人々は、例外を防ぐために最善を尽くすべきか、それとも単にシステムに例外を処理させるべきか疑問に思います。エラー処理は「高価」であるため、例外を防ぐためにできることは何でもするべきかどうかについて人々が議論するいくつかの議論を見てきました。エラー処理が無料ではないことは間違いありませんが、制約違反は、少なくとも潜在的な違反を最初にチェックするのと同じくらい効率的であると私は予測します。たとえば、これはキー違反と静的制約違反では異なる場合がありますが、この投稿では前者に焦点を当てます。
例外に対処するために人々が使用する主なアプローチは次のとおりです。
- エンジンに処理させて、例外を呼び出し元に戻します。
-
BEGIN TRANSACTIONを使用します およびROLLBACK@@ERROR <> 0の場合 。 -
TRY/CATCHを使用しますROLLBACKを使用CATCHで ブロック(SQL Server 2005以降)。
そして、多くの人は、最初に違反が発生するかどうかを確認する必要があるというアプローチを取ります。これは、エンジンに強制的に実行させるよりも、自分で複製を処理する方がクリーンなように見えるためです。私の理論では、信頼する必要がありますが、検証する必要があります。たとえば、次のアプローチ(主に擬似コード)を検討してください。
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
IF NOT EXISTS チェックは、INSERTに到達するまでに他の誰かが行を挿入していないことを保証するものではありません。 (テーブルに積極的なロックを設定したり、SERIALIZABLEを使用したりしない限り )が、外部チェックにより、失敗をコミットしてからロールバックする必要がなくなります。 TRY/CATCH全体を使用しないようにします INSERTがすでにわかっている場合は構造 失敗し、少なくとも場合によっては、TRY/CATCHを入力するよりも効率的であると想定するのが論理的です。 無条件に構造。これは、単一のINSERTではほとんど意味がありません シナリオですが、そのTRYでさらに多くのことが起こっている場合を想像してみてください ブロック(および事前に確認できる潜在的な違反が増えます。つまり、後で違反が発生した場合に実行してロールバックする必要がある可能性のあるさらに多くの作業を意味します)。
さて、特に同時実行性で、デフォルト以外の分離レベル(将来の投稿で扱うもの)を使用した場合に何が起こるかを見るのは興味深いでしょう。ただし、この投稿では、ゆっくりと始めて、1人のユーザーでこれらの側面をテストしたいと思いました。 dbo.[Objects]というテーブルを作成しました 、非常に単純な表:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
このテーブルに100,000行のサンプルデータを入力したかったのです。名前列の値を一意にするために(PKは違反したい制約であるため)、行数と最小文字列を受け取るヘルパー関数を作成しました。最小文字列は、(a)セットがObjectsテーブルの最大値を超えて開始されたこと、または(b)セットがObjectsテーブルの最小値で開始されたことを確認するために使用されます。 (テスト中にこれらを手動で指定し、データを検査するだけで検証しますが、おそらくそのチェックを関数に組み込むこともできます。)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
これはCROSS JOINを適用します sys.all_objectsの それぞれに一意のrow_numberを追加して、最初の10個の結果は次のようになります。
テーブルに100,000行を入力するのは簡単でした:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
ここで、新しい一意の値をテーブルに挿入するので、各テストの最初と最後にクリーンアップを実行するプロシージャを作成しました。追加した新しい行を削除するだけでなく、クリーンアップも行います。キャッシュとバッファ。もちろん、本番システムのプロシージャにコーディングしたいものではありませんが、ローカルパフォーマンステストには問題ありません。
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
また、各テストの開始時刻と終了時刻を追跡するためのログテーブルを作成しました:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
最後に、テストストアドプロシージャはさまざまなことを処理します。上記の箇条書きで説明されているように、3つの異なるエラー処理方法があります。「JustInsert」、「Rollback」、および「TryCatch」です。また、3つの異なる挿入タイプがあります:(1)すべての挿入が成功する(すべての行が一意である)、(2)すべての挿入が失敗する(すべての行が重複する)、および(3)半分の挿入が成功する(半分の行が一意であり、半分行は重複しています)。これと相まって、2つの異なるアプローチがあります。挿入を試みる前に違反をチェックするか、先に進んでエンジンに違反が有効かどうかを判断させます。これにより、さまざまなエラー処理手法とさまざまな衝突の可能性を組み合わせて、衝突率の高低が結果に大きな影響を与えるかどうかを確認できると思いました。
これらのテストでは、挿入試行の総数として40,000行を選択し、手順では、20,000の一意または非一意の行と20,000の他の一意または非一意の行の結合を実行します。手順でカットオフ文字列をハードコーディングしたことがわかります。システムでは、これらのカットオフはほぼ確実に別の場所で発生することに注意してください。
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
これで、さまざまな引数を使用してこのプロシージャを呼び出し、40,000の値を挿入しようとして、目的のさまざまな動作を取得できます(もちろん、それぞれの場合に成功または失敗する値がいくつあるかがわかります)。各「エラー処理方法」(挿入を試行する、begin tran / rollback、またはtry / catchを使用)および各挿入タイプ(すべて成功、半分成功、成功なし)について、違反をチェックするかどうかと組み合わせますまず、これにより18の組み合わせが得られます:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
これを実行した後(私のシステムでは約8分かかります)、ログにいくつかの結果があります。バッチ全体を5回実行して、適切な平均が得られたことを確認し、異常を滑らかにしました。結果は次のとおりです。
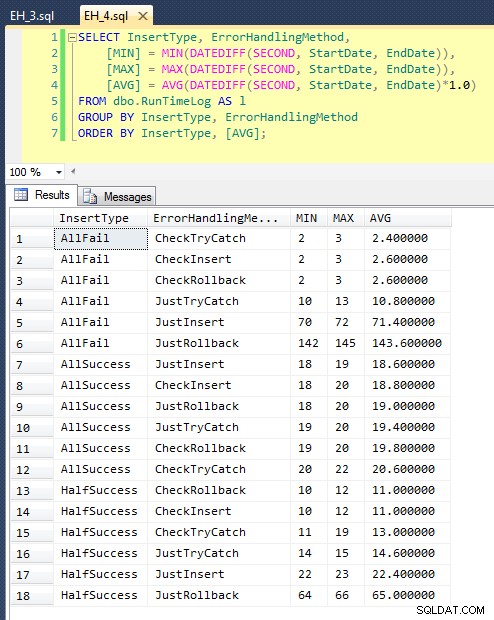
すべての期間を一度にプロットするグラフは、いくつかの重大な外れ値を示しています。
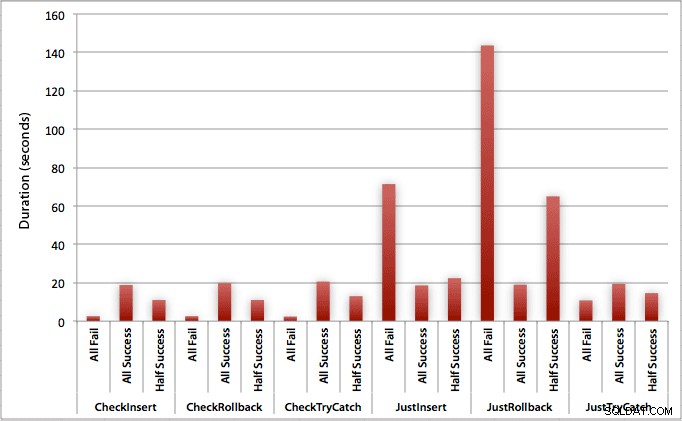
高い失敗率(このテストでは100%)が予想される場合、トランザクションを開始してロールバックすることは、エンジンを上げるだけで、はるかに魅力的でないアプローチ(1回の試行で3.59ミリ秒)であることがわかります。エラーは約半分です(1回の試行で1.785ミリ秒)。次に最悪のパフォーマンスを示したのは、トランザクションを開始してからロールバックする場合で、試行の約半分が失敗すると予想されるシナリオでした(1回の試行あたり平均1.625ミリ秒)。グラフの左側にある9つのケースでは、最初に違反をチェックしていますが、1回の試行で0.515ミリ秒を超えることはありませんでした。
そうは言っても、各シナリオ(成功率が高い、失敗率が高い、50-50)の個々のグラフは、実際に各方法の影響を示しています。
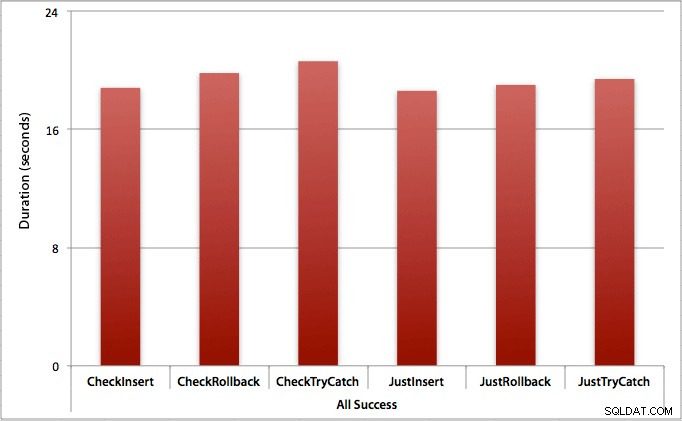
すべての挿入が成功する場所
この場合、最初に違反をチェックするオーバーヘッドはごくわずかであり、バッチ全体で平均0.7秒(または挿入試行ごとに125マイクロ秒)の差があることがわかります。
挿入の半分だけが成功する場合
挿入の半分が失敗すると、挿入/ロールバックメソッドの期間が大幅に短縮されます。トランザクションを開始してロールバックするシナリオは、最初にチェックする場合と比較して、バッチ全体で約6倍遅くなります(1回の試行で1.625ミリ秒であるのに対し、1回の試行で0.275ミリ秒)。最初にチェックすると、TRY / CATCHメソッドでさえ11%高速です:
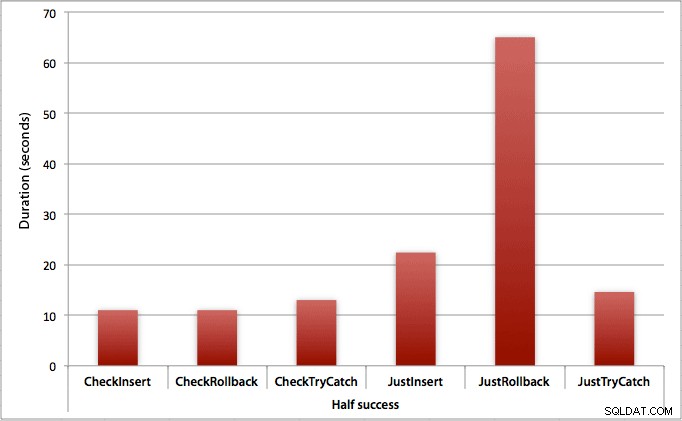
すべての挿入が失敗した場合
ご想像のとおり、これはエラー処理の最も顕著な影響と、最初にチェックすることの最も明白な利点を示しています。この場合、チェックしない場合のロールバック方法は、チェックする場合と比較して約70倍遅くなります(1回の試行で3.59ミリ秒であるのに対し、1回の試行で0.065ミリ秒):
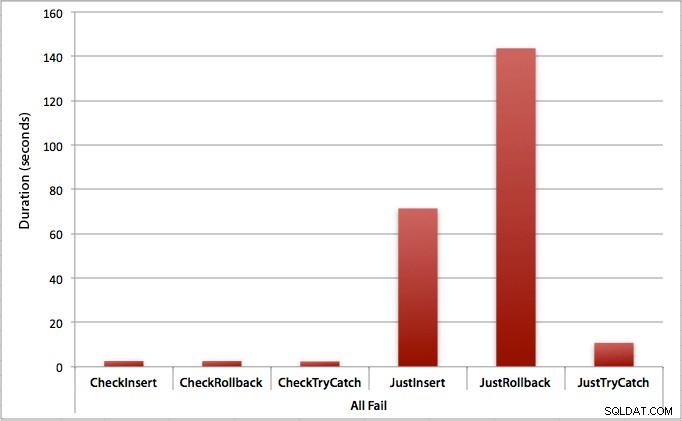
これは私たちに何を伝えますか?故障率が高くなると思われる場合、または潜在的な故障率がわからない場合は、エンジンの違反を回避するために最初にチェックすることは、しばらくの間非常に価値があります。毎回挿入が成功した場合でも、最初にチェックするコストはわずかであり、後でエラーを処理する潜在的なコストによって簡単に正当化されます(予想される失敗率が正確に0%でない限り)。
したがって、今のところ、SQL Serverに先に進んで挿入するように指示する前に、単純なケースでは潜在的な違反をチェックすることが理にかなっているという私の理論に固執すると思います。将来の投稿では、さまざまな分離レベル、同時実行性、さらには他のいくつかのエラー処理手法がパフォーマンスに与える影響について見ていきます。
[余談ですが、2月にmssqltips.comのヒントとしてこの投稿の要約版を書きました。]