SQL Server 2017 Enterprise Editionで最初に導入された、適応型結合 実行時に、バッチモードのハッシュ結合から行モードの相関ネストされたループのインデックス付き結合(適用)への実行時の移行を有効にします。簡潔にするために、「相関ネストされたループのインデックス付き結合」を適用と呼びます。 この記事の残りの部分を通して。ネストされたループと適用の違いについて復習する必要がある場合は、以前の記事をご覧ください。
アダプティブ結合がハッシュ結合から実行時に適用するように移行するかどうかは、アダプティブしきい値行というラベルの付いた値によって異なります。 アダプティブジョイン 実行プラン演算子。この記事では、アダプティブジョインがどのように機能するかを示し、しきい値計算の詳細を含め、いくつかの設計上の選択の影響について説明します。
はじめに
この記事全体で覚えておいてほしいことの1つは、適応型結合です。常に バッチモードのハッシュ結合として実行を開始します。これは、実行プランが、アダプティブ結合が行モードの適用として実行されることを期待していることを示している場合でも当てはまります。
他のハッシュ結合と同様に、アダプティブ結合はビルド入力で使用可能なすべての行を読み取り、必要なデータをハッシュテーブルにコピーします。ハッシュ結合のバッチモードフレーバーは、これらの行を最適化された形式で格納し、1つ以上のハッシュ関数を使用してそれらを分割します。ビルド入力が消費されると、ハッシュテーブルが完全に入力されてパーティション化され、ハッシュ結合でプローブ側の行の一致のチェックを開始できるようになります。
これは、アダプティブ結合がバッチモードのハッシュ結合を続行するか、行モードの適用に移行するかを決定するポイントです。ハッシュテーブルの行数がしきい値より少ない場合 値の場合、結合は適用に切り替わります。それ以外の場合、結合は、プローブ入力から行の読み取りを開始することにより、ハッシュ結合として続行されます。
適用結合への移行が発生した場合、実行プランは、適用操作を実行するためにハッシュテーブルにデータを入力するために使用された行を再読み込みしません。代わりに、アダプティブバッファリーダーと呼ばれる内部コンポーネント ハッシュテーブルにすでに格納されている行を展開し、適用演算子の外部入力でオンデマンドで使用できるようにします。アダプティブバッファリーダーに関連するコストがありますが、ビルド入力を完全に巻き戻すコストよりもはるかに低くなります。
アダプティブジョインの選択
クエリの最適化には、代替案の論理的な調査と物理的な実装の1つ以上の段階が含まれます。各段階で、オプティマイザーが論理の物理的なオプションを検討するとき 結合の場合、バッチモードのハッシュ結合と行モードの両方が代替を適用することを検討する可能性があります。
これらの物理的な結合オプションの1つが、現在の段階で見つかった最も安価なソリューションの一部を形成している場合-および 他のタイプの結合は、同じ必要な論理プロパティを提供できます。オプティマイザは、論理結合グループを潜在的にとしてマークします。 アダプティブ結合に適しています。そうでない場合、アダプティブ結合の検討はここで終了します(アダプティブ結合拡張イベントは発生しません)。
オプティマイザの通常の動作は、見つかった最も安価なソリューションには、物理的な結合オプションの1つ(ハッシュまたは適用のいずれか、推定コストが最も低い方)のみが含まれることを意味します。オプティマイザーが次に行うことは、なかったタイプの結合の新しい実装を構築してコストをかけることです。 最も安いものとして選ばれました。
現在の最適化フェーズは、最も安価なソリューションが見つかってすでに終了しているため、適応型結合のために特別な単一グループの調査と実装のラウンドが実行されます。最後に、オプティマイザは適応しきい値を計算します 。
上記の作業のいずれかが失敗した場合、拡張イベントadaptive_join_skippedが理由で発生します。
アダプティブ結合処理が成功した場合、連結 演算子はハッシュの上の内部プランに追加され、アダプティブバッファーリーダーと必要なバッチ/行モードアダプターを使用して代替を適用します。適応しきい値と比較して実際に検出された行数に応じて、実行時に実行される結合の選択肢は1つだけであることを忘れないでください。
Concat 演算子と個々のハッシュ/適用の選択肢は、通常、最終的な実行プランには表示されません。代わりに、単一のアダプティブジョインが表示されます オペレーター。これは単なるプレゼンテーションの決定であり、 Concat 結合は、SQLServer実行エンジンによって実行されるコードに引き続き存在します。これについての詳細は、この記事の付録と関連資料のセクションにあります。
適応しきい値
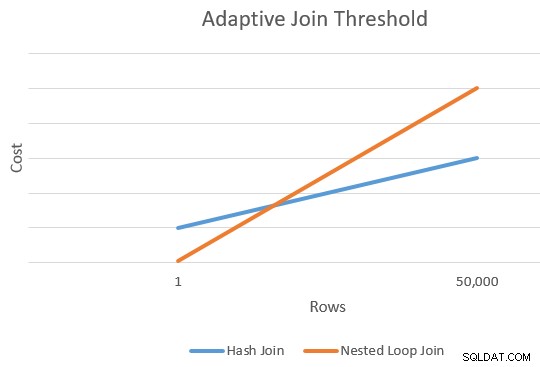
一般に、適用は、駆動行の数が少ない場合のハッシュ結合よりも安価です。ハッシュ結合には、ハッシュテーブルを構築するための追加の起動コストがありますが、一致のプローブを開始するときの行ごとのコストは低くなります。
一般に、適用とハッシュ結合の推定コストが等しくなるポイントがあります。このアイデアは、JoeSackの記事「バッチモードの適応型結合の紹介」でうまく説明されています。
しきい値の計算
この時点で、オプティマイザーは、ハッシュ結合のビルド入力に入る行数の単一の見積もりを持ち、代替を適用します。また、ハッシュおよび適用演算子全体の推定コストも含まれています。
これにより、上の図のオレンジと青の線の右端に1つのポイントが表示されます。オプティマイザは、「線を描画」して交差点を見つけることができるように、結合タイプごとに別の参照ポイントを必要とします(文字通り線を描画しませんが、アイデアは得られます)。
線の2番目のポイントを見つけるために、オプティマイザーは2つの結合に、異なる(および仮想の)入力カーディナリティに基づいて新しいコスト見積もりを生成するように要求します。最初のカーディナリティ推定が100行を超える場合、1行の新しいコストを推定するように結合に要求します。元のカーディナリティーが100行以下の場合、2番目のポイントは10,000行の入力カーディナリティーに基づいています(したがって、外挿するのに十分な範囲があります)。
いずれの場合も、結果は結合タイプごとに2つの異なるコストと行数になり、線を「描画」できるようになります。
交差点の公式
各線の2点に基づいて2本の線の交点を見つけることは、いくつかのよく知られた解決策の問題です。 SQL Serverは、行列式に基づくものを使用します ウィキペディアで説明されているように:
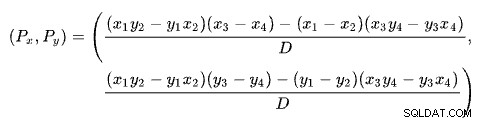
ここで:
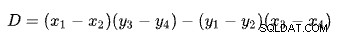
最初の線は点(x 1 )によって定義されます 、y 1 )および(x 2 、y 2 )。 2行目は点(x 3 、y 3 )および(x 4 、y 4 )。交差点は(P x 、P y 。
このスキームでは、x軸に行数、y軸に推定コストがあります。線が交差する行の数に関心があります。これは、P xの式で与えられます。 。交差点での推定費用を知りたい場合は、P yになります。 。
P xの場合 行の場合、適用ソリューションとハッシュ結合ソリューションの推定コストは等しくなります。これが必要な適応しきい値です。
実例
これは、AdventureWorks2017サンプルデータベースと、バッチモードの実行を無条件に検討するためのItzikBen-Ganによる次のインデックス作成トリックを使用した例です。
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
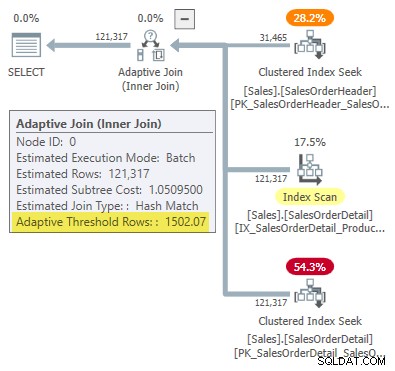
WHERE SOH.SalesOrderID <= 75123; 実行プランには、適応型結合が示されています。 しきい値は1502.07 行:
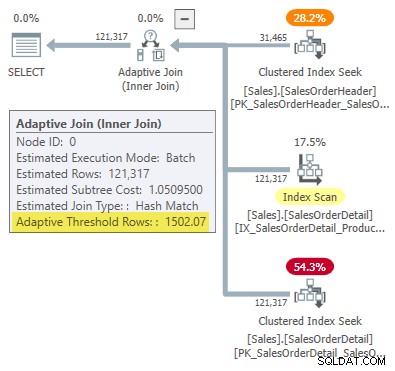
アダプティブ結合を駆動する行の推定数は、 31,465 。
参加費用
この単純化されたケースでは、ハッシュの推定サブツリーコストを見つけ、ヒントを使用して結合の代替案を適用できます。
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
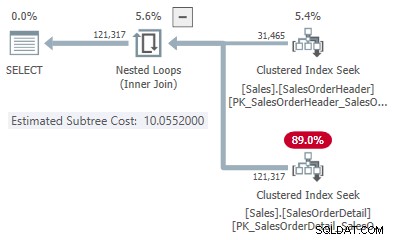
これにより、結合タイプごとに1つのポイントが得られます。
- 31,465行
- ハッシュコスト1.05083
- 適用コスト10.0552
ライン上の2番目のポイント
推定行数は100を超えるため、2番目の参照ポイントは、1つの結合入力行に基づく特別な内部推定から取得されます。残念ながら、この内部計算の正確なコスト数を取得する簡単な方法はありません(これについては後で詳しく説明します)。
今のところ、コストの数値を示します(実行計画に示されている6つの有効数字ではなく、完全な内部精度を使用):
- 1行(内部計算)
- ハッシュコスト0.999027422729
- 適用コスト0.547927305023
- 31,465行
- ハッシュコスト1.05082787359
- 適用コスト10.0552890166
予想どおり、適用結合は、入力カーディナリティーが小さい場合はハッシュよりも安価ですが、31,465行のカーディナリティーが予想される場合ははるかに高価です。
交差点の計算
これらのカーディナリティとコストの数値を線線交叉の式に代入すると、次のようになります。
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 有効数字6桁に四捨五入すると、この結果は 1502.07と一致します。 アダプティブ結合実行プランに表示される行:
欠陥または設計?
SQL Serverは、適応型結合のしきい値を見つけるために、行数とコストの線を「描画」するために4つのポイントが必要であることを忘れないでください。この場合、これは、適用とハッシュ結合の両方の実装について、1行と31,465行のカーディナリティのコスト見積もりを見つけることを意味します。
オプティマイザは、sqllang!CuNewJoinEstimateという名前のルーチンを呼び出します アダプティブ結合のこれら4つのコストを計算します。残念ながら、このアクティビティの簡単な概要を提供するトレースフラグや拡張イベントはありません。オプティマイザの動作と表示コストの調査に使用される通常のトレースフラグは、ここでは機能しません(詳細については、付録を参照してください)。
1行のコスト見積もりを取得する唯一の方法は、デバッガーを接続し、CuNewJoinEstimateへの4回目の呼び出しの後にブレークポイントを設定することです。 sqllang!CardSolveForSwitchのコード内 。 WinDbgを使用して、SQL Server 2019CU12でこの呼び出しスタックを取得しました:

コードのこの時点で、倍精度浮動小数点のコストは、rsp+b0のアドレスが指す4つのメモリ位置に格納されます。 、rsp+d0 、rsp+30 、およびrsp+28 (ここで、rsp はCPUレジスタであり、オフセットは16進数です):

示されている演算子サブツリーのコスト数は、適応型結合しきい値の計算式で使用されているものと一致します。
これらの1行のコスト見積もりについて
1行の結合に関連する作業量に対して、1行の結合の推定サブツリーコストが非常に高いように見えることに気付いたかもしれません。
- 1行
- ハッシュコスト0.999027422729
- 適用コスト0.547927305023
ハッシュ結合の1行の入力実行プランを作成して例を適用しようとすると、多くのが表示されます。 上に示したものよりも、結合時の推定サブツリーコストが低くなります。同様に、1つの行目標(または1つの行の入力に期待される結合出力行の数)で元のクエリを実行すると、推定コストも生成されます 示されているよりも低い。
その理由は、CuNewJoinEstimate ルーチンは、1行を見積もります ほとんどの人は直感的ではないと思います。
最終的なコストは、3つの主要なコンポーネントで構成されています。
- ビルド入力サブツリーのコスト
- 参加の現地費用
- プローブ入力サブツリーのコスト
項目2と3は、結合のタイプによって異なります。ハッシュ結合の場合、プローブ入力からすべての行を読み取り、それらをハッシュテーブルの1つの行と照合する(または照合しない)、結果を次の演算子に渡すコストが考慮されます。適用の場合、コストは、結合へのより低い入力、結合自体の内部コスト、および一致した行を親演算子に返すための1つのシークをカバーします。
これはどれも珍しいことでも驚くべきことでもありません。
コストサプライズ
驚きはビルド側にあります 結合の(リストの項目1)。オプティマイザが、31,465行のすでに計算されたサブツリーコストを1つの平均行などにスケールダウンするために、いくつかの凝った計算を行うことを期待するかもしれません。
実際、ハッシュと1行結合の推定の適用はどちらも、元ののサブツリー全体のコストを使用するだけです。 31,465行のカーディナリティ推定。実行中の例では、この「サブツリー」は 0.54456 ヘッダーテーブルでのバッチモードクラスター化インデックスシークのコスト:
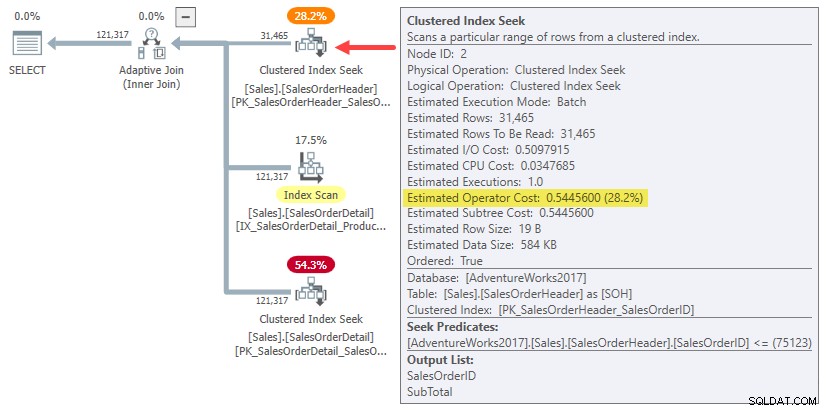
明確にするために:1行結合の代替案のビルド側の推定コストは、31,465行に対して計算された入力コストを使用します。それは少し奇妙に思われるはずです。
念のため、CuNewJoinEstimateによって計算された1行のコスト 次のとおりでした:
- 1行
- ハッシュコスト0.999027422729
- 適用コスト0.547927305023
合計適用コスト(〜0.54793)が 0.54456によって支配されていることがわかります ビルド側のサブツリーのコスト。単一の内側のシークにわずかな追加料金がかかり、結合内で結果として得られる少数の行を処理し、それらを親演算子に渡します。
プランのプローブ側は完全なインデックススキャンで構成されているため、推定される1行のハッシュ結合コストは高くなります。この場合、結果のすべての行が結合を通過する必要があります。 1行のハッシュ結合の総コストは、ハッシュテーブルに1行しかないため、31,465行の例の元の1.05095のコストよりも少し低くなります。
影響
1行の結合の見積もりは、部分的には、駆動結合入力に1行を配信するコストに基づいていると予想されます。これまで見てきたように、これはアダプティブ結合には当てはまりません。適用とハッシュの両方の代替案には、31,465行の推定コストがすべて含まれています。残りの結合には、1行のビルド入力に期待されるのとほぼ同じコストがかかります。
この直感的に奇妙な配置が、計算されたコストを反映した実行計画を示すことが難しい(おそらく不可能である)理由です。上位の結合入力に31,465行を配信する計画を作成する必要がありますが、結合自体とその内部入力に、1行だけが存在するかのようにコストがかかります。難しい質問です。
これらすべての効果は、交線図の左端の点をy軸上に上げることです。これは線の傾きに影響し、したがって交点に影響します。
もう1つの実用的な効果は、計算された適応結合しきい値が、2017年のブログ投稿でJoe Obbishが指摘したように、ハッシュビルド入力での元のカーディナリティ推定に依存するようになったことです。たとえば、WHEREを変更した場合 SOH.SalesOrderID <= 55000へのテストクエリの句 、適応しきい値は減少します クエリプランハッシュを変更せずに1502.07から1259.8に。同じ計画、異なるしきい値。
これは、これまで見てきたように、内部の1行のコスト見積もりがビルド入力コストに依存するために発生します。 元のカーディナリティ推定値。これは、ビルド側の初期推定値が異なると、1行の推定値に異なるy軸の「ブースト」が与えられることを意味します。次に、線の勾配と交点が異なります。
直感的には、同じ結合の1行の推定値は、ライン上の他のカーディナリティの推定値に関係なく、常に同じ値を与える必要があることを示唆します(同じプロパティと行サイズのまったく同じ結合が、駆動間でほぼ線形の関係にある場合)行とコスト)。これは、アダプティブ結合には当てはまりません。
設計による?
SQLServerが何をするかを自信を持って伝えることができます アダプティブ結合しきい値を計算するとき。 理由について特別な洞察はありません このようにします。
それでも、この取り決めが意図的であり、十分な検討とテストからのフィードバックの後に生じたと考える理由がいくつかあります。このセクションの残りの部分では、この側面に関する私の考えの一部を取り上げます。
アダプティブ結合は、通常の適用モードとバッチモードのハッシュ結合の間の直接的な選択ではありません。アダプティブ結合は常に、ハッシュテーブルに完全に入力することから始まります。この作業が完了すると、適用実装に切り替えるかどうかが決定されます。
この時点で、メモリ内のハッシュ結合にデータを入力してパーティション化することにより、潜在的にかなりのコストがすでに発生しています。これは1行の場合はそれほど重要ではないかもしれませんが、カーディナリティが増加するにつれて次第に重要になります。予期しない「ブースト」は、妥当な計算コストを維持しながら、これらの現実を計算に組み込む方法である可能性があります。
SQL Serverのコストモデルは、ネストされたループの結合に対して少し偏っていましたが、おそらくある程度の理由があります。必要なデータがまだメモリになく、I / Oサブシステムがフラッシュされていない場合、特にランダムアクセスパターンの場合、理想的なインデックス付きの適用ケースでさえ、実際には遅くなる可能性があります。たとえば、限られた量のメモリと遅いI / Oは、ローエンドのクラウドベースのデータベースエンジンのユーザーにとって完全に馴染みのないものではありません。
このような環境での実際のテストでは、直感的にコストがかかる適応型結合が速すぎて適用に移行できないことが明らかになった可能性があります。理論は理論的にのみ優れている場合があります。
それでも、現在の状況は理想的ではありません。異常に低いカーディナリティの見積もりに基づいてプランをキャッシュすると、最初の見積もりが大きい場合よりも、適用への切り替えをはるかに嫌がる適応型結合が生成されます。これはさまざまなパラメータ感度の問題ですが、私たちの多くにとってこのタイプの新しい考慮事項になります。
現在、それも可能です 交差するコストラインの左端のポイントに完全なビルド入力サブツリーコストを使用することは、単に未修正のエラーまたは見落としです。私の考えでは、現在の実装はおそらく意図的な実用的な妥協案ですが、確実に知るには、設計ドキュメントとソースコードにアクセスできる人が必要です。
概要
アダプティブ結合を使用すると、ハッシュテーブルが完全に入力された後、SQLServerをバッチモードのハッシュ結合から適用に移行できます。この決定は、ハッシュテーブルの行数を事前に計算された適応しきい値と比較することによって行われます。
しきい値は、適用コストとハッシュ結合コストが等しい場所を予測することによって計算されます。この点を見つけるために、SQL Serverは、異なるビルド入力カーディナリティ(通常は1行)の2番目の内部結合コスト見積もりを生成します。
驚いたことに、1行の見積もりの見積もりコストには、元のカーディナリティ見積もりのビルド側のサブツリーの全コストが含まれています(1行にスケーリングされていません)。これは、しきい値がビルド入力での元のカーディナリティ推定に依存することを意味します。
その結果、アダプティブ結合のしきい値が予想外に低くなる可能性があります。つまり、アダプティブ結合がハッシュ結合から移行する可能性ははるかに低くなります。この動作が仕様によるものかどうかは不明です。
関連資料
- JoeSackによるバッチモードのアダプティブ結合の紹介
- 製品ドキュメントのアダプティブ結合について
- DimaPiluginによるAdaptiveJoinInternals
- バッチモードのアダプティブ結合はどのように機能しますか? ErikDarlingによるデータベース管理者のStackExchangeについて
- JoeObbishによる適応型結合回帰
- アダプティブ結合が必要な場合は、より広いインデックスが必要であり、大きいほど良いですか?エリック・ダーリン著
- パラメータスニッフィング:BrentOzarによるアダプティブジョイン
- Joe Sackによるインテリジェントなクエリ処理のQ&A
付録
このセクションでは、自然な方法で本文に含めることが困難であったいくつかの適応結合の側面について説明します。
拡張された適応計画
上記のリンクされた優れたアダプティブ結合内部記事でDimaPiluginによって提供された、文書化されていないトレースフラグ9415を使用して、内部計画の視覚的表現を見てみることができます。このフラグがアクティブな場合、実行例の適応型結合プランは次のようになります。
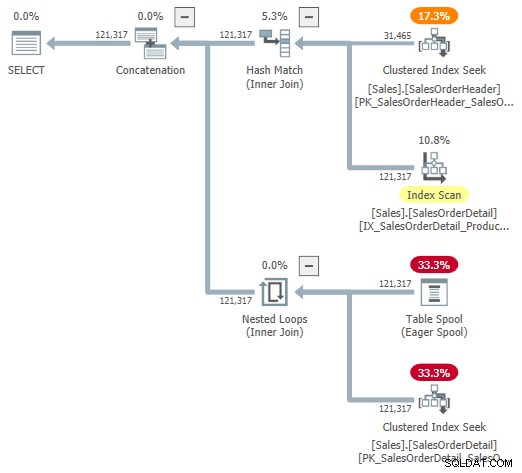
これは理解を助けるのに役立つ表現ですが、完全に正確、完全、または一貫しているわけではありません。たとえば、テーブルスプールは存在しません。これは、アダプティブバッファリーダーのデフォルトの表現です。 バッチモードのハッシュテーブルから直接行を読み取ります。
オペレーターのプロパティとカーディナリティの見積もりも、いたるところにあります。アダプティブバッファリーダー(「スプール」)からの出力は、121,317行ではなく、31,465行である必要があります。適用のサブツリーコストは、親オペレーターのコストによって誤って制限されています。これはshowplanの場合は正常ですが、アダプティブ結合のコンテキストでは意味がありません。
他にも矛盾があります—多すぎて便利にリストできません—しかし、それは文書化されていないトレースフラグで発生する可能性があります。上記の拡張プランはエンドユーザーによる使用を目的としていないため、まったく驚くことではないかもしれません。ここでのメッセージは、この文書化されていないフォームに表示されている数値とプロパティに過度に依存しないことです。
また、完成した標準の適応型結合プランオペレーターは、それ自体の一貫性の問題が完全にないわけではありません。これらは、ほとんどすべて隠された詳細に由来します。
たとえば、表示されるアダプティブ結合プロパティは、基になる Concatの混合物から取得されます。 、ハッシュ結合 、および適用 演算子。ネストされたループの結合のバッチモード実行を報告するアダプティブ結合を確認できます(これは不可能です)。表示されている経過時間は、実際には非表示の Concatからコピーされています。 、実行時に実行された特定の結合ではありません。
いつもの容疑者
できます オプティマイザの出力を調べるために通常使用される、文書化されていない種類のトレースフラグからいくつかの有用な情報を取得します。例:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); 出力(読みやすくするために大幅に編集):
***出力ツリー:***PhyOp_ExecutionModeAdapter(BatchToRow)Card =121317 Cost =1.05095
- PhyOp_Concat(バッチ)カード=121317コスト=1.05325
- PhyOp_HashJoinx_jtInner(バッチ)カード=121317コスト=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card =31465 Cost =0.54456
- PhyOp_Filter(batch)カード=121317コスト=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card =121317 Cost =0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch)カード=121317コスト=10.0798
- PhyOp_Apply Card =121317 Cost =10.5053
- PhyOp_ExecutionModeAdapter(BatchToRow)Card =31465 Cost =0.544623
- PhyOp_Range Sales.SalesOrderHeader Card =31465 Cost =0.54456 [** 3 **]
- PhyOp_Filterカード=3.85562コスト=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card =3.85562 Cost =8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow)Card =31465 Cost =0.544623
- PhyOp_Apply Card =121317 Cost =10.5053
これにより、個別のクエリを記述したりヒントを使用したりせずに、ハッシュを使用したフルカーディナリティの場合の推定コストと代替案を適用するための洞察が得られます。本文で述べたように、これらのトレースフラグはCuNewJoinEstimate内では有効ではありません。 、したがって、31,465行のケースの繰り返し計算や、この方法での1行の見積もりの詳細を直接確認することはできません。
マージ結合と行モードのハッシュ結合
アダプティブ結合は、バッチモードのハッシュ結合から行モードの適用への移行のみを提供します。行モードのハッシュ結合がサポートされていない理由については、「関連資料」セクションの「インテリジェントクエリ処理に関するQ&A」を参照してください。つまり、行モードのハッシュ結合はパフォーマンスの低下を招きやすいと考えられています。
行モードのマージ結合に切り替えることも別のオプションですが、オプティマイザーは現在これを考慮していません。私が理解しているように、将来この方向に拡大する可能性は低いです。
考慮事項のいくつかは、行モードのハッシュ結合の場合と同じです。さらに、マージ結合プランは、インデックス付きマージ結合(明示的な並べ替えなし)に制限されている場合でも、ハッシュ結合との互換性が低くなる傾向があります。
また、ハッシュとマージの間よりも、ハッシュと適用の間の方がはるかに大きな違いがあります。ハッシュとマージはどちらも大きな入力に適しており、applyは小さな駆動入力に適しています。マージ結合は、ハッシュ結合ほど簡単には並列化できず、スレッド数の増加に伴って拡張することもできません。
アダプティブ結合の動機を考えると、大幅に対処することです。 さまざまな入力サイズ(およびハッシュ結合のみがバッチモード処理をサポートします)では、バッチハッシュと行適用のどちらを選択するかがより自然です。最後に、3つの適応結合の選択肢があると、ゲインがほとんどない可能性があるため、しきい値の計算が大幅に複雑になります。