
その月の火曜日です。T-SQL火曜日として知られるブロガーブロックパーティーが開催される火曜日です。今月はRussThomas(@SQLJudo)が主催し、トピックは「すべてのチューナーとギアヘッドの呼び出し」です。ここでは、パフォーマンス関連の問題を扱いますが、ラスが招待状に示したガイドラインに完全には一致していない可能性があることをお詫びします(ヒント、トレースフラグ、またはプランガイドは使用しません)。 。
先週のSQLBitsで、トリガーについてプレゼンテーションを行いました。親友であり、MVPの仲間であるErlandSommarskogがたまたま出席しました。ある時点で、テーブルに新しいトリガーを作成する前に、トリガーがすでに存在するかどうかを確認し、トリガーを追加するのではなく、ロジックを組み合わせることを検討することをお勧めしました。私の理由は、主にコードの保守性だけでなく、パフォーマンスにもありました。アーランドは、同じアクションに対して複数のトリガーを起動することで追加のオーバーヘッドがあるかどうかを確認するためにテストしたことがあるかどうかを尋ねました。だから私は今それをするつもりです。
AdventureWorks2014では、基本的にsys.all_objectsを表す単純なテーブルのセットを作成しました。 (〜2,700行)およびsys.all_columns (〜9,500行)。両方のテーブルを更新するためのさまざまなアプローチのワークロードへの影響を測定したかったのです。基本的に、ユーザーが列テーブルを更新し、トリガーを使用して同じテーブルの別の列とオブジェクトテーブルのいくつかの列を更新します。
- T1:ベースライン :ストアドプロシージャを介してすべてのデータアクセスを制御できると想定します。この場合、トリガーを必要とせずに、両方のテーブルに対する更新を直接実行できます。 (テーブルへの直接アクセスを確実に禁止することはできないため、これは現実の世界では実用的ではありません。)
- T2:他のテーブルに対する単一のトリガー :影響を受けるテーブルに対してupdateステートメントを制御し、他の列を追加できると想定しますが、セカンダリテーブルへの更新はトリガーを使用して実装する必要があります。 3つの列すべてを1つのステートメントで更新します。
- T3:両方のテーブルに対する単一のトリガー :この場合、2つのステートメントを持つトリガーがあります。1つは影響を受けるテーブルのもう1つの列を更新し、もう1つはセカンダリテーブルの3つの列すべてを更新します。
- T4:両方のテーブルに対する単一のトリガー :T3と同様ですが、今回は4つのステートメントを持つトリガーがあります。1つは影響を受けるテーブルの他の列を更新し、各列のステートメントは2次テーブルで更新されます。これは、要件が時間の経過とともに追加され、回帰テストの観点から別のステートメントがより安全であると見なされる場合の処理方法である可能性があります。
- T5:2つのトリガー :1つのトリガーは、影響を受けるテーブルのみを更新します。もう1つは、単一のステートメントを使用して、2次テーブルの3つの列を更新します。これは、他のトリガーが気付かれない場合、またはそれらを変更することが禁止されている場合に行われる方法である可能性があります。
- T6:4つのトリガー :1つのトリガーは、影響を受けるテーブルのみを更新します。他の3つは、セカンダリテーブルの各列を更新します。繰り返しになりますが、他のトリガーが存在することがわからない場合、または回帰の懸念のために他のトリガーに触れることを恐れている場合は、これが行われる方法である可能性があります。
扱っているソースデータは次のとおりです。
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
ここで、6つのテストのそれぞれについて、更新を1,000回実行し、時間の長さを測定します。
T1:ベースライン
これは、幸運にもトリガーを回避できるシナリオです(これもあまり現実的ではありません)。この場合、このバッチの読み取りと期間を測定します。 /*real*/を入れました 最終的にメトリックがトリガーを呼び出すステートメントにロールアップされるため、トリガー内のステートメントではなく、これらのステートメントのみの統計を簡単に取得できるように、クエリテキストに追加します。また、私が行っている実際の更新は実際には意味がないことに注意してください。したがって、照合をサーバー/インスタンス名とオブジェクトのprincipal_idに設定していることを無視してください。 現在のセッションのsession_idに 。
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:シングルトリガー
このためには、dbo.srcのみを更新する次の単純なトリガーが必要です。 :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO 次に、バッチはプライマリテーブルの2つの列を更新するだけで済みます:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:両方のテーブルに対する単一のトリガー
このテストでは、トリガーは次のようになります。
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO そして今、私たちがテストしているバッチは、プライマリテーブルの元の列を更新するだけです。もう1つはトリガーによって処理されます:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:両方のテーブルに対する単一のトリガー
これはT3と同じですが、トリガーには4つのステートメントがあります。
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO テストバッチは変更されていません:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:2つのトリガー
ここでは、プライマリテーブルを更新するための1つのトリガーと、セカンダリテーブルを更新するための1つのトリガーがあります。
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO テストバッチも非常に基本的です:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:4つのトリガー
今回は、影響を受ける列ごとにトリガーがあります。 1つはプライマリテーブルに、3つはセカンダリテーブルにあります。
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO そしてテストバッチ:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
ワークロードへの影響の測定
最後に、sys.dm_exec_query_statsに対して簡単なクエリを作成しました。 各テストの読み取りと期間を測定するには:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
結果
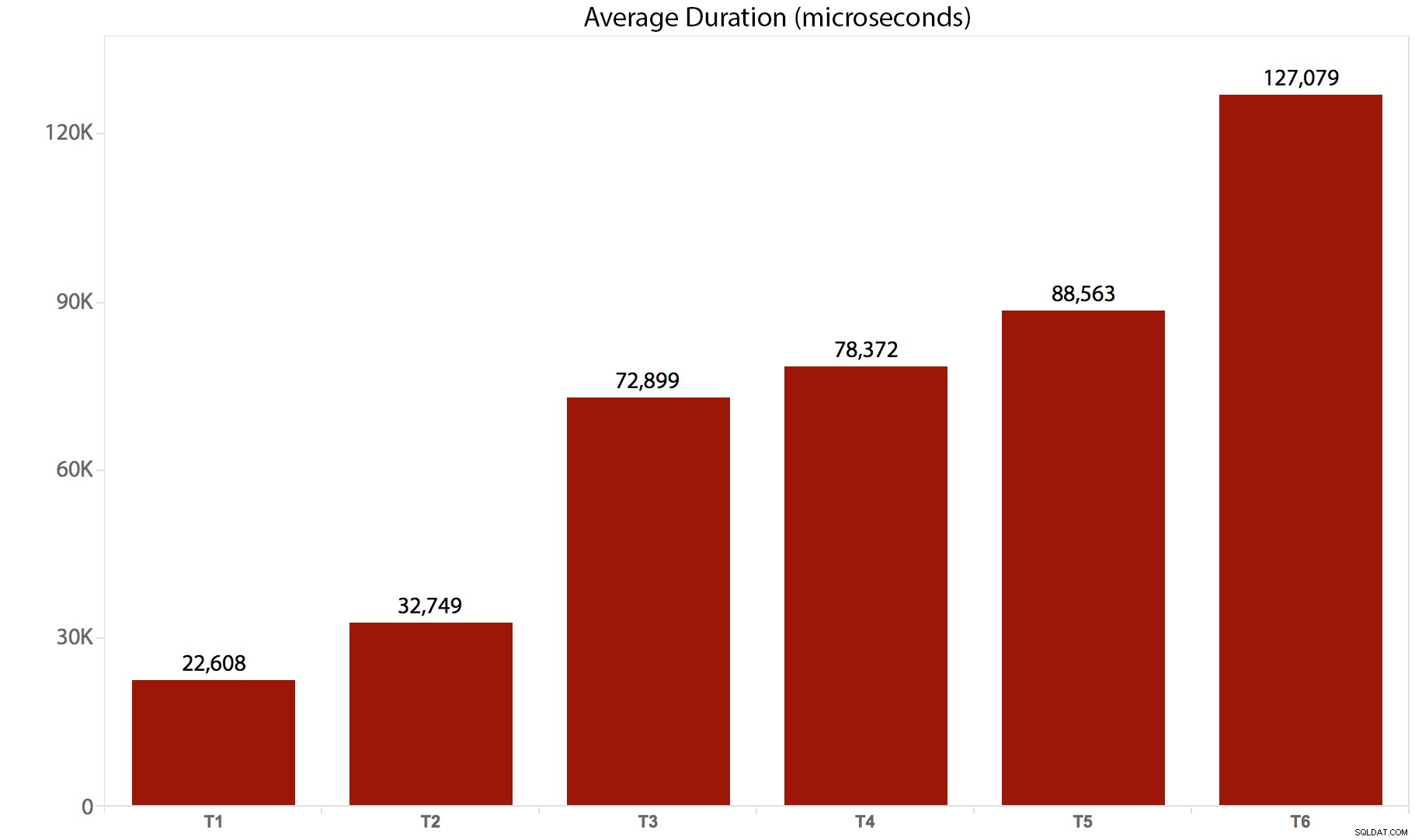
テストを10回実行し、結果を収集して、すべてを平均しました。内訳は次のとおりです。
| テスト/バッチ | 平均継続時間 (マイクロ秒) | 合計読み取り数 (8Kページ) |
|---|---|---|
| T1 :UPDATE / * real */dbo.tr1… | 22,608 | 205,134 |
| T2 :UPDATE / * real */dbo.tr2… | 32,749 | 11,331,628 |
| T3 :UPDATE / * real */dbo.tr3… | 72,899 | 22,838,308 |
| T4 :UPDATE / * real */dbo.tr4… | 78,372 | 44,463,275 |
| T5 :UPDATE / * real */dbo.tr5… | 88,563 | 41,514,778 |
| T6 :UPDATE / * real */dbo.tr6… | 127,079 | 100,330,753 |
そして、これが期間のグラフ表示です:
結論
この場合、呼び出されるトリガーごとにかなりのオーバーヘッドがあることは明らかです。これらのバッチはすべて、最終的に同じ数の行に影響を与えましたが、同じ行が複数回タッチされた場合もあります。同じ行が2回以上タッチされない場合の違いを測定するために、おそらくさらに後続のテストを実行します。より複雑なスキーマでは、おそらく、毎回5つまたは10の他のテーブルにタッチする必要があり、これらの異なるステートメントは次のようになります。単一のトリガーまたは複数のトリガーで。私の推測では、オーバーヘッドの違いは、トリガー自体のオーバーヘッドよりも、同時実行性や影響を受ける行数などによって大きく左右されると思いますが、これから見ていきます。
自分でデモを試してみませんか?ここからスクリプトをダウンロードしてください。