一般的な企業のデータ量が飛躍的に増加するにつれて、データストレージを最適化することがさらに重要になります。データのサイズは、ストレージのサイズとコストだけでなく、クエリのパフォーマンスにも影響します。データのサイズを決定する際の重要な要素は、選択するデータ型です。このチュートリアルでは、適切なデータ型を選択する方法について説明します。
データ型 特定のフィールド(または列)に格納できるデータの種類と範囲を定義します。
次のサンプルレコードを含む販売テーブルについて考えてみます。
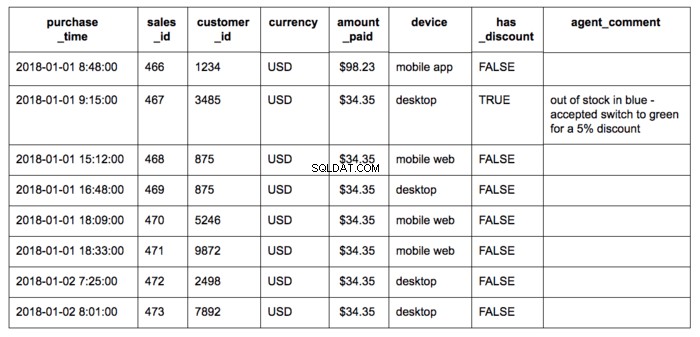
各フィールドには、独自のタイプと値の範囲があります:
Purchase_time :販売の日時 sale_id :新しい販売ごとに1ずつ増加する整数値 customer_id :新規顧客ごとに1ずつ増加する整数値通貨 :テキストは常に3文字の通貨コード amount_paid :0.00ドルから1,000.00ドルの間の実際の金額デバイス :テキスト。値は次のようになります:「desktop」、「mobile app」、「mobileweb」 has_discount :エントリをTRUEにできるブール値 またはFALSE メモ :テキスト。ここで、エントリはエージェント入力ツールで許可されている長さ(250文字)である可能性があります
データの種類(整数、テキスト、実数など)と可能な値の範囲(0〜1,000、任意の3文字など)は、特定のデータベースのデータ型に対応します。 。
データベースが異なれば、使用できるデータ型も異なりますが、ほとんどが次のカテゴリに当てはまります。
数値:
- 整数 :分数のない数値の場合。符号付き(正と負の値を許可)または符号なし(正の数のみを許可)にすることができます。 IDフィールドと何かのカウントに一般的に使用されます
- 10進数(x、y) :正確な精度を必要とする分数のある数値の場合。符号付き(正と負の値を許可)または符号なし(正の数のみを許可)にすることができます。一般的に金銭分野に使用されます。ユーザーは、括弧内に全体的に許可される有効桁数(x)と小数点以下(y)を指定します。
- フロート/ダブル :正確な精度を必要としない分数の数値の場合。符号付き(正と負の値を許可)または符号なし(正の数のみを許可)にすることができます。通貨フィールドを除くすべての実数に一般的に使用されます
日付/時刻:
日付 :日付値の場合
- 時間 :時間値の場合
- タイムスタンプ/日時 :日付と時刻の値
テキスト:
- 文字(n) :固定長文字列の場合、括弧内の値が各エントリの固定サイズを示します
- varchar(n) :可変長文字列の場合、括弧内の値が各エントリの最大許容サイズを示します
ブール値:
- ブール値 :ブール(true / false)値の場合。一部のデータベース(MySQLなど)にはブールデータ型がなく、代わりにブール値を整数に変換します(1 =TRUE、0 =FALSE)
ほとんどのデータベースは、タイプごとにサイズのバリエーションを提供します。たとえば、MySQLは次の可能な整数データ型を提供します:
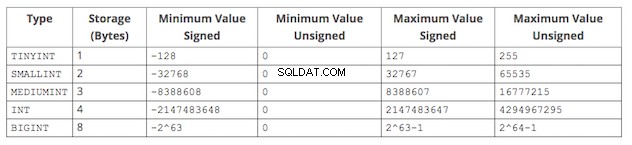
最適なデータ型を選択するための基本的な戦略は、データの種類に一致し、データの実行可能なすべての値を考慮した最小のデータ型を選択することです。
たとえば、customer_id サンプルの販売テーブルには、0から始まる整数が含まれています。現在、架空の会社には15,000人の顧客しかいません。前のセクションのMySQL整数データ型テーブルを使用すると、SMALLINTを選択したくなるかもしれません。 データ型としてunsigned。これは、0〜15,000の現在の整数値を受け入れる最小のデータ型であるためです。ただし、今後6〜12か月で10万人の顧客を獲得できると見込んでいます。 65,535を超えると、SMALLINT もはや十分ではありません。したがって、より適切な選択はMEDIUMINTです。 署名されていない、これは今後数年間私たちをカバーするはずです。
サンプルレコードを使用してテーブルを作成するときに、データベースにデータ型を選択させることができます。ただし、これによって最適なデータ型を選択できることはめったにありません。たとえば、MySQLに前に示したサンプル値を使用して販売テーブルのデータ型を選択させると、いくつかの問題が発生します。
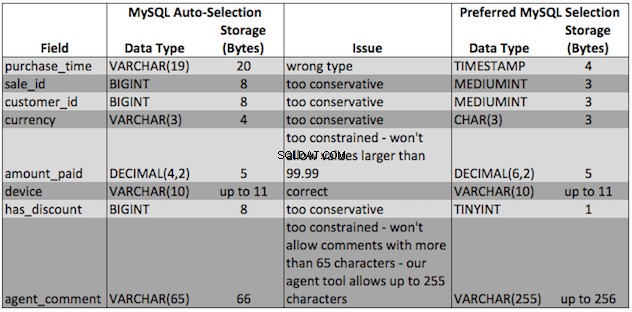
MySQLが自動的に選択したデータ型で発生する問題は次のとおりです。
- 間違ったデータ型 :フィールドを期待どおりに使用することはできません。たとえば、
purchase_time時間データ型ではなく文字列として、フィールドで時間操作(購入からの経過時間の計算など)を実行できないことを意味します - 制約が強すぎる :データ型で許可されている値よりも大きい値を入力しようとすると、MySQLでエラーが発生します。たとえば、amount_paidが$ 100.00以上のセールや、65文字を超えるagent_commentがある場合、エラーが発生します
- 保守的すぎる :データ型が保守的すぎることから何も壊れることはありませんが、ストレージスペースを浪費することになります。サンプルデータでは、あまり保守的でない優先オプションを使用することで、ストレージを15%節約できます
最新のデータベースと同じように、データの所有者は、保存されているデータの種類と、データが近い将来に取ることができる可能性のある値について、最もよく知っています。したがって、各フィールドのデータ型を慎重に指定する必要があります。
さまざまな一般的なデータベースのデータ型に関するドキュメントは、次の場所にあります:
- MySQL
- Amazon Redshift
- Apache Hive
- Terradata
データベースが正しく機能し、可能な限り最適化されるためには、テーブルの各フィールドのデータ型を慎重に選択することが重要です。