調査が完了した時点で設定されます。 (それまではNULLになります。)
モデルの最後のテーブルはresult_answer テーブル。その名前が示すように、ここに調査対象者から得た実際の回答を保存します。この表のレコードごとに、次のものがあります。
-
result_questionnaire_id–関連するアンケートへの参照。 -
question_id–この回答によって回答された質問を示す参照。 -
answer_id–この質問への回答に使用された回答への参照。質問が「オープン」タイプの場合、この属性にはNULL値が含まれます(選択できる事前定義された回答がなかったため)。 -
answer_text–この質問に答えるために挿入されたテキスト。この属性には、質問が「オープン」だったときの値が含まれます。それ以外の場合はすべてNULLになります。 -
time_created–この回答がシステムに挿入された実際の時間。
可能な改善
これまで、投票データを保存する方法について説明してきました。投票が終了した後、データをどのように処理するかについては説明していません。少なくとも運用データベースでは、将来的に古いデータは必要なくなると予想できます。したがって、次の2つのことができます。
- ポーリングの要約を運用データベースの別のテーブルに保存します。同様の投票で何が起こったのかを知りたい場合は、このような情報を自由に利用できます。
- すべてのポーリングデータを、運用データベースと同じ構造のバックアップデータベースに保存します。これにより、必要なときに詳細にアクセスできるようになります。
ポーリング結果を保存するデータウェアハウスを作成することもできますが、2つの箇条書きで説明されているタスクをすでに実行している場合は必要ありません。
私たちの世論調査データモデルについてどう思いますか?
世論調査データモデルを改善するために何を変更できるかについて、ご意見をお聞かせください。業界での経験はありますか?私たちは何かを逃したと思いますか?何かを追加または削除しますか?ご意見をお待ちしております。