時々、誰かがキーのランダムな番号を作成する必要があると表明するのを目にします。通常、これは、ある範囲内の一意の番号であるが、順番に発行されないため、IDENTITYよりもはるかに推測しにくいタイプの代理CustomerIDまたはUserIDを作成するためのものです。 値。
NEWID() 推測の問題を解決しますが、特にクラスター化されている場合、パフォーマンスの低下は通常、大きな問題になります。整数よりもはるかに幅の広いキーと、非順次値によるページ分割です。 NEWSEQUENTIALID() ページ分割の問題を解決しますが、それでも非常に幅広いキーであり、次の値(または最近発行された値)をある程度の精度で推測できるという問題を再導入します。
その結果、彼らはランダムなとを生成する手法を望んでいます。 一意の整数。 RAND()のようなメソッドを使用して、それ自体でランダムな数値を生成することは難しくありません。 またはCHECKSUM(NEWID()) 。問題は、衝突を検出する必要があるときに発生します。 CustomerIDの値が1〜1,000,000であると仮定して、一般的なアプローチを簡単に見てみましょう。
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END テーブルが大きくなると、重複のチェックにかかる費用が高くなるだけでなく、重複を生成する確率も高くなります。したがって、このアプローチはテーブルが小さい場合は問題なく機能するように見えるかもしれませんが、時間の経過とともにますます傷つく必要があると思います。
別のアプローチ
私は補助テーブルの大ファンです。私は10年間、カレンダーテーブルと数値テーブルについて公に書いてきましたが、それらをずっと長く使用しています。そして、これは、事前に入力されたテーブルが本当に便利になると思う場合です。実行時に乱数を生成し、潜在的な重複を処理することに依存するのはなぜですか。これらの値をすべて事前に入力して、テーブルを不正なDMLから保護する場合は、100%確実に、次に選択する値がこれまでにないことを確認できます。以前に使用しましたか?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; この母集団は(ラップトップのVMで)作成するのに9秒かかり、ディスク上で約17MBを占有しました。表のデータは次のようになります:
(数値がどのように入力されるかが心配な場合は、[値]列に一意の制約を追加して、テーブルを30 MBにすることができます。ページ圧縮を適用した場合、それぞれ11MBまたは25MBになります。 )
テーブルの別のコピーを作成し、同じ値を入力して、次の値を導出する2つの異なる方法をテストできるようにしました。
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
これで、新しいランダムな番号が必要なときはいつでも、既存の番号のスタックから1つポップして、それを削除できます。これにより、重複を心配する必要がなくなり、クラスター化されたインデックスを使用して、実際にはすでにランダムな順序になっている番号を取得できます。 (厳密に言えば、削除する必要はありません。 使用する数値。値が使用されたかどうかを示す列を追加できます。これにより、顧客が後で削除された場合や、このトランザクションの外部で完全に作成される前に問題が発生した場合に、その値を簡単に復元して再利用できます。)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
構成可能なDMLにはさまざまな制限があり、DELETEから直接Customersテーブルに挿入できないため、テーブル変数を使用して中間出力を保持しました。 (たとえば、外部キーの存在)。それでも、それが常に可能であるとは限らないことを認めて、私もこの方法をテストしたかった:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
これらのソリューションはどちらも、特に乱数表に他のインデックス([値]列の一意のインデックスなど)がある場合、ランダムな順序を真に保証するものではないことに注意してください。 DELETEの順序を定義する方法はありません TOPを使用する;ドキュメントから:
したがって、ランダムな順序を保証したい場合は、代わりに次のようにすることができます:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; ここでのもう1つの考慮事項は、これらのテストでは、CustomersテーブルのCustomerID列にクラスター化された主キーがあることです。ランダムな値を挿入すると、これは確かにページ分割につながります。現実の世界では、この要件がある場合、おそらく別の列でクラスタリングすることになります。
ここではトランザクションとエラー処理も省略していることに注意してください。ただし、これらも本番コードの考慮事項となるはずです。
パフォーマンステスト
現実的なパフォーマンスの比較を行うために、次のシナリオを表す5つのストアドプロシージャを作成しました(さまざまなランダムメソッドのテスト速度、分布、衝突頻度、および事前定義された乱数表の使用速度):
>-
CHECKSUM(NEWID())を使用したランタイム生成 -
CRYPT_GEN_RANDOM()を使用したランタイム生成 -
RAND()を使用したランタイム生成 - テーブル変数を含む事前定義された数値テーブル
- 直接挿入付きの事前定義された数値テーブル
ロギングテーブルを使用して、衝突の期間と数を追跡します。
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
手順のコードは次のとおりです(クリックして表示/非表示):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO そして、これをテストするために、各ストアドプロシージャを1,000,000回実行します。
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
当然のことながら、事前定義された乱数表を使用するメソッドは、毎回読み取りと書き込みの両方のI / Oを実行する必要があるため、*テストの開始時に*少し時間がかかりました。これらの数値はマイクロ秒であることに注意してください 、これは、途中のさまざまな間隔での各プロシージャの平均期間です(最初の10,000回の実行、中間の10,000回の実行、最後の10,000回の実行、および最後の1,000回の実行の平均):
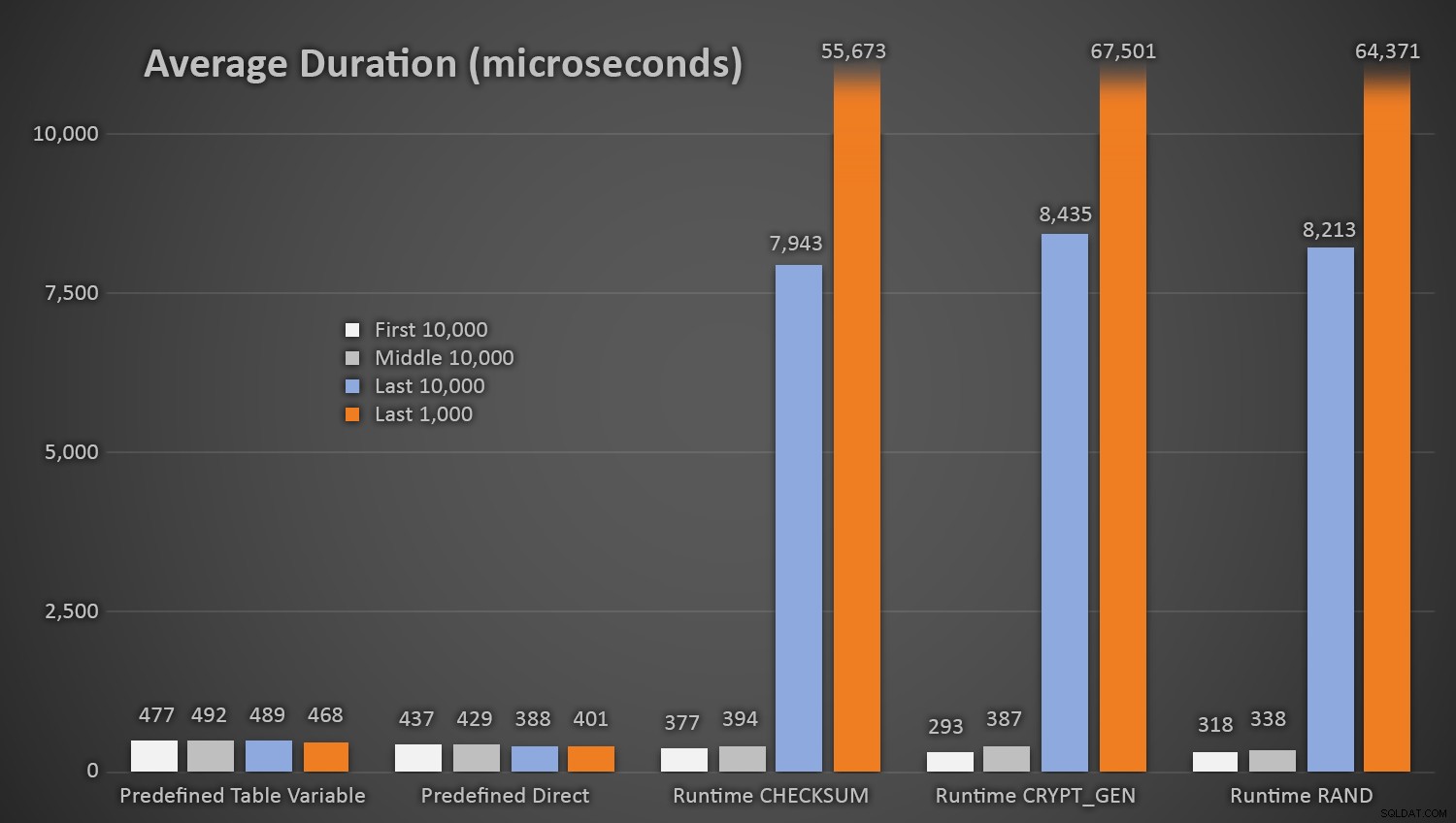
さまざまなアプローチを使用したランダム生成の平均継続時間(マイクロ秒単位)
これは、Customersテーブルに行が少ない場合はすべてのメソッドでうまく機能しますが、テーブルが大きくなるにつれて、ランタイムメソッドを使用して既存のデータに対して新しいランダム数をチェックするコストが大幅に増加します。 / Oであり、衝突の数が増えるためです(再試行する必要があります)。次の範囲の衝突カウントの場合の平均期間を比較します(このパターンはランタイムメソッドにのみ影響することに注意してください):
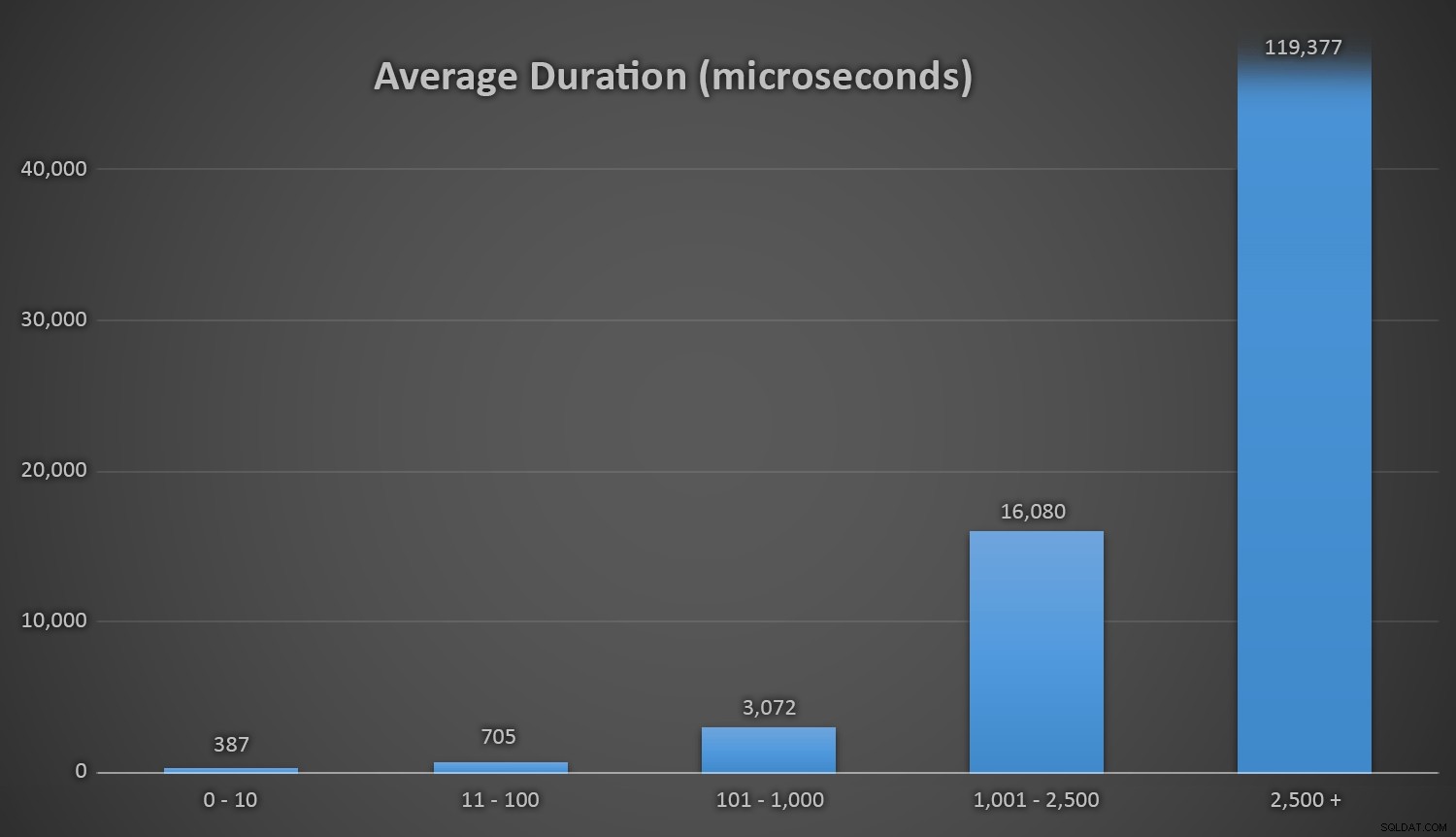
さまざまな範囲の衝突中の平均継続時間(マイクロ秒単位)
衝突数に対して期間をグラフ化する簡単な方法があればいいのにと思います。最後の3つの挿入で、次のランタイムメソッドは、探していた最後の一意のIDに最終的に遭遇する前に、これだけ多くの試行を実行する必要がありました。これにかかった時間は次のとおりです。
>| 衝突の数 | 期間(マイクロ秒) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 最後から3番目の行 | 63,545 | 639,358 |
| 最後から2番目の行 | 164,807 | 1,605,695 | |
| 30,630 | 296,207 | ||
| CRYPT_GEN_RANDOM() | 最後から3番目の行 | 219,766 | 2,229,166 |
| 最後から2番目の行 | 255,463 | 2,681,468 | |
| 136,342 | 1,434,725 | ||
| RAND() | 最後から3番目の行 | 129,764 | 1,215,994 |
| 最後から2番目の行 | 220,195 | 2,088,992 | |
| 440,765 | 4,161,925 | ||
行の終わり近くでの過度の継続時間と衝突
興味深いことに、最後の行が常に衝突の数が最も多い行であるとは限らないため、999,000以上の値を使い切るずっと前に、これが実際の問題になり始める可能性があります。
別の考慮事項
RandomNumbersテーブルが特定の行数を下回り始めたときに、ある種のアラートまたは通知を設定することを検討することをお勧めします(その時点で、たとえば、1,000,001〜2,000,000の新しいセットをテーブルに再入力できます)。その場で乱数を生成する場合も同様のことを行う必要があります。それを1〜1,000,000の範囲内に維持する場合は、コードを変更して、別の範囲から乱数を生成する必要があります。これらの値をすべて使い果たしました。
実行時に乱数を使用している場合は、乱数を抽出するプールサイズを絶えず変更することで、この状況を回避できます(これにより、衝突の数も安定し、大幅に減少します)。たとえば、次の代わりに:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
すでにテーブルにある行数に基づいてプールを作成できます:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
今、あなたの唯一の本当の心配は、INTの上限に近づくときです …
注:最近、MSSQLTips.comでこれに関するヒントを書きました。