SQL Server 2014 SP2以降では、経過時間を含めることができるランタイム(「実際の」)実行プランが作成されます。 およびCPU使用率 実行プランのオペレーターごとに(KB3170113およびPedro Lopesによるこのブログ投稿を参照)
これらの数値の解釈は、必ずしも予想されるほど簡単ではありません。 行モードには重要な違いがあります およびバッチモード 実行、および行モードのトリッキーな問題並列処理 。 SQLServerはタイミングを調整します 一貫性を促進するための並行計画がありますが、それらは完全には実装されていません。これにより、パフォーマンス調整の結論を導き出すことが困難になる可能性があります。
この記事は、それぞれの場合にタイミングがどこから来るのか、そしてそれらが文脈の中でどのように最もよく解釈されるのかを理解するのを助けることを目的としています。
次の例では、公開されている Stack Overflow 2013を使用しています データベース(ダウンロードの詳細)、単一のインデックスが追加されています:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
テストクエリは、月と年でグループ化された、受け入れられた回答を含む質問の数を返します。これらはSQLServer 2019 CU9で実行されます 、8コアのラップトップで、SQLServer2019インスタンスに16GBのメモリが割り当てられています。互換性レベル150 排他的に使用されます。
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); 実行計画は(クリックして拡大):
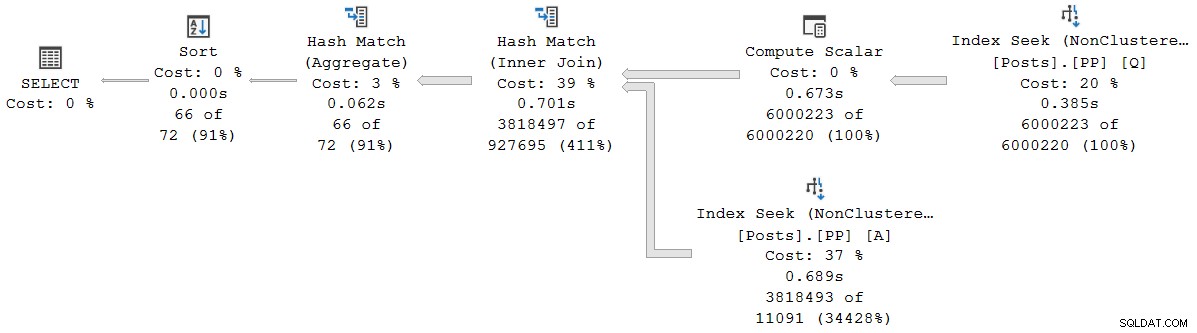
このプランのすべてのオペレーターは、行ストアのバッチモードのおかげで、バッチモードで実行されます。 SQL Server 2019のインテリジェントクエリ処理機能(列ストアインデックスは必要ありません)。クエリは2,523ms実行されます 必要なすべてのデータがすでにバッファプールにある場合、2,522msのCPU時間が使用されます。
以前にリンクされたブログ投稿でPedroLopesが指摘しているように、個々のバッチモードについて報告された経過時間とCPU時間 演算子は、その演算子のみが使用する時間を表します 。
SSMSは経過時間を表示します グラフィカルな表現で。 CPU時間を確認するには 、プランオペレーターを選択し、プロパティを確認します 窓。この詳細ビューには、オペレーターごと、およびスレッドごとの経過時間とCPU時間の両方が表示されます。
ショープランの時間(XML表現を含む)は切り捨てられます ミリ秒まで。より高い精度が必要な場合は、query_thread_profileを使用してください マイクロ秒で報告する拡張イベント 。上記の実行プランのこのイベントからの出力は次のとおりです。
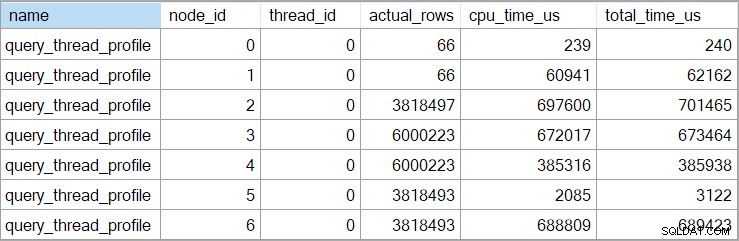
これは、結合(ノード2)の経過時間が701,465µs(showplanでは701msに切り捨てられている)であることを示しています。アグリゲートの経過時間は62,162µs(62ms)です。 「質問」インデックスシークは385ミリ秒実行されていると表示されますが、拡張イベントはノード4の実際の数値が385,938µs(ほぼ386ミリ秒)であることを示しています。
SQLServerは高精度を使用します QueryPerformanceCounter タイミングデータをキャプチャするためのAPI。これは、プロセッサ速度、電力設定、またはその性質に関係なく、非常に高い一定レートでティックを生成するハードウェア(通常は水晶発振器)を使用します。睡眠中でも時計は同じ速度で動き続けます。より細かい詳細に興味がある場合は、リンクされた非常に詳細な記事を参照してください。簡単に言うと、マイクロ秒の数値が正確であると信頼できるということです。
この純粋なバッチモードプランでは、合計実行時間は個々のオペレーターの経過時間の合計に非常に近くなります。違いは主に、計画オペレーターに関連付けられていないステートメント後の作業(それまでにすべて閉鎖された)にありますが、ミリ秒の切り捨ても役割を果たします。
純粋なバッチモードプランでは、現在のオペレーターと子のオペレーターの時間を手動で合計して、累積を取得する必要があります。 任意のノードでの経過時間。
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); 実行計画は次のとおりです。
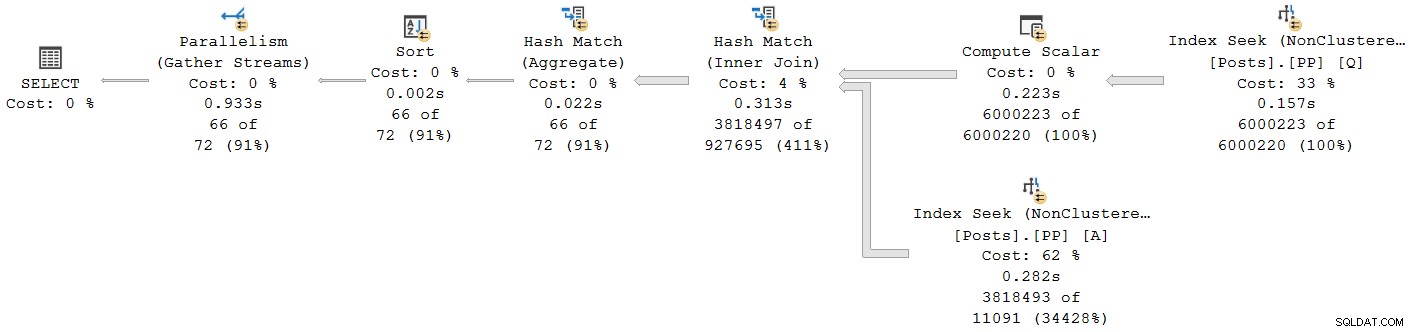
ファイナルギャザーストリーム交換を除くすべてのオペレーターは、バッチモードで実行されます。合計経過時間は933ms ウォームキャッシュを使用した場合のCPU時間は6,673ミリ秒です。
ハッシュ結合を選択し、SSMSプロパティを確認します ウィンドウには、そのオペレーターのスレッドごとの経過時間とCPU時間が表示されます。
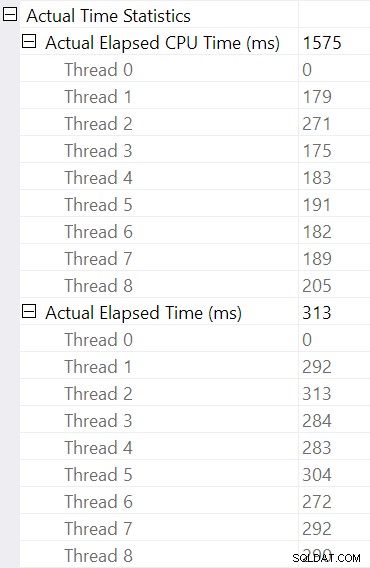
CPU時間 オペレーターに報告されるのは合計です 個々のスレッドのCPU時間。報告されたオペレーター経過時間 最大です スレッドごとの経過時間の。両方の計算は、スレッドごとの切り捨てられたミリ秒値に対して実行されます。以前と同様に、合計実行時間は、個々のオペレーターの経過時間の合計に非常に近くなります。
バッチモードの並列プランでは、スレッド間で作業を分散するために交換を使用しません。バッチ演算子は、複数のスレッドが単一の共有構造で効率的に機能できるように実装されています。 (例:ハッシュテーブル)。バッチモードの並列プランでは、スレッド間の同期が引き続き必要ですが、同期ポイントやその他の詳細はshowplanの出力には表示されません。
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); 実行プランは視覚的にはバッチモードのシリアルプランと同じですが、すべてのオペレーターが行モードで実行されています:
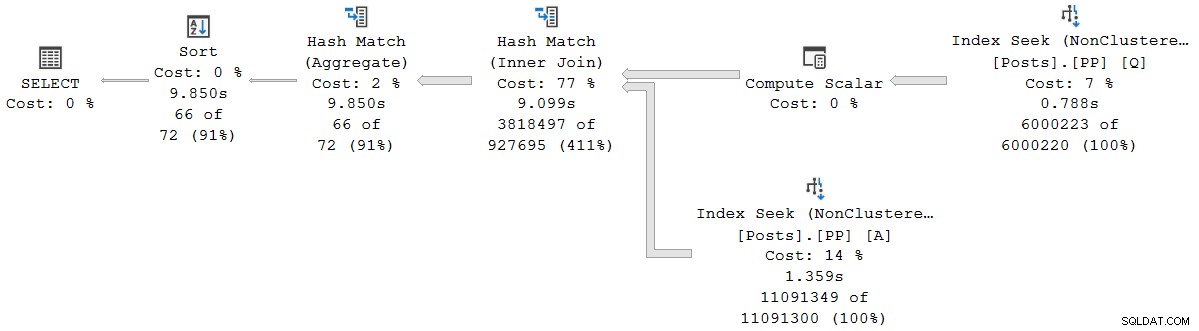
クエリは9,850ms実行されます 9,845msのCPU時間。これは、予想どおり、シリアルバッチモードクエリ(2523ms / 2522ms)よりもはるかに低速です。現在の議論でさらに重要なのは、行モード オペレーターの経過時間とCPU時間は、現在のオペレーターとそのすべての子が使用した時間を表します 。
拡張イベントには、各ノードでの累積CPU時間と経過時間(マイクロ秒単位)も表示されます。
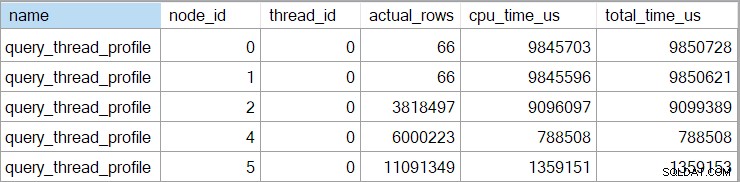
行モードの実行は延期できるため、計算スカラー演算子(ノード3)のデータはありません。 結果を消費する演算子に対するほとんどの式の計算。これは現在、バッチモード実行には実装されていません。
報告された累積 行モード演算子の経過時間とは、最終的な並べ替え演算子に表示される時間が、クエリの合計実行時間とほぼ一致することを意味します(とにかくミリ秒の解像度まで)。同様に、ハッシュ結合の経過時間には、その下にある2つのインデックスシークからの寄与と、それ自体の時間が含まれます。 経過時間を計算するには 行モードのハッシュ結合だけの場合は、両方のシーク時間を差し引く必要があります。
両方のプレゼンテーションには長所と短所があります(行モードの場合は累積、バッチモードの場合は個々のオペレーターのみ)。どちらを好む場合でも、違いに注意することが重要です。
一般に、最新の実行計画には、行モードとバッチモードの演算子が混在している場合があります。バッチモードのオペレーターは、自分自身のためだけに時間を報告します。行モードの演算子には、すべてを含む、その時点までの累積合計が計画に含まれます。 子演算子。明確にするために:行モード演算子の累積時間含む 任意のバッチモードの子演算子。
これは以前、並列バッチモードプランで見ました。最後の(行モード)ストリームの収集オペレーターには、すべての子バッチモードオペレーターを含めて、表示された(累積)経過時間が0.933秒でした。他のオペレーターはすべてバッチモードであったため、個々のオペレーターのみの時間を報告しました。
この状況では、一部のプランオペレーターが同じプラン内 累積時間がある場合とない場合は、間違いなく紛らわしいと見なされます。 多くの人によって。
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); 実行計画は次のとおりです。

すべての演算子は行モードです。クエリは4,677ms実行されます 23,311msのCPU時間(すべてのスレッドの合計)。
排他的な行モードプランとして、常に累積的であることが期待されます 。子供から親へ(右から左へ)移動すると、その方向に時間が増えるはずです。
計画の右端のセクションを見てみましょう:
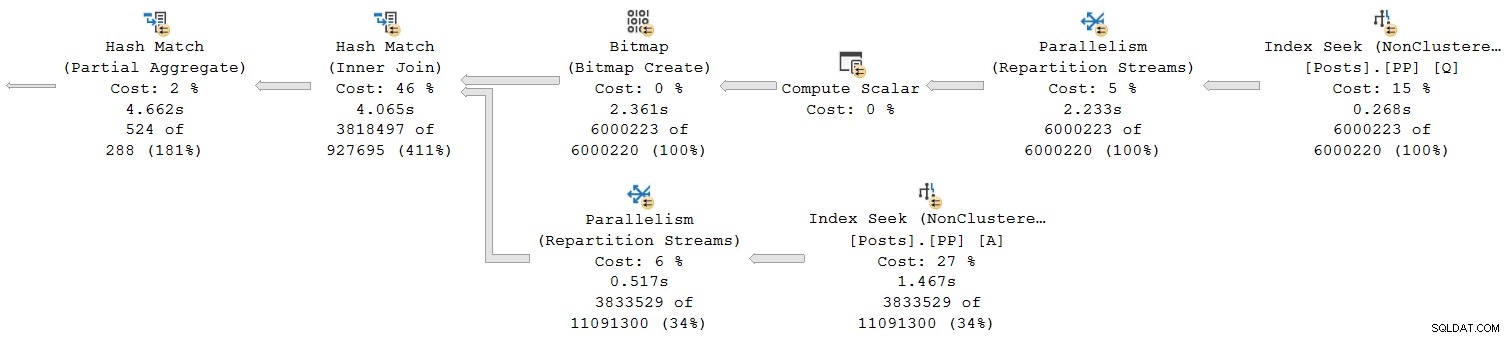
一番上の行を右から左に見ていくと、累積時間は確かに当てはまるようです。ただし、例外があります ハッシュ結合への下位入力の場合:インデックスシークの経過時間は1.467秒です。 、親 再パーティションストリームの経過時間は0.517秒のみです。 。
親はどうすればよいですか オペレーターは短時間実行します その子より 行モードプランで経過時間が累積する場合
このパズルの答えにはいくつかの部分があります。非常に複雑なので、少しずつ見ていきましょう。
まず、交換(並列処理演算子)には2つの部分があることを思い出してください。左手(消費者 )側は、左側の並列ブランチでオペレーターを実行しているスレッドの1つのセットに接続されています。右手(プロデューサー )交換の側は、右側の並列ブランチでオペレーターを実行している別のスレッドのセットに接続されています。
プロデューサー側の行はパケットに組み立てられます その後、消費者側に転送されます。これにより、ある程度のバッファリングが提供されます およびフロー制御 接続されたスレッドの2つのセットの間。 (エクスチェンジと並列プランのブランチについて復習する必要がある場合は、私の記事「並列実行プラン-ブランチとスレッド」を参照してください。)
プロデューサーの並列ブランチを見る 交換の側:
いつものように、DOP(並列度)の追加のワーカースレッドは、独立したシリアルを実行します このブランチのプランオペレーターのコピー。したがって、DOP 8では、8つの独立したシリアルインデックスシークが連携して、全体的な(並列)インデックスシーク操作の範囲スキャン部分を実行します。各シングルスレッドシークは、シングル共有のプロデューサー側の異なる入力(ポート)に接続されます 交換演算子。
消費者にも同様の状況が存在します 交換の側。 DOP 8では、このブランチの8つの個別のシングルスレッドコピーがすべて独立して実行されています。
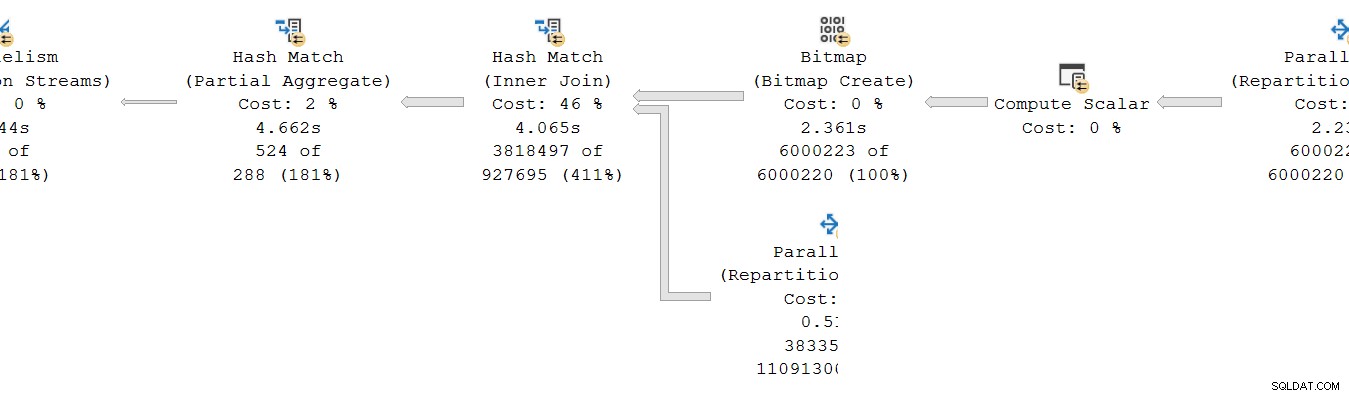
これらのシングルスレッドサブプランはそれぞれ通常の方法で実行され、各オペレーターは各ノードで経過時間とCPU時間の合計を累積します。行モードのオペレーターであるため、各合計は、現在のノードとその各子の累積合計に費やされた時間を表します。
重要な点は、累積合計 同じスレッドの演算子のみを含める 現在のブランチ内でのみ 。各スレッドは他の場所で何が起こっているのかわからないため、これが直感的に理解できることを願っています。
パズルの2番目の部分は、行モードプランで行数とタイミングメトリックを収集する方法に関連しています。実行時(「実際の」)プラン情報が必要な場合、実行エンジンは非表示を追加します すぐ左へのプロファイリングオペレーター (親)実行時に実行されるプラン内のすべてのオペレーターの。
このオペレーターは、(とりわけ)子オペレーターに制御を渡した時間と制御が戻された時間との差を記録する場合があります。この時間差は、監視対象のオペレーターとそのすべての子の経過時間を表します。 、子が行ごとに自分の子を呼び出すためなど。演算子は何度も呼び出される可能性があるため(初期化、次に行ごとに1回、最後に閉じる)、プロファイリング演算子によって収集される時間は累積です。 潜在的に多くの行ごとの反復にわたって。
プロファイリングデータの詳細については さまざまなキャプチャ方法を使用して収集されます。クエリプロファイリングインフラストラクチャをカバーする製品ドキュメントを参照してください。そのようなことに興味がある人のために、標準インフラストラクチャで使用される非表示のプロファイリング演算子の名前はsqlmin!CQScanProfileNewです。 。すべての行モードイテレータと同様に、Openがあります 、GetRow 、およびClose とりわけ、メソッド。各メソッドには、Windows QueryPerformanceCounterへの呼び出しが含まれています。 現在の高解像度タイマー値を収集するためのAPI。
プロファイリングオペレータは左にあるため ターゲットオペレーターの消費者のみを測定します 交換の側。 プロファイリングオペレーターはありません プロデューサーのために 交換の側(悲しいことに)。インデックスシークとプロデューサー側が同じスレッドのセットを実行しており、交換のプロデューサー側がインデックスシークの親オペレーターであるため、存在する場合は、インデックスシークに表示される経過時間と一致するかそれを超えます。

それでも、上記のタイミングで問題が発生する可能性があります。インデックスシークはどのように1.467秒かかることができますか 取引所のプロデューサー側に行を渡しますが、コンシューマー側は0.517秒しかかかりません それらを受け取るために?個別のスレッド、バッファリングなどに関係なく、確かに 交換は、シークよりも(エンドツーエンドで)長く実行する必要がありますか?
はい、そうですが、それは異なる測定値です 経過時間またはCPU時間から。ここで測定しているものについて正確に説明しましょう。
行モードの場合経過時間 、スレッドごとのストップウォッチを想像してみてください 各オペレーターで。ストップウォッチ開始 SQL Serverが親からオペレーターのコードを入力し、停止したとき (ただし、リセットされません)そのコードがオペレーターを離れて、制御を親(子ではなく)に戻す場合。経過時間含む 待機やスケジュールの遅延–どちらも時計を停止しません。
行モードの場合CPU時間 、待機中およびスケジューリング遅延中に停止することを除いて、同じ特性を持つ同じストップウォッチを想像してください。オペレーターまたはその子の1つがスケジューラー(CPU)でアクティブに実行されている場合にのみ時間を累積します。スレッドごと、オペレーターごとのストップウォッチの合計時間は、各行の開始-停止サイクルで構成されます。
これを、取引所の消費者側とインデックスシークの現在の状況に適用してみましょう。
エクスチェンジとインデックスシークのコンシューマー側は別々のブランチにあるため、別々のスレッドで実行されていることを忘れないでください 。コンシューマー側には、同じスレッドに子がありません。インデックスシークには、同じスレッドの親として取引所のプロデューサー側がありますが、ストップウォッチはありません。
各コンシューマスレッドは、その親演算子(ハッシュ結合のプローブ側)が制御を渡すと(たとえば、行をフェッチするために)監視を開始します。コンシューマーが現在の交換パケットから行を取得している間、ウォッチは実行を続けます。時計は停止 コントロールがコンシューマーを離れ、ハッシュ結合プローブ側に戻ったとき。さらに親(部分集約とその親交換)もその行で作業し(待機する場合があります)、制御が交換のコンシューマ側に戻って次の行をフェッチします。その時点で、エクスチェンジのコンシューマー側は経過時間とCPU時間を再び蓄積し始めます。
一方、コンシューマ側のブランチスレッドが実行していることとは関係なく、インデックスシーク スレッドは引き続きインデックス内の行を検索し、それらを取引所に送ります。インデックスシークスレッドは、取引所のプロデューサー側が行を要求するとストップウォッチを開始します。行が取引所に渡されると、ストップウォッチは一時停止します。取引所が次の行を要求すると、インデックスシークストップウォッチが再開します。
取引所のプロデューサー側でCXPACKETが発生する可能性があることに注意してください 交換バッファがいっぱいになるまで待機しますが、それが発生したときにストップウォッチが実行されていないため、インデックスシークで記録された経過時間には追加されません。取引所のプロデューサー側のストップウォッチがある場合、不足している経過時間がそこに表示されます。
状況の概要を視覚的に概算するために、次の図は、各オペレーターが2つの並列ブランチで経過時間を累積するタイミングを示しています。
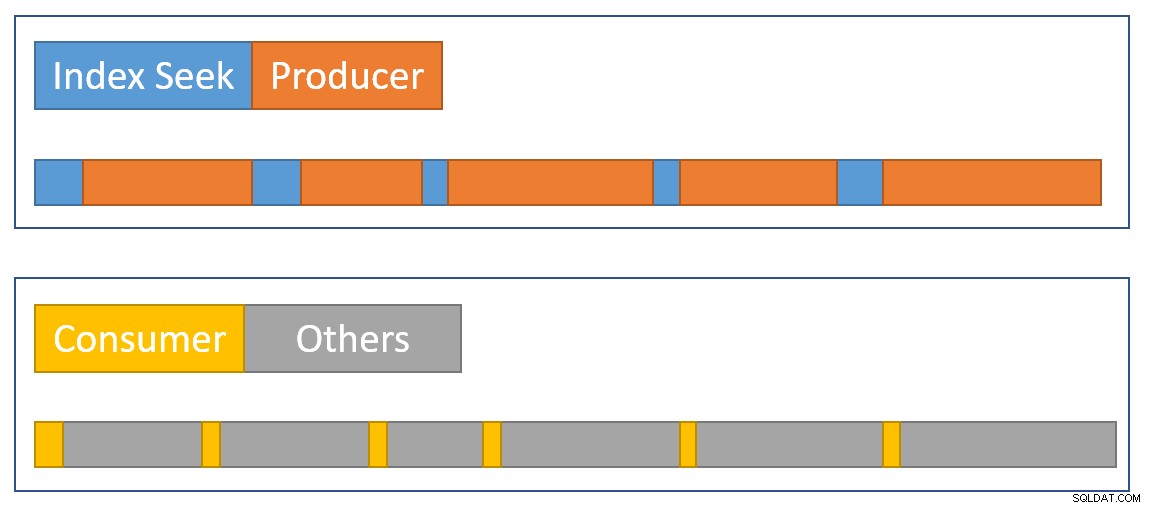
青 インデックスからの行のフェッチが高速であるため、インデックスシークタイムバーは短くなります。 オレンジ CXPACKETのため、プロデューサーの時間が長くなる可能性があります 待ちます。 黄色 データが利用可能になると取引所から行をすばやく取得できるため、消費者の時間は短くなります。 灰色 時間セグメントは、エクスチェンジのコンシューマー側の上にある他のオペレーター(ハッシュ結合プローブ側、部分集約、およびその親エクスチェンジプロデューサー側)によって使用される時間を表します。
交換パケットはすぐに満たされることを期待しています インデックスシークによるが、ゆっくりと空に (比較的言えば)消費者側のオペレーターは、やるべきことがもっとあるので。これは、交換のパケットが通常満杯またはほぼ満杯になることを意味します。コンシューマーは待機行をすばやく取得できますが、プロデューサーはパケットスペースが表示されるまで待機する必要がある場合があります。
取引所のプロデューサー側で経過時間が見えないのは残念です。私は長い間、交換は2つで表されるべきだと考えてきました。 実行計画のさまざまな演算子。 CXPACKETが難しくなります / CXCONSUMER 分析の必要性がはるかに少なくなり、実行計画がはるかに理解しやすくなります。エクスチェンジプロデューサーオペレーターは、当然、独自のプロファイリングオペレーターを取得します。
SQLServerが一貫した累積を達成する方法はたくさんあります。 並列ブランチ全体の経過時間とCPU時間原則として 。オペレーターのプロファイリングの代わりに、各行には、計画の進行中にこれまでに発生した経過時間とCPU時間に関する情報を含めることができます。各行に履歴が関連付けられているため、交換によってスレッド間で行がどのように再配布されるかなどは関係ありません。
それは製品が設計された方法ではないので、それは私たちが持っているものではありません(そしてそれはとにかく非効率的かもしれません)。公平を期すために、元の行モードの設計は、実際の行数の収集や各オペレーターでの反復回数などにのみ関係していました。オペレーターごとの経過時間を計画に追加することは、要望の多かった機能でした。 、しかし、既存のフレームワークに組み込むのは簡単ではありませんでした。
バッチモード処理が製品に追加されたとき、何も壊すことなく、元の開発の一部として別のアプローチ(現在のオペレーターのみのタイミング)を実装できました。繰り返しますが、原則として 、行モード演算子は、バッチモード演算子と同じように機能するように変更できますが、既存のすべての行モード演算子を再設計するために多大な作業が必要になります。既存の行モードプロファイリング演算子に新しいデータポイントを追加する方がはるかに簡単でした。限られたエンジニアリングリソースと、必要な製品の改善点の長いリストを考えると、このような妥協が必要になることがよくあります。
2番目の問題
もう1つの累積的なタイミングの不一致は、左側の現在の計画で発生します:

一見すると、これは同じ問題のように見えます。部分集計の経過時間は4.662秒です。 、ただし、上記の交換は2.844秒でのみ実行されます 。もちろん、以前と同じ基本的な仕組みが機能していますが、もう1つの重要な要素があります。 1つの手がかりは、ストリームの集約、並べ替え、および再パーティション化の交換について報告された、疑わしいほど等しい時間にあります。
冒頭で述べた「タイミング調整」を覚えていますか?ここでそれらが登場します。再パーティションストリーム交換のコンシューマー側のスレッドの個々の経過時間を見てみましょう:
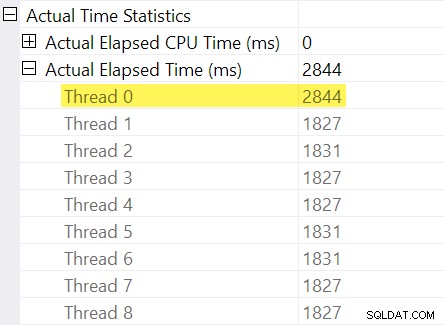
計画では、並列オペレーターの経過時間が最大として示されていることを思い出してください。 スレッドごとの時間の。 8つのスレッドすべての経過時間は約1,830ミリ秒でしたが、2,844ミリ秒の「スレッド0」の追加エントリがあります。確かにすべてのオペレーター この並列ブランチ(エクスチェンジコンシューマー、ソート、およびストリームアグリゲート)では、同じ 「スレッド0」からの2,844msの貢献。
スレッドゼロ(別名親タスクまたはコーディネーター)は、最終的なストリームの収集演算子の左側にある演算子のみを直接実行します。ここで、並列ブランチに割り当てられた作業があるのはなぜですか?
この問題は、下の並列ブランチにブロッキング演算子がある場合に発生する可能性があります (右側)現在のもの。この調整がないと、現在のブランチのオペレーターは経過時間を過少報告します。 子ブランチを開くのに必要な時間によって(複雑 このためのアーキテクチャ上の理由)。
SQL Serverは、非表示のプロファイリングオペレーターで、交換時の子ブランチの遅延を記録することにより、これを考慮します。時間の値は、親タスクに対して記録されます (「スレッド0」)最初のアクティブの違い および最後にアクティブ 回数。 (この方法で番号を記録するのは奇妙に思えるかもしれませんが、番号を記録する必要がある時点では、追加の並列ワーカースレッドはまだ作成されていません。)
現在の場合、2,844msの調整 主に、ハッシュ結合がハッシュテーブルを構築するのにかかる時間のために発生します。 (今回は合計とは異なることに注意してください ハッシュ結合の実行時間。これには、結合のプローブ側の処理にかかる時間が含まれます。
ハッシュ結合がビルド入力をブロックしているため、調整が必要になります。 (興味深いことに、ハッシュ部分的な集計 プラン内のメモリは最小限のメモリしか割り当てられておらず、 tempdb に流出することはないため、このコンテキストではブロッキングとは見なされません。 、メモリが不足すると集約を停止します(これによりストリーミングモードに戻ります)。 Craig Freedmanは、彼の投稿「PartialAggregation」でこれを説明しています。
経過時間の調整が子ブランチの初期化遅延を表すことを考えると、SQLServerはすべき 「スレッド0」の値をオフセットとして扱う 現在のブランチ内で測定されたスレッドごとの経過時間の数値。 最大を取る スレッドは同時に開始する傾向があるため、経過時間は一般に妥当です。 しない スレッド値の1つが他のすべての値のオフセットである場合は、これを行うのが理にかなっています!
正しいオフセット計算を実行できます プランで利用可能なデータを手動で使用します。取引所の消費者側には次のものがあります:
追加のワーカースレッド間の最大経過時間は1,831msです。 (「スレッド0」に格納されているオフセット値を除く)。 オフセットを追加する 2,844msの場合、合計 4,675ms 。
スレッドごとの時間が少ないプランの場合 オフセットよりも、オペレーターは誤って オフセットを合計経過時間として表示します。これは、前のブロッキング演算子が遅く(おそらく、大量のデータセットに対するソートまたはグローバル集計)、後のブランチ演算子の時間が少ない場合に発生する可能性があります。
計画のこの部分を再検討する:
再パーティションストリーム、並べ替え、およびストリーム集計演算子に誤って割り当てられた2,844msのオフセットを、計算された 4,675msに置き換えます。 値は、累積経過時間を部分集計の4,662msと 4,676msの間にきちんと配置します。 ファイナルギャザーストリームで。 (並べ替えと集計は少数の行で機能するため、経過時間の計算は並べ替えと同じになりますが、一般的には異なることがよくあります):

上記のプランフラグメント内のすべてのオペレーターは、すべてのスレッドで0ミリ秒のCPU経過時間を持っています(部分的な集計は14,891ミリ秒です)。したがって、計算された数値を使用した計画は、表示された計画よりもはるかに理にかなっています。
- 4,675ms – 4,662ms = 13ms 経過時間は、再パーティションストリームのみで消費される時間のはるかに妥当な数値です 。この演算子はCPU時間を消費せず、524行のみを処理します。
- 0ミリ秒 経過(ミリ秒の解像度まで)は、小さなソートとストリームの集約(ここでも、子を除く)にとって妥当です。
- 4,676ms – 4,675ms = 1ms 最終的な収集ストリームが66行を親タスクスレッドに収集してクライアントに返すのに適しているようです。
部分集約(4,662ms)と再パーティションストリーム(2,844ms)の間の特定の計画の明らかな不一致は別として、66行の最終収集ストリームが4,676ms – 2,844ms=の原因であると考えるのは不合理です。 1,832ms 経過時間の。修正された数値(1ms)ははるかに正確であり、クエリチューナーを誤解させることはありません。
現在、このオフセット計算が正しく実行されたとしても、並列行モードの計画はそうではない可能性があります。 前述の理由により、すべての場合で一貫した累積時間を示します。完全な一貫性を実現することは難しい場合があり、アーキテクチャを大幅に変更しないと不可能な場合もあります。
この時点で発生する可能性のある質問を予測するには:いいえ、以前の交換およびインデックスシーク分析には「スレッド0」オフセット計算エラーは含まれていませんでした。その交換の下にはブロッキング演算子がないため、初期化の遅延は発生しません。
この次のクエリ例では、前と同じデータベースとインデックスを使用します。興味のある読者のために、私がすでに作成したポイントを拡張するためだけに役立つので、あまり詳しくは説明しません。
このデモの機能は次のとおりです。
-
ORDER GROUPなし ヒントは、部分集約がブロッキング演算子と見なされないことを示しているため、再パーティションストリーム交換で「スレッド0」の調整は発生しません。経過時間は一定です。 - ヒントを使用すると、ハッシュ部分集計の代わりにブロッキングソートが導入されます。 2つの異なる 「スレッド0」の調整は、2つの再パーティション交換で表示されます。経過時間は、さまざまな方法で両方のブランチで一貫していません。
クエリ:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
ORDER GROUPのない実行プラン (調整なし、一貫した時間):

ORDER GROUPを使用した実行プラン (2つの異なる調整、一貫性のない時間):

行モードプランのオペレーターは、累積を報告します 同じスレッド内のすべての子演算子を含む時間。 Batch mode operators record the time used inside that operator alone 。
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side 。 The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER )。 This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit 。 This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.