私は家を片付けようとしています(夏の終わりに春の掃除として家を捨てるには遅すぎます)。ご存知のとおり、クローゼットを掃除し、子供のおもちゃを調べ、地下室を整理します。それは骨の折れるプロセスです。 10年前に家に引っ越したときは、とても広い部屋がありました。今ではどこにでもあるような気がします。本当に探しているものを見つけるのが難しくなり、クリーンアップと整理に時間がかかります。
これはあなたが管理しているデータベースのように聞こえますか?
私が扱ってきた多くのクライアントは、後付けとしてデータのパージを扱っています。実装時には、誰もがすべてを保存したいと考えています。 「いつ必要になるかわかりません。」 1、2年後、誰かがデータベースに余分なものがたくさんあることに気づきましたが、今では人々はそれを取り除くことを恐れています。 「削除できるかどうかを法務部門に確認する必要があります。」しかし、誰もLegalに確認しません。または、誰かが確認した場合、Legalは事業主に戻って何を保持するかを尋ねると、プロジェクトは停止します。 「何を削除できるかについて合意に達することはできません。」プロジェクトは忘れられ、2、4年後にはデータベースが突然テラバイトになり、管理が難しくなり、人々はデータベースのサイズに関するすべてのパフォーマンスの問題を非難します。 「パーティショニング」や「アーカイブデータベース」という言葉が飛び交うのを耳にしますが、時には、独自の問題を抱えている大量のデータを削除するだけになることもあります。
理想的には、実装前、または稼働開始から最初の6〜12か月以内にパージ戦略を決定する必要があります。しかし、その段階を過ぎたので、この追加データがどのような影響を与える可能性があるかを見てみましょう。
テスト方法
ステージを設定するために、Creditデータベースのコピーを取得し、SQLServer2012インスタンスに復元しました。 3つの既存の非クラスター化インデックスを削除し、独自のインデックスを2つ追加しました:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
次に、元の行のセットを複数回再挿入し、日付を少し変更して、テーブルの行数を1,440万に増やしました。
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
最後に、データベースに対して一連のステートメントをそれぞれ4回実行するテストハーネスを設定しました。ステートメントは以下のとおりです。
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
実行した各ステートメントの前に
DBCC DROPCLEANBUFFERS; GO
バッファプールをクリアします。明らかに、これは実稼働環境に対して実行するものではありません。ここでは、各テストの一貫した開始点を提供するためにこれを行いました。
実行するたびに、最初に1440万行を挿入してdbo.chargeテーブルのサイズを増やしましたが、実行ごとにcharge_dtを1年ずつ増やしました。例:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
1440万行を追加した後、テストハーネスを再実行しました。私はこれを6回繰り返し、基本的に6つの「年」のデータを追加しました。 dbo.chargeテーブルは、1999年のデータから始まり、繰り返し挿入された後、2005年までのデータが含まれていました。
結果
実行の結果はここで見ることができます:
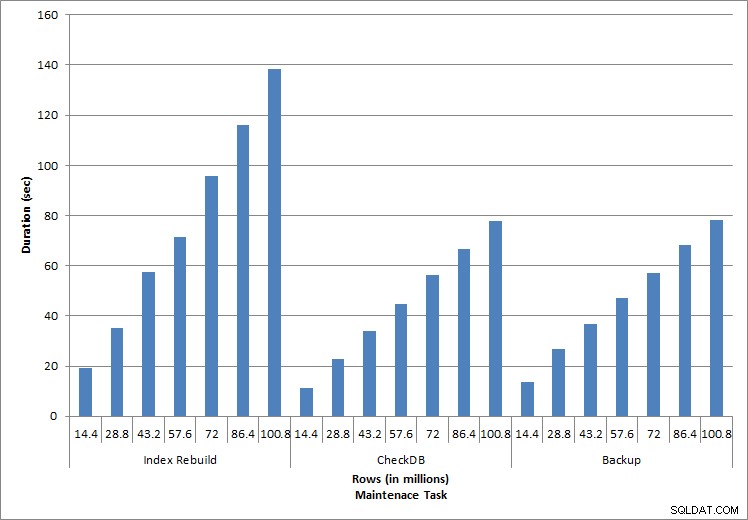
実行される個々のステートメントは、一般的なデータベースアクティビティを反映しています。インデックスの再構築、整合性チェック、およびバックアップは、定期的なデータベースメンテナンスの一部です。料金表に対するクエリは、シングルトンルックアップと、表のデータに固有の範囲スキャンの3つのバリエーションを表します。
インデックスの再構築、CHECKDB、およびバックアップ
メンテナンスタスクで予想されたように、データベースに行が追加されるにつれて、期間とIOの値が増加しました。データベースのサイズは10倍に増加し、期間は同じ割合で増加しませんでしたが、一貫した増加が見られました。各メンテナンスタスクは最初は完了までに20秒もかかりませんでしたが、行が追加されると、タスクの期間はほぼ1分に増加し、1億行の場合は20秒になりました(インデックスの再構築の場合は2分以上になりました)。これは、追加のデータのためにSQLServerがタスクを完了するために必要な追加の時間を反映しています。
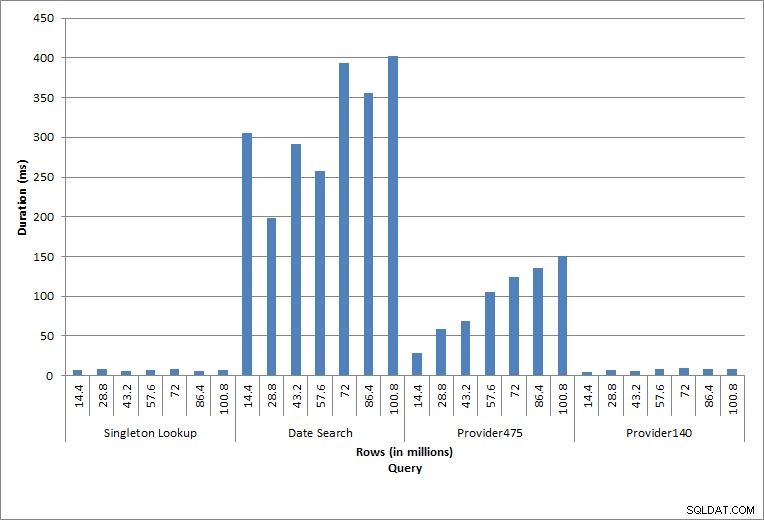
シングルトンルックアップ
特定のcharge_noに対するdbo.chargeに対するクエリは、常に1つの行を生成します。また、charge_noは一意のIDであるため、使用される値に関係なく1つの行を生成します。このルックアップには最小限のバリエーションがあります。行がテーブルに継続的に追加されると、インデックスの深さが1つまたは2つのレベルで増加する可能性があり(テーブルが広くなるにつれてさらに)、2つのIOが追加されますが、これはIOが非常に少ないシングルトンルックアップです。
範囲スキャン
日付範囲(charge_dt)のクエリは、挿入のたびに7月の最新年のデータを検索するように変更されました(たとえば、最後のテストセットの場合は「2005-07-01」から「2005-07-01」)。毎回120万行強。実際のシナリオでは、毎年同じ月に同じ数の行が返されることは期待できません。また、1年の毎月同じ数の行が返されることも期待できません。ただし、行数は月間で同じ範囲内にとどまる可能性があり、時間の経過とともにわずかに増加します。このクエリの期間には変動がありますが、sys.dm_io_virtual_file_statsからキャプチャされたIOデータを確認すると、読み取り数に一貫性があることがわかります。
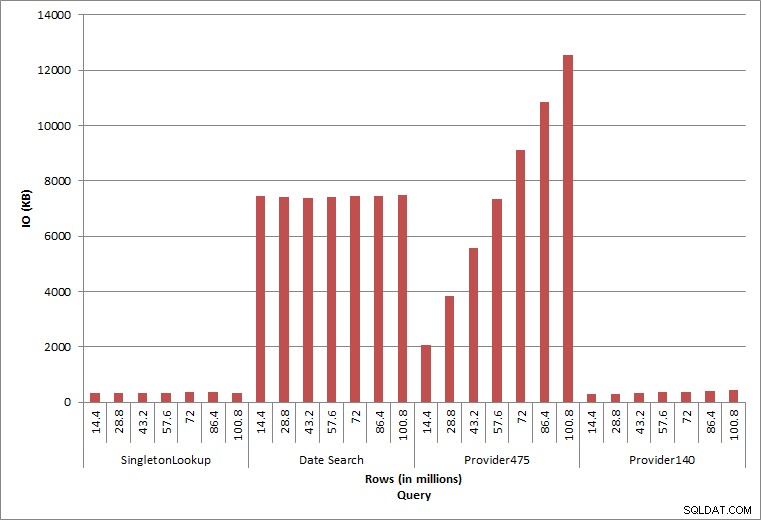
クエリIO
2つの異なるprovider_no値に対する最後の2つのクエリは、データを保持することの真の効果を示しています。最初のdbo.chargeテーブルでは、provider_no 475の行数は126,000を超え、provider_no140の行数は1700を超えていました。追加された1440万行ごとに、provider_noごとにほぼ同じ数の行が追加されました。実稼働環境では、このタイプのデータ分散は珍しくなく、このデータのクエリはソリューションの最初の数年間はうまく機能する可能性がありますが、行が追加されるにつれて時間の経過とともに低下する可能性があります。クエリ期間は、provider_no 475の最初の実行と最後の実行の間に5倍(31ミリ秒から153ミリ秒)増加します。この影響は重要ではないように思われるかもしれませんが、IOの並行増加(上記)に注意してください。これが高頻度で実行されるクエリである場合、および/または定期的に実行される同様のクエリがあった場合、追加の負荷が加算され、全体的なリソース使用量に影響を与える可能性があります。さらに、数十億行あり、複雑な結合を伴うクエリで使用されるテーブルを操作する場合の影響と、通常の、そして非常に重要なメンテナンスタスクへの影響を考慮してください。最後に、回復可能時間を考慮に入れます。災害復旧計画は復元時間に基づいている必要があり、データベースのサイズが大きくなると、データベース全体の復元に時間がかかります。復元のテストとタイミングを定期的に行っていない場合、災害からの復旧に思ったよりも時間がかかる可能性があります。
概要
ここに示す例は、データベースの実装中にデータアーカイブ戦略が決定されなかった場合に発生する可能性のある簡単な図であり、調査およびテストする他の多くのシナリオがあります。アクセスされることはめったにない古いデータは、ディスク上のスペース以上の影響を及ぼします。クエリのパフォーマンスとメンテナンスタスクの期間に影響を与える可能性があります。インスタンス上の複数のデータベースを管理するDBAとして、履歴データを保持する1つのデータベースは、他のデータベースのパフォーマンスおよび保守タスクに影響を与える可能性があります。さらに、レポートが履歴データに対して実行される場合、これはすでにビジー状態のOLTP環境に大混乱をもたらす可能性があります。
最初から、データベース内のデータの寿命を決定し、行動計画を立てることが重要です。一部のソリューションでは、すべてのデータを永久に保持する必要があります。この場合、データベースサイズを管理しやすくするための戦略を採用します。たとえば、データを別のテーブルまたは別のデータベースに定期的にアーカイブします。データを何年にもわたって保存する必要がない場合は、定期的にデータを削除するパージ戦略を実装してください。このようにして、10年に1回ではなく、3か月ごとに使用しなくなったおもちゃ、フィットしなくなった服、ランダムながらくたを捨てることができます。