単一の述語
多くの場合、単一のクエリ述語で修飾された行数を見積もるのは簡単です。述語が列とスカラー値を単純に比較する場合、カーディナリティ推定量である可能性が高くなります。 統計ヒストグラムから高品質の推定値を導き出すことができます。たとえば、次のAdventureWorksクエリは、203行の正確な推定値を生成します(統計が作成されてからデータに変更が加えられていないことを前提としています):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
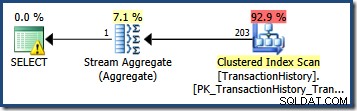
TransactionDateの統計ヒストグラムを見る 列から、この見積もりがどこから来たのかがわかります:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
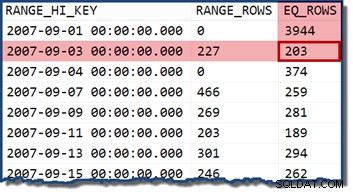
ヒストグラムバケット内に含まれる日付を指定するようにクエリを変更すると、カーディナリティ推定器は値が均等に分散されていると想定します。 2007-09-02の日付を使用する (RANGE_ROWSから)227行の推定値を生成します エントリ)。興味深い補足として、日付値(TransactionDate)に追加する可能性のある時間部分に関係なく、見積もりは227行のままです。 列はdatetime データ型)。
2007-09-05の日付でクエリを再試行した場合 または2007-09-06 (どちらも2007-09-04の間にあります および2007-09-07 ヒストグラムステップ)、カーディナリティ推定器は466 RANGE_ROWSを想定しています は2つの値に均等に分割され、どちらの場合も233行と推定されます。
単純な述語のカーディナリティ推定には他にも多くの詳細がありますが、上記は現在の目的の復習として役立ちます。
複数の述語の問題
クエリに複数の列述語が含まれている場合、カーディナリティの推定はより困難になります。 2つの単純な述語(それぞれを単独で簡単に推定できる)を使用した次のクエリについて考えてみます。
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; クエリ内の値の特定の範囲は、両方の述語がまったく同じ行を識別するように意図的に選択されています。クエリ値を簡単に変更して、オーバーラップがまったくないことを含め、任意の量のオーバーラップをもたらすことができます。あなたがカーディナリティ推定量であると想像してください。このクエリのカーディナリティ推定値をどのように導き出しますか?
問題は最初に聞こえるよりも難しいです。既定では、SQLServerは両方の述語列に単一列の統計を自動的に作成します。複数列の統計を手動で作成することもできます。これにより、これらの特定の値の適切な見積もりを作成するのに十分な情報が得られますか? 何かがあるかもしれないより一般的なケースはどうですか オーバーラップの程度?
2つの単一列の統計オブジェクトを使用すると、前のセクションで説明したヒストグラム法を使用して、各述語の推定値を簡単に導き出すことができます。上記のクエリの特定の値について、ヒストグラムはTransactionIDを示しています 範囲は68412.4と一致することが期待されます 行、およびTransactionDate 範囲は68,413と一致すると予想されます 行。 (ヒストグラムが完全であれば、これら2つの数値はまったく同じになります。)
ヒストグラムでできない これらの2つの行のセットから同じ行がいくつあるかを教えてください 。ヒストグラム情報に基づいて言えることは、推定値はゼロ(オーバーラップがまったくない場合)と68412.4行(完全にオーバーラップしている場合)の間のどこかにある必要があるということです。
複数列の統計を作成しても、このクエリ(または一般的な範囲クエリ)には役立ちません。複数列の統計は、最初の名前の列に対してのみヒストグラムを作成し、基本的に、自動的に作成された統計の1つに関連付けられたヒストグラムを複製します。追加の密度 複数列の統計によって提供される情報は、複数の等式述語を含むクエリの平均的なケースの情報を提供するのに役立ちますが、ここでは役に立ちません。
信頼性の高い見積もりを作成するには、SQLServerがデータ分散に関するより適切な情報を提供する必要があります。多次元などです。 統計ヒストグラム。私の知る限り、このような機能を提供する商用データベースエンジンは現在ありませんが、このテーマに関するいくつかの技術論文が公開されています(SQL Server2000の内部開発を使用したMicrosoftResearchを含む)。
特定の値の範囲のデータの相関関係と重複について何も知らなければ、クエリの適切な見積もりを作成する方法が明確ではありません。では、SQL Serverはここで何をしますか?
SQL Server 7 – 2012
これらのバージョンのSQLServerのカーディナリティ推定器は、通常、テーブル内のさまざまな属性の値が互いに完全に独立して分散されていることを前提としています。この独立性の仮定 実際のデータを正確に反映することはめったにありませんが、計算が簡単になるという利点があります。
および選択性
独立性の仮定を使用して、ANDで接続された2つの述語 (接続詞として知られています )選択性S 1 およびS2 、次の組み合わせの選択性が得られます:
(S1 * S2)
用語がよくわからない場合は、選択性 は0から1までの数値であり、述部を通過するテーブル内の行の割合を表します。たとえば、述語が100行のテーブルから12行を選択する場合、選択性は(12/100)=0.12です。
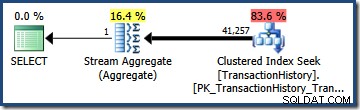
この例では、TransactionHistory テーブルには合計113,443行が含まれています。 TransactionIDの述語 は(ヒストグラムから)68,412.4行を修飾すると推定されるため、選択性は(68,412.4 / 113,443)またはおおよそ 0.603055 。 TransactionDateの述語 同様に、(68,413 / 113,443)=おおよそ 0.603061の選択性があると推定されます 。
(上記の式を使用して)2つの選択性を乗算すると、 0.363679の選択性の推定値が得られます。 。この選択性にテーブルのカーディナリティ(113,443)を掛けると、 41,256.8の最終的な見積もりが得られます。 行:
または選択性
ORで接続された2つの述語 (論理和 )選択性S 1 およびS2 、次の組み合わせの選択性が得られます:
(S1 + S2) – (S1 * S2)
式の背後にある直感は、2つの選択性を加算してから、それらの接続詞の推定値を減算することです(前の式を使用)。明らかに、それぞれが選択性0.8の2つの述語を持つことができますが、それらを単純に加算すると、1.6の不可能な組み合わせ選択性が生成されます。独立性の仮定にもかかわらず、2つの述語が重複している可能性があることを認識しなければならないため、二重カウントを回避するために、接続詞の推定選択性が差し引かれます。
ORを使用するように実行中の例を簡単に変更できます :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
述語の選択性をORに代入する 式は次の組み合わせの選択性を与えます:
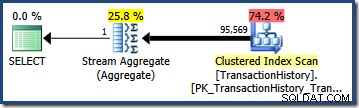
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
表の行数を掛けると、この選択性により、最終的なカーディナリティの見積もりが 95,568.6になります。 :
どちらの見積もりもありません( 41,257 ANDの場合 クエリ; 95,569 ORの場合 query)は、どちらもデータ分布とあまり一致しないモデリングの仮定に基づいているため、特に優れています。どちらのクエリも実際には68,413を返します 行(述語がまったく同じ行を識別するため)。
トレースフラグ4137–最小選択性
SQL Server 2008(R1)から2012までの場合、Microsoftは、ANDの選択性の計算方法を変更する修正をリリースしました。 ケース(接続述語)のみ。そのリンクのナレッジベースの記事には多くの詳細が含まれていませんが、修正により、使用される選択性の式が変更されることがわかりました。個々の選択性を乗算する代わりに、結合述語のカーディナリティ推定では、最も低い選択性のみを使用するようになりました。
変更された動作をアクティブにするには、サポートされているトレースフラグ4137が必要です。別のナレッジベースの記事には、このトレースフラグがQUERYTRACEONを介したクエリごとの使用でもサポートされていることが記載されています。 ヒント:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); このフラグがアクティブな場合、カーディナリティ推定では2つの述語の最小選択性が使用され、 68,412.4の推定値になります。 行:
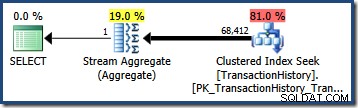
テスト述語は正確に相関しているため、これはクエリにほぼ完璧です(また、基本ヒストグラムから得られた推定値も非常に優れています)。
述語がこのように実際のデータと完全に相関することはかなりまれですが、それでもトレースフラグが役立つ場合があります。最小の選択性の動作は、すべての接続詞(AND)に適用されることに注意してください )クエリ内の述語。より詳細なレベルで動作を指定する方法はありません。
分離(OR)を推定するための対応するトレースフラグはありません )最小の選択性を使用する述語。
SQL Server 2014
データベースの互換性レベルが120未満に設定されている場合、またはトレースフラグ 9481 の場合、SQL Server 2014の選択性の計算は以前のバージョンと同じように動作します(トレースフラグ4137は以前と同じように機能します)。 アクティブです。データベースの互換性レベルの設定は、公式です。 SQL Server 2014で2014年以前のカーディナリティ推定器を使用する方法。トレースフラグ9481は、執筆時点と同じことを行うのに効果的であり、QUERYTRACEONでも機能します。 、そうすることは文書化されていませんが。このフラグのRTMの動作を知る方法はありません。
新しいカーディナリティ推定量がアクティブな場合、SQL Server 2014は、接続詞と論理和の述語を組み合わせるために異なるデフォルトの式を使用します。文書化されていませんが、接続詞の選択式が発見され、文書化されています。私が最初に目にしたのは、このポルトガル語のブログ投稿と、数週間後に発行されたフォローアップパート2です。要約すると、接続述語に対する2014年のアプローチは、指数バックオフ:を使用することです。 カーディナリティC、述語選択性S 1のテーブルが与えられます 、S 2 、S 3 …sn 、ここでS 1 最も選択的でSn 最小:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
推定値は、最も選択的な述語にテーブルのカーディナリティを掛け、次に最も選択的な述語の平方根を掛けて計算され、新しい選択性ごとに追加の平方根が得られます。
選択性は0から1までの数値であることを思い出してください。平方根を適用すると、数値が1に近づくことは明らかです。効果は、最終的な見積もりですべての述語を考慮に入れることですが、選択性の低い述語の影響を減らすことです。指数関数的に。このアイデアには、独立性の仮定よりも間違いなく多くの論理があります。 、ただし、これは固定式です。実際のデータ相関の程度に基づいて変更されることはありません。
2014年のカーディナリティ推定量は、両方の指数バックオフ式を使用します 接続詞と論理和の述語。ただし、論理和で使用される式(OR )ケースはまだ文書化されていません(公式またはその他)。
SQLServer2014選択性トレースフラグ
トレースフラグ4137(最小の選択性を使用するため)はしません クエリのコンパイル時に新しいカーディナリティ推定量が使用される場合は、SQLServer2014で機能します。代わりに、新しいトレースフラグ 9471 があります 。このフラグがアクティブな場合、最小の選択性を使用して、複数の接続詞と論理和を推定します。 述語。これは、接続詞述語にのみ影響する4137の動作からの変更です。
同様に、トレースフラグ 9472 独立を想定するように指定できます 以前のバージョンと同様に、複数の述語に対して。このフラグは9481(2014年以前のカーディナリティ推定量を使用するため)とは異なります。これは、9472では新しいカーディナリティ推定量が引き続き使用され、複数の述語の選択式のみが影響を受けるためです。
執筆時点では、9471も9472も文書化されていません(ただし、RTMにある可能性があります)。
SQL Server 2014で(新しいカーディナリティ推定器がアクティブな状態で)どの選択性の仮定が使用されているかを確認する便利な方法は、トレースフラグ 2363のときに生成される選択性計算のデバッグ出力を調べることです。 および3604 アクティブです。探すセクションは、フィルターを組み合わせた選択性計算機に関連しています。使用されている仮定に応じて、次のいずれかが表示されます。
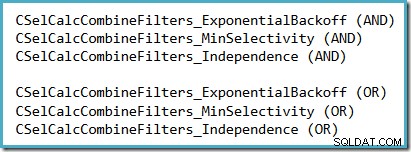
2363が文書化またはサポートされるという現実的な見通しはありません。
最終的な考え
指数バックオフ、最小の選択性、または独立性については何の魔法もありません。それぞれのアプローチは、特定のクエリまたはデータ分散に対して許容可能な見積もりを生成する場合と生成しない場合がある、(非常に)単純化された仮定を表しています。
いくつかの点で、指数バックオフ 独立の両極端の間の妥協点を表します および最小選択性 。それでも、不当な期待を抱かないことが重要です。複数の述語(妥当なパフォーマンス特性を備えた)の選択性を推定するためのより正確な方法が見つかるまで、モデルの制限を認識し、それに応じて(潜在的な)推定エラーに注意することが重要です。
さまざまなトレースフラグにより、使用する仮定をある程度制御できますが、状況は完全ではありません。一つには、フラグを適用できる最も細かい粒度は単一のクエリです。推定動作を述語レベルで指定することはできません。一部の述語が相関し、他の述語が独立しているクエリがある場合、トレースフラグは、何らかの方法でクエリをリファクタリングしないとあまり役に立たない場合があります。同様に、問題のあるクエリには、使用可能なオプションのいずれかによって適切にモデル化されていない述語相関が含まれている可能性があります。
トレースフラグをアドホックに使用するには、DBCC TRACEONと同じ権限が必要です。 –つまり、 sysadmin 。個人的なテストではおそらく問題ありませんが、本番環境ではQUERYTRACEONを使用したプランガイドを使用してください ヒントはより良いオプションです。プランガイドを使用すると、クエリを実行するために追加の権限は必要ありません(もちろん、プランガイドを作成するには昇格された権限が必要です)。