昨年、Enterprise Editionに投資せずに、AvailabilityGroupで読み取り可能なセカンダリをシミュレートするソリューションを紹介しました。 AG以外にも多くのメリットがあるため、人々がEnterprise Editionを購入するのを止めないでください。しかし、そもそもEnterprise Editionを使用する可能性がない人にとってはなおさらです:
- 予算内で読み取り可能なセカンダリ
私はStandardEditionのお客様の執拗な支持者になろうとしています。新しいリリースごとに取得する機能の数を考えると、そのエディションは全体として非推奨の道を進んでいることは間違いありません。 Microsoftとのプライベートミーティングで、私はStandard Editionにも含まれる機能、特に無制限のハードウェア予算を持つものよりも中小企業にとってはるかに有益な機能を要求しました。
Enterprise Editionのお客様は、テーブルのパーティション分割によって提供される管理性とパフォーマンスの利点を享受できますが、この機能はStandardEditionでは使用できません。最近、どのエディションでもパーティション化の利点の少なくとも一部を実現する方法があり、パーティション化されたビューを含まないというアイデアが浮かびました。これは、パーティション化されたビューが検討する価値のある実行可能なオプションではないということではありません。これらは、Daniel Hutmacher(テーブルのパーティション化に関するパーティション化されたビュー)やKimberly Tripp(パーティション化されたテーブルv。パーティション化されたビュー-なぜまだ存在しているのか)など、他の人によってよく説明されています。私のアイデアは、実装が少し簡単です。
あなたの新しいヒーロー:フィルターされたインデックス
さて、私は知っています、この機能は一部の人にとっては4文字の言葉です。先に進む前に、フィルター処理されたインデックスに満足しているか、少なくともそれらの制限を認識している必要があります。私があなたを売り込もうとする前に、あなたに公平なバランスを与えるためのいくつかの読書:
- フィルター処理されたインデックスがより強力な機能になる方法のいくつかの欠点について説明し、投票するためのConnectアイテムがたくさんあることを指摘します。
- Paul White(@SQL_Kiwi)は、フィルター処理されたインデックスを使用したオプティマイザーの制限と、フィルター処理されたインデックスを追加した場合の予期しない副作用のチューニングの問題について説明しています。と、
- Jes Borland(@grrl_geek)は、フィルター処理されたインデックスでできること(およびできないこと)を教えてくれます。
それらすべてを読みますか?そして、あなたはまだここにいますか?すばらしい。
このTL;DRは、フィルター処理されたインデックスを使用して、すべての「ホットデータ」を個別の物理構造に保持し、さらには基盤となる個別のハードウェアに保持できることです(高速のSSDまたはPCIeドライブを使用できる場合もありますが、それは可能です。テーブル全体を保持します。
簡単な例
データの一部が他のデータよりもはるかに頻繁に照会される多くのユースケースがあります。注文を管理する小売店、ウエディングケーキの配達をスケジュールするパン屋、または出席と譲歩のデータを測定するフットボールスタジアムを考えてみてください。このような場合、日常のクエリアクティビティのほとんどまたはすべてが、「現在の」データに関係しています。
シンプルにしましょう。非常に狭いOrdersテーブルを使用してデータベースを作成します:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
ここで、1か月のデータを保持するのに十分なスペースが高速ストレージにあるとしましょう(季節性と将来の成長を考慮した十分な余裕があります)。新しいファイルグループを追加して、データファイルを高速ドライブに配置できます。
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
次に、HotDataファイルグループにフィルター処理されたインデックスを作成しましょう。フィルターには2015年11月の初めからのすべてが含まれ、時間ベースのクエリに関連する一般的な列はキーまたはインクルードリストに含まれます。
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData; いくつかの行を挿入し、実行プランをチェックして、対象のクエリが実際にインデックスを使用できることを確認できます。
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106'; 結果の実行プランは、確かに、フィルター処理されたインデックスを使用します(クエリのフィルター述語がインデックス定義と正確に一致しない場合でも):
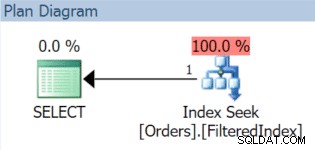
さて、12月1日がロールバックし、11月のデータを交換して12月に置き換えます。新しいフィルター述語を使用してフィルター処理されたインデックスを再作成し、DROP_EXISTINGを使用するだけです。 オプション:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; これで、さらにいくつかの行を追加し、パーティションの統計を確認し、前のクエリと新しいクエリを実行して、使用されているインデックスを確認できます。
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; この場合、11月のクエリでクラスター化されたインデックススキャンを取得します:
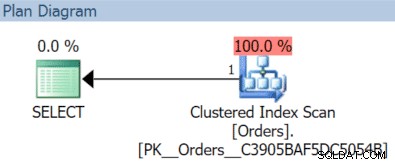
(ただし、OrderDateをキーとして、フィルター処理されていない個別のインデックスがある場合は異なります。)
また、再度表示することはしませんが、12月のクエリでは、以前と同じフィルター処理されたインデックスシークを取得します。
また、複数のインデックスを維持することもできます。1つは今月、もう1つは前月などで、それらを個別に管理できます(たとえば、12月1日にインデックスを10月から削除し、11月はそのままにします)。 。また、より短いまたはより長い期間(現在および前の週、現在および前の四半期)などの複数のインデックスを維持することもできます。ソリューションは非常に柔軟です。
フィルタされたインデックスの制限により、これを完全なソリューションとしてプッシュしたり、テーブルのパーティション分割やパーティション分割されたビューを完全に置き換えたりすることはしません。たとえば、パーティションの切り替えはメタデータ操作であり、DROP_EXISTINGを使用してインデックスを再作成します。 多くのログを記録できます(Enterprise Editionを使用していないため、オンラインで実行できません)。また、パーティション化されたビューの方が速度が速い場合もあります。個別の物理テーブルとパーティション化されたビューを可能にする制約を維持するための作業が増えますが、クエリのパフォーマンスの面で見返りが得られる場合もあります。
自動化
インデックスを再作成する操作は、月に1回(または「ホット」ウィンドウサイズが何であれ)このようなことを行う単純なジョブを使用して、非常に簡単に自動化できます。
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
将来のパーティションを事前に作成するのと同じように、数か月前に複数のインデックスを作成することもできます。結局のところ、将来のインデックスは、述語に関連するデータが存在するまでスペースを占有しません。そして、今は冷たくしたい古いデータをセグメント化していたインデックスを削除するだけです。
後知恵
もちろん、この記事を読み終えた後、キンバリー・トリップの別の投稿に出くわしました。ここで提唱していること(そして始める前に読んだこと)を進める前に読んでおく必要があります:
- パーティション化の代わりにフィルター処理されたインデックスはどうですか?
複数の理由から、Kimberlyは、Standard Editionのパーティション化に似たものを実装するために、パーティション化されたビューをはるかに支持しています。ただし、特定のシナリオでは、フィルター処理されたインデックスを使用することで、実験を続けるのに十分な興味をそそられます。フィルタリングされたインデックスが役立つ可能性のある領域の1つは、「ホット」データに複数の基準がある場合です。日付だけでなく、他の属性によってもスライスされます(特定の層の今月のすべての注文に対して迅速なクエリが必要な場合があります)顧客のまたは特定の金額以上)
次へ…
将来の投稿では、実際のボリュームとワークロードを使用して、ハイエンドシステムでこの概念を試してみます。このソリューション、フィルター処理されていないカバーインデックス、パーティションビュー、およびパーティションテーブルのパフォーマンスの違いを発見したいと思います。 SSDのみが利用可能なラップトップ上のVMの内部では、大規模な現実的または公正なテストが得られない可能性があります。