インデックス付きビューは、SQL Serverのどのエディションでも作成できますが、それらを最大限に活用する場合は、注意すべき動作がいくつかあります。
自動統計にはNOEXPANDヒントが必要です
SQL Serverは統計を自動的に作成して、クエリの最適化中にカーディナリティの見積もりとコストベースの意思決定を支援します。この機能は、インデックス付きビューとベーステーブルで機能しますが、ビューがクエリとNOEXPANDで明示的に指定されている場合に限ります。 ヒントが指定されています。 (ビューの各インデックスに関連付けられた統計オブジェクトは常に存在します。ここで説明しているのは、インデックスに関連付けられていない統計の自動生成と保守です。)
SQL ServerのEnterprise以外のエディションでの作業に慣れている場合は、これまでこの動作に気づいたことがないかもしれません。 SQL Serverの下位エディションには、NOEXPANDが必要です。 インデックス付きビューにアクセスするクエリプランを作成するためのヒント。 NOEXPANDの場合 が指定されている場合、通常のテーブルの場合とまったく同じように、インデックス付きビューに自動統計が作成されます。
例–NOEXPANDを使用したStandardEdition
SQL Server 2012 StandardEditionとAdventureWorksサンプルデータベースを使用して、最初に2つの販売テーブルを結合し、顧客および製品ごとの合計注文数量を計算するビューを作成します。
CREATE VIEW dbo.CustomerOrders
WITH SCHEMABINDING AS
SELECT
SOH.CustomerID,
SOD.ProductID,
OrderQty = SUM(SOD.OrderQty),
NumRows = COUNT_BIG(*)
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY
SOH.CustomerID,
SOD.ProductID; このビューで統計をサポートするには、一意のクラスター化されたインデックスを追加して、このビューを具体化する必要があります。顧客IDと製品IDの組み合わせは、ビュー内で(定義上)一意であることが保証されているため、これをキーとして使用します。インデックスでどちらの方法でも2つの列を指定できますが、製品でフィルタリングするクエリが増えると想定して、製品IDを先頭の列にします。このアクションは、製品ID値から作成されたヒストグラムを使用してインデックス統計も作成します。
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
ここで、特定の範囲の製品について、顧客ごとの注文の総数を示すクエリを作成するように求められます。インデックス付きビューを使用した実行プランは、結合を回避し、すでに部分的に集約されているデータを操作するため、効果的な戦略になると予想されます。 SQL Server Standard Editionを使用しているため、ビューを明示的に指定し、NOEXPANDを使用する必要があります。 インデックス付きビューにアクセスするクエリプランを作成するためのヒント:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
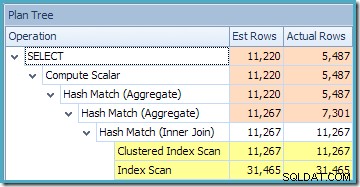
CO.CustomerID; 作成された実行プランは、関心のある製品の行を見つけるためのインデックス付きビューのシークと、それに続く顧客ごとの合計数量を計算するための集計を示しています。
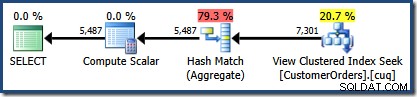
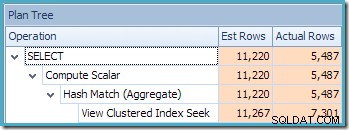
SQL Sentry Plan Explorerのプランツリービューは、カーディナリティ推定がインデックス付きビューシークに対して正確に正しく、集計の結果に対して非常に優れていることを示しています。
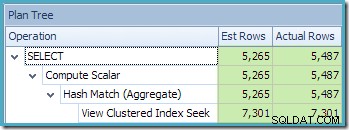
このクエリのコンパイルおよび最適化プロセスの一環として、SQLServerはインデックス付きビューの[顧客ID]列に追加の統計オブジェクトを作成しました。この統計は、顧客IDの予想される数と分布が、たとえば集計戦略の選択などで重要になる可能性があるために作成されています。 Management Studio Object Explorerを使用して新しい統計を確認できます:
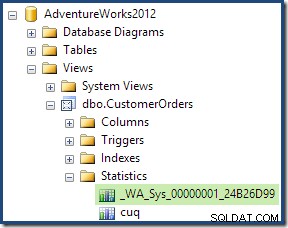
統計オブジェクトをダブルクリックすると、ビューの[顧客ID]列から作成されたことが確認されます(ベーステーブルではありません):
インデックス付きビューはカーディナリティ推定を改善できます
引き続きStandardEditionを使用して、インデックス付きビューを削除して再作成し(ビュー統計も削除します)、今回はNOEXPANDを使用してクエリを再実行します。 ヒントがコメントアウトされました:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
NOEXPANDなしでStandardEditionを使用すると予想どおり 、結果のクエリプランは、ビューを直接表示するのではなく、ベーステーブルを操作します。

上記の計画のルート演算子の三角表示板は、販売注文詳細テーブルの潜在的に有用なインデックスを警告しています。これは、現在の目的では重要ではありません。このコンパイルでは、インデックス付きビューに統計は作成されません。クエリのコンパイル後のビューの唯一の統計は、クラスター化されたインデックスに関連付けられている統計です:
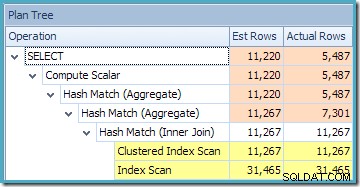
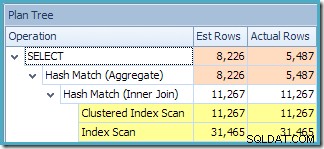
クエリのプランツリービューは、カーディナリティの推定が2つのテーブルスキャンと結合に対して正しいことを示していますが、他のプラン演算子についてはかなり悪いです:
NOEXPANDでインデックス付きビューを使用する ヒントは、ビューの統計、特にビューインデックスに関連付けられた統計からより良い品質の情報が得られたため、テストクエリのより正確な推定値をもたらしました。
原則として、統計情報の精度は、クエリプランの演算子を通過して変更されると、非常に急速に低下します。多くの場合、単純な結合はこの点でそれほど悪くはありませんが、集計の結果に関する情報は、知識に基づいた推測に勝るものはありません。インデックス付きビューの統計を使用してクエリオプティマイザにさらに正確な情報を提供することは、プランの品質と堅牢性を向上させるための便利な手法です。
NOEXPANDのないビューは、劣った計画を作成する可能性があります
上記のクエリプラン(Standard Edition、NOEXPANDなし )は、クエリオプティマイザがビューを拡張できるようにするのではなく、ベーステーブルに対してクエリを自分で記述した場合よりも実際には最適ではありません。以下のクエリは同じ論理要件を表していますが、ビューを参照していません:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
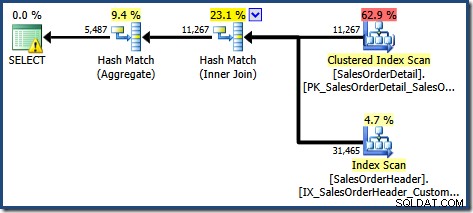
SOH.CustomerID; このクエリは、次の実行プランを生成します。
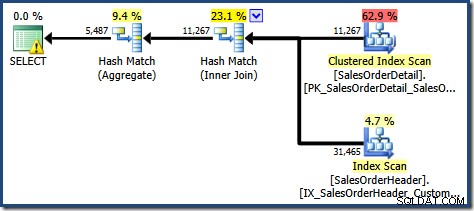
このプランでは、以前よりも集計操作が1つ少なくなっています。ビュー拡張が使用された場合、クエリオプティマイザは残念ながら冗長な集計操作を削除できなかったため、実行プランの効率が低下しました。新しいクエリの最終的なカーディナリティの見積もりも、インデックス付きビューがNOEXPANDなしで参照された場合よりもわずかに優れています。 :
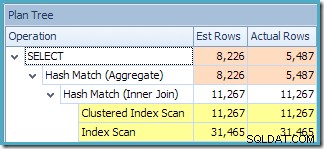
それでもなお、最良の推定値は、インデックス付きビューをNOEXPANDで参照したときに生成される推定値です。 (便宜上、以下で繰り返します):
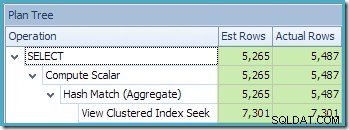
EnterpriseEditionとビューマッチング
Enterprise Editionインスタンスでは、クエリがビューに明示的に言及していなくても、クエリオプティマイザはインデックス付きビューを使用できる場合があります。オプティマイザがクエリツリーの一部をインデックス付きビューに一致させることができる場合、ビューを使用するかどうかのコストの見積もりに基づいて、オプティマイザはそうすることを選択できます。ビューマッチングロジックはかなり巧妙ですが、実際には非常に簡単にヒットできる制限があります。ビューのマッチングが成功した場合でも、不正確なコスト見積もりによってオプティマイザが誤解される可能性があります。
EXPANDVIEWSクエリのヒント
まれな可能性から始めて、クエリがインデックス付きビューを参照する場合がありますが、代わりにベーステーブルにアクセスすることでより良い計画が得られます。このような状況では、クエリヒントEXPAND VIEWS 使用可能:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID
OPTION (EXPAND VIEWS);
Enterprise Editionでは、このクエリは、NOEXPANDの場合にStandardEditionで見られるのと同じプランを生成します。 ヒントが省略されました(冗長な集計操作を含む):

余談ですが、EXPAND VIEWS 私の意見では、ヒントの名前は不十分です。 NOEXPANDでない限り、SQLServerは常にクエリ内のビュー定義を展開します ヒントが指定されています。 EXPAND VIEWS ヒントは、拡張されたツリーの一部をインデックス付きビューに一致させることができるオプティマイザーのルールを無効にします。いずれかのヒントがない場合、SQL Serverは最初にビューをそのベーステーブル定義に展開し、次にインデックス付きビューへのマッチングを検討します。 EXPAND VIEWSのより適切な名前 ヒントはDISABLE INDEXED VIEW MATCHINGであった可能性があります 、それがそれがすることだからです。
EXPAND VIEWS ヒントは、ベーステーブルに対するクエリがインデックス付きビューに一致しないようにするためにおそらく最もよく使用されます:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID
OPTION (EXPAND VIEWS);> クエリヒントは、StandardEditionと同じベーステーブルのみのクエリを使用したときに見られるのと同じ実行プランと見積もりになります。
エンタープライズビューのマッチングと統計
Enterprise Editionでも、インデックス以外のビューの統計は、NOEXPANDの場合にのみ作成されます。 ヒントが使用されます。完全に明確にするために、エンタープライズのみのビューマッチング機能では、ビュー統計が作成または更新されることはありません。この直感的でない動作は、驚くべき副作用をもたらす可能性があるため、少し調べる価値があります。
ここで、ヒントなしでEnterpriseEditionインスタンスのビューに対して基本的なクエリを実行します。
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
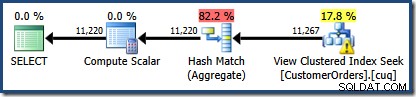
新しいものは、View ClusteredIndexSeekに三角表示板があります。ツールチップに詳細が表示されます:
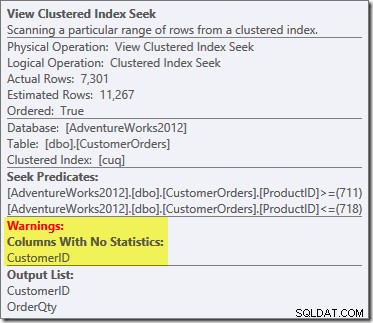
NOEXPANDは使用しませんでした ヒントであるため、インデックス付きビューの[顧客ID]列の統計は自動的に作成されませんでした。この簡略化された例では、顧客IDの統計は実際にはそれほど重要ではありませんが、常にそうであるとは限りません。
奇妙なカーディナリティの推定値
2つ目の興味深い点は、カーディナリティの推定値が、Standard Editionの例を含め、これまでに遭遇したどのケースよりも悪いように見えることです。
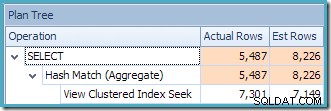
View Clustered Index Seek(11,267)のカーディナリティ推定がどこから来たのかを最初に確認することは困難です。見積もりは、ビュークラスター化インデックスに関連付けられた統計からの製品IDヒストグラム情報に基づいていると予想されます。このヒストグラムの関連部分を以下に示します。
DBCC SHOW_STATISTICS
('dbo.CustomerOrders', 'cuq')
WITH HISTOGRAM;
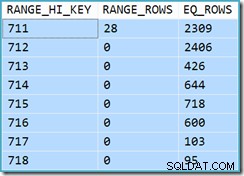
統計が作成されてからテーブルが変更されていない場合、見積もりは711〜718の製品ID値のRANGE_ROWSとEQ_ROWSの単純な合計であると予想されます(見積もりでは、711エントリに対して表示される28のRANGE_ROWSを除外する必要があります)。これらの行は711キー値の下に存在するため)。表示されているEQ_ROWSの合計は7,301です。これは、ビューによって実際に返された行の数とまったく同じです。11,267の見積もりはどこから来たのですか?
その答えは、ビューマッチングが現在機能している方法にあります。クエリでNOEXPANDが指定されていません ヒントなので、最初のカーディナリティ推定は、ビュー拡張クエリツリーに基づいています。これは、EXPAND VIEWSを使用して同じクエリの推定計画をもう一度確認することで最も簡単に確認できます。 指定:
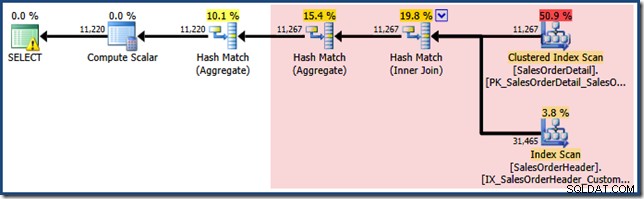
赤い影付きの領域は、ビューマッチングアクティビティによって置き換えられるツリーの部分を表します。この領域からの出力カーディナリティは11,267です。 11,220の推定値を持つ影のない部分は、ビューマッチングの影響を受けません。これらはまさに私たちが説明しようとしていた見積もりです:
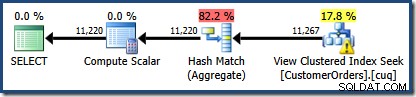
ビューマッチングは、インデックス付きビューの赤い影付きの領域を論理的に同等のシークに置き換えただけです。ビューからの統計情報を使用して、カーディナリティの推定値を再計算しませんでした。
ある程度、このように機能する理由を理解できるでしょう。一般に、ある統計情報のセットから計算された推定値が別のセットよりも優れていると期待する理由はほとんどありません。赤い網掛け部分の結合後の派生統計と比較して、ここではインデックス付きビューの統計が正確である可能性が高い場合がありますが、それを一般化すること、またはさまざまなソースのさまざまなソースを正確に説明することは難しい場合があります。基礎となるデータが変更されると、統計情報が古くなる可能性があります。
また、インデックス付きビュー情報の方が優れていると確信している場合は、NOEXPANDを使用したと主張することもできます。 ヒント。
さらに興味深いカーディナリティの推定値
基本テーブルに対してクエリを記述し、自動ビューマッチングに依存する場合、EnterpriseEditionでさらに興味深い状況が発生します。
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID;
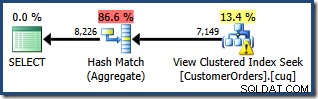
統計の欠落に関する警告は以前と同じであり、同じ説明があります。さらに興味深い機能は、View Clustered Index Seekによって生成される行数の推定値が低くなり(7,149)、集計から返される行数の推定値が高くなることです(8,226)。
この点を強調するために、このクエリプランは、7,149のソース行を集約して8,226の行を生成できるという考えに基づいているようです!
説明の一部は以前と同じです。 EXPAND VIEWS ビューマッチングに置き換えられる赤い領域を示すクエリプランを以下に示します。
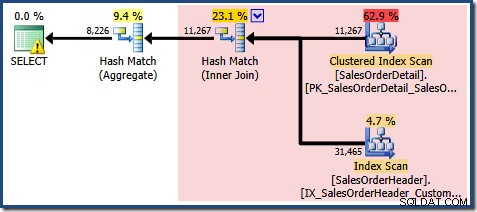
これは、8,226の最終的な見積もりがどこから来るかを説明していますが、7,149行の見積もりはどうですか?前に見たロジックに従うと、ビューには11,267行の見積もりが表示されるはずですか?
答えは、7,149の見積もりは推測であるということです。はい、そうです。インデックス付きビューには、合計79,433行が含まれています。述語間の製品IDの魔法の推測パーセンテージは9%であり、0.09 * 79433=7148.97行になります。 SSMSクエリプランは、丸め前であっても、この計算が正確に正しいことを示しています。
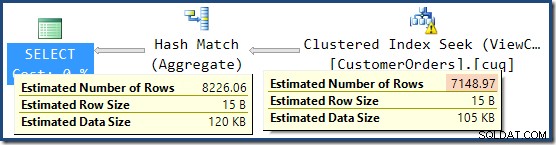
この状況では、SQL Serverオプティマイザーは、置き換えられたサブツリーからの結合後のカーディナリティ推定よりも、インデックス付きビューのカーディナリティに基づく推測を優先したようです。好奇心が強い。
概要
NOEXPANDを使用する ヒントは、インデックス付きビューが最終的なクエリプランで使用されることを保証し、非インデックス統計をクエリオプティマイザによって自動的に作成、維持、および使用できるようにします。 NOEXPANDを使用する また、最初のカーディナリティの推定値が、ベーステーブルから導出されるのではなく、インデックス付きのビュー情報に基づいていることを確認します。
NOEXPANDの場合 が指定されていない場合、ビュー参照は、クエリのコンパイルが開始される前(したがって、最初のカーディナリティ推定の前)に常にベーステーブル定義に置き換えられます。エンタープライズSKUの場合のみ、最適化プロセスの後半で、インデックス付きビューをクエリツリーに戻すことができます。
EXPAND VIEWS クエリヒントは、オプティマイザがEnterpriseEditionのインデックス付きビューマッチングを実行できないようにします。これは、クエリが最初にインデックス付きビューを参照していたかどうかに関係なく適用されます。ビューマッチングが実行されると、状況によっては、既存のカーディナリティ推定値が推測値に置き換えられる場合があります。
インデックス付きビューで欠落していると表示される統計は手動で作成できますが、オプティマイザーは通常、NOEXPANDを使用しないクエリには統計を使用しません。 ヒント。
インデックス付きビューを使用すると、特にビューに結合または集計が含まれている場合に、カーディナリティの見積もりを改善できます。 NOEXPANDの場合、クエリはより正確なビュー統計から利益を得る可能性が最も高くなります。 が指定されています。