すべての製品にはバグがあり、SQLServerも例外ではありません。製品の機能を少し変わった方法で使用する(または比較的新しい機能を組み合わせる)ことは、それらを見つけるための優れた方法です。バグは面白く、教育的でさえありますが、発見の結果、ポケットベルが午前4時にオフになると、おそらく友人との特に社交的な夜を過ごした後、喜びの一部が失われる可能性があります…
この投稿の主題であるバグは、おそらく実際にはかなりまれですが、古典的なエッジケースではありません。私は、実動システムでこれに遭遇したコンサルタントを少なくとも1人知っています。まったく関係のないテーマについては、この機会にGrumpy Old DBA(ブログ)に「こんにちは」と言ってください。
マージ結合に関するいくつかの関連する背景から始めます。マージ結合について知っておくべきことをすべてすでに知っている場合、または単に追いかけたい場合は、「バグ」というタイトルのセクションまでスクロールしてください。
マージ参加
マージ結合はそれほど複雑なことではなく、適切な状況では非常に効率的です。その入力は結合キーでソートされ、1対多モードで最高のパフォーマンスを発揮する必要があります(少なくともその入力の少なくともは結合キーで一意です)。中程度のサイズの1対多結合の場合、明示的な並べ替えを実行せずに入力の並べ替え要件を満たすことができれば、シリアルマージ結合はまったく悪い選択ではありません。
並べ替えを回避するには、インデックスによって提供される順序を利用するのが最も一般的です。マージ結合は、以前の避けられないソートから保持されたソート順を利用することもできます。マージ結合の優れた点は、いずれかの入力の行がなくなるとすぐに入力行の処理を停止できることです。最後にもう1つ、マージ結合は、入力の並べ替え順序が昇順であるか降順であるかを気にしません(ただし、両方の入力は同じである必要があります)。次の例では、標準の数値テーブルを使用して、上記のほとんどのポイントを示しています。
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
これらの2つのテーブルの主キーを適用するインデックスは降順として定義されていることに注意してください。 INSERTのクエリプラン いくつかの興味深い機能があります:
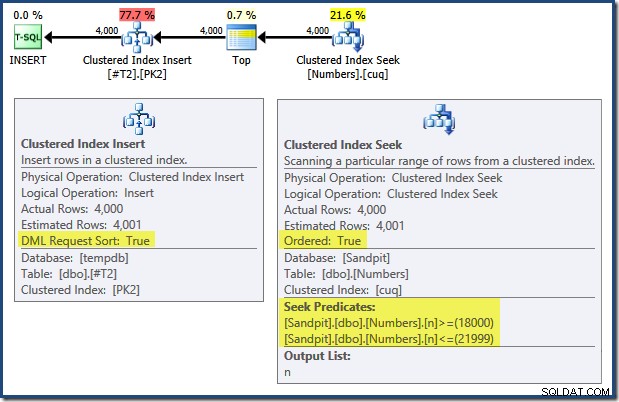
左から右に読み取る(賢明な場合のみです!)クラスター化インデックス挿入には、「DML要求ソート」プロパティが設定されています。これは、オペレーターがクラスター化インデックスのキー順の行を必要とすることを意味します。クラスタ化インデックス(この場合は主キーを適用)は、DESCとして定義されます。 、したがって、より高い値の行が最初に到着する必要があります。 Numbersテーブルのクラスター化されたインデックスはASCです したがって、クエリオプティマイザは、最初にNumbersテーブル(21,999)で最も高い一致を探し、次にインデックスの逆順で最も低い一致(18,000)に向かってスキャンすることにより、明示的な並べ替えを回避します。 SQL Sentry PlanExplorerの[PlanTree]ビューには、逆(逆方向)スキャンが明確に表示されます。
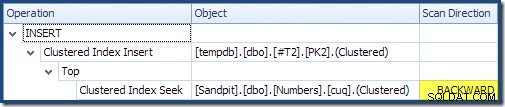
逆方向スキャンは、インデックスの自然な順序を逆にします。 ASCの後方スキャン インデックスキーは、キーの降順で行を返します。 DESCの後方スキャン インデックスキーは、キーの昇順で行を返します。 「スキャン方向」は、返されたキーの順序自体を示すものではありません。インデックスがASCであるかどうかを知る必要があります。 またはDESC その決定を下すために。
これらのテストテーブルとデータの使用(T1 10,000から19,999までの番号が付けられた10,000行があります。 T2 18,000から21,999までの番号が付けられた4,000行があります)次のクエリは、2つのテーブルを結合し、両方のキーの降順で結果を返します。
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; クエリは、期待どおりに一致する2,000行を返します。実行後の計画は次のとおりです。
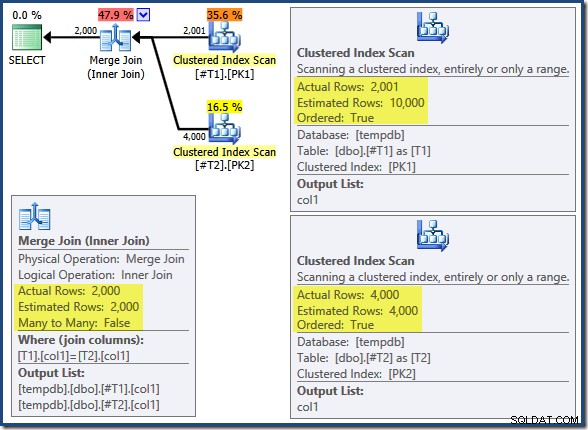
マージ結合は多対多モードで実行されておらず(上部の入力は結合キーで一意です)、2,000行のカーディナリティの見積もりは正確に正しいです。テーブルT2のクラスター化インデックススキャン は順序付けられており(ただし、その順序が順方向であるか逆方向であるかを確認するために少し待つ必要があります)、4,000行のカーディナリティ推定も正確に正しいです。テーブルT1のクラスター化インデックススキャン も順序付けられていますが、読み取られたのは2,001行のみで、10,000行が推定されました。プランツリービューには、両方のクラスター化インデックススキャンが順方向に並べられていることが示されています:
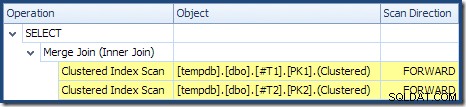
DESCを読んだことを思い出してください インデックスFORWARD キーの逆順で行を生成します。これは、ORDER BY T1.col DESC, T2.col1 DESCに必要なものです。 句なので、明示的な並べ替えは必要ありません。 1対多のマージ結合の擬似コード(CraigFreedmanのマージ結合ブログから複製)は次のとおりです。

T1の降順スキャン 19,999から始まり、10,000に向かって下がる行を返します。 T2の降順スキャン 21,999から始まり、18,000に向かって下がる行を返します。 T2の4,000行すべて 最終的に読み取られますが、キー値17,999がT1から読み取られると、反復マージプロセスは停止します。 、T2 行が不足しています。したがって、マージ処理はT1を完全に読み取らずに完了します。 。 19,999から17,999までの行を読み取ります。上記の実行プランに示されているように、合計2,001行。
ASCを使用してテストを再実行してください。 代わりにインデックスを作成し、ORDER BYも変更します DESCの句 ASCへ 。作成される実行計画は非常に類似しており、並べ替えは必要ありません。
すぐに重要になるポイントを要約すると、Merge Joinには結合キーでソートされた入力が必要ですが、キーが昇順でソートされているか降順でソートされているかは関係ありません。
バグ
バグを再現するには、少なくとも1つのテーブルをパーティション化する必要があります。結果を管理しやすくするために、この例では少数の行のみを使用するため、パーティショニング関数にも小さな境界が必要です。
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
最初のテーブルには2つの列があり、主キーで分割されています:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
2番目のテーブルはパーティション化されていません。主キーと、最初のテーブルに結合する列が含まれています:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); サンプルデータ
最初のテーブルには14行あり、すべてSomeIDの値は同じです。 桁。 SQLServerはIDENTITYを割り当てます 1から14までの番号が付けられた列の値。
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
2番目のテーブルにはIDENTITYが入力されています 表1の値:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
2つのテーブルのデータは次のようになります:
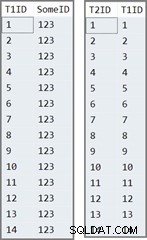
テストクエリ
最初のクエリは、単一のWHERE句の述語を適用して、両方のテーブルを単純に結合します(これは、この非常に単純化された例のすべての行に一致します):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; 結果には、予想どおり14行すべてが含まれます:

行数が少ないため、オプティマイザーはこのクエリにネストされたループ結合プランを選択します。
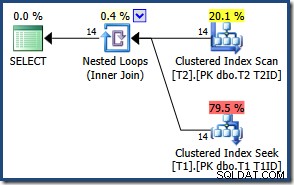
ハッシュまたはマージ結合を強制しても、結果は同じです(そしてまだ正しいです):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
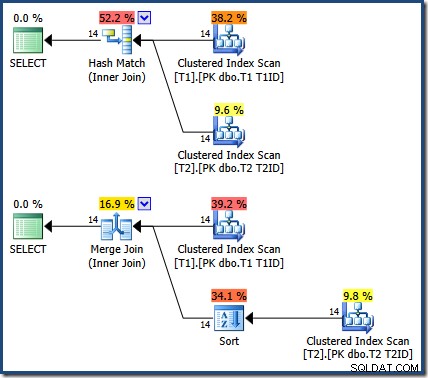
マージ結合は1対多で、T1IDで明示的に並べ替えられます テーブルT2に必要 。
降順インデックスの問題
ある日まではすべて順調です(ここで気にする必要はありません)別の管理者がSomeIDに降順のインデックスを追加します 表1の列:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
オプティマイザがネストされたループまたはハッシュ結合を選択した場合、クエリは引き続き正しい結果を生成しますが、マージ結合が使用された場合は別の話になります。以下でも、クエリヒントを使用してマージ結合を強制していますが、これは例の行数が少ないためです。オプティマイザは当然、異なるテーブルデータを使用して同じマージ結合プランを選択します。
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); 実行計画は次のとおりです。
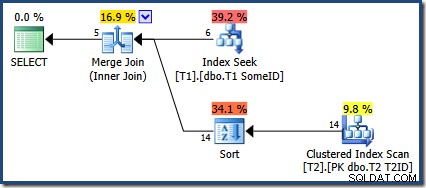
オプティマイザーは新しいインデックスを使用することを選択しましたが、クエリは5行の出力しか生成しません:

他の9行はどうなりましたか?明確にするために、この結果は正しくありません。データは変更されていないため、14行すべてを返す必要があります(ネストされたループまたはハッシュ結合プランを使用しているため)。
原因と説明
SomeIDの新しい非クラスター化インデックス は一意として宣言されていないため、クラスター化インデックスキーはすべての非クラスター化インデックスレベルにサイレントに追加されます。 SQLServerはT1IDを追加します 次のようにインデックスを作成したかのように、非クラスター化インデックスへの列(クラスター化キー):
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
DESCがないことに注意してください サイレントに追加されたT1IDの修飾子 鍵。インデックスキーはASCです デフォルトでは。これ自体は問題ではありません(貢献しますが)。インデックスに自動的に発生する2番目のことは、ベーステーブルと同じ方法でインデックスがパーティション化されることです。したがって、完全なインデックス仕様は、明示的に書き出す場合、次のようになります。
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
これは非常に複雑な構造になり、さまざまな順序のキーがあります。インデックスによって提供されるソート順について推論するときに、クエリオプティマイザがそれを誤解するのは十分に複雑です。説明のために、次の簡単なクエリについて考えてみます。
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
追加の列には、現在の行が属するパーティションが表示されます。それ以外の場合は、T1IDを返す単純なクエリです。 昇順の値、WHERE SomeID = 123 。残念ながら、結果はクエリで指定されたものではありません:
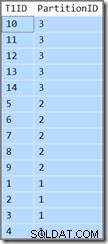
クエリにはT1IDが必要です 値は昇順で返される必要がありますが、それは私たちが得るものではありません。 パーティションごとに昇順で値を取得します 、ただし、パーティション自体は逆の順序で返されます。パーティションが昇順(およびT1ID)で返された場合 示されているように、値は各パーティション内でソートされたままでした)結果は正しいでしょう。
クエリプランは、オプティマイザが先頭のDESCによって混乱していることを示しています インデックスのキーであり、正しい結果を得るには逆の順序でパーティションを読み取る必要があると考えました:
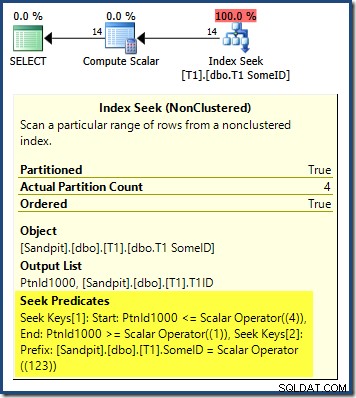
パーティションシークは、右端のパーティション(4)から始まり、パーティション1に戻ります。パーティション番号ASCで明示的に並べ替えることで、問題を修正できると思われるかもしれません。 ORDER BYで 条項:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; このクエリは同じ結果を返します (これは誤植やコピー/貼り付けエラーではありません):
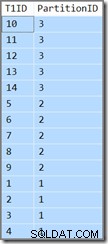
パーティションIDはまだ降順です 順序(指定どおりに昇順ではない)とT1ID 各パーティション内で昇順でのみソートされます。これはオプティマイザの混乱です。パーティション化された先行降順キーインデックスを順方向にスキャンし、パーティションを逆にすると、クエリで指定された順序になると実際に考えています(今すぐ深呼吸してください)。
率直に言って非難することはありません。さまざまな並べ替え順序を考慮すると、頭も痛くなります。
最後の例として、次のことを考慮してください。
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; 結果は次のとおりです。

繰り返しますが、T1ID 並べ替え順序各パーティション内 は正しく降順ですが、パーティション自体は逆方向にリストされています(1から3行下に移動します)。パーティションが逆の順序で返された場合、結果は正しく14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1になります。 。
マージ参加に戻る
マージ結合クエリでの誤った結果の原因が明らかになりました:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
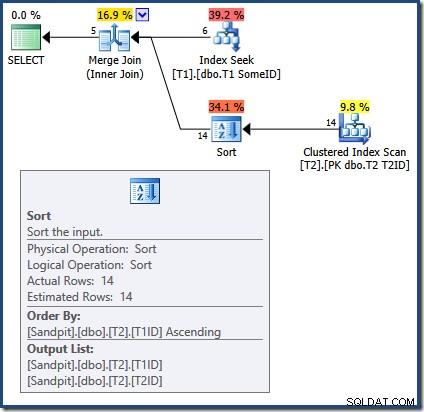
マージ結合には、ソートされた入力が必要です。 T2からの入力 T1TDで明示的に並べ替えられます それで大丈夫です。オプティマイザーは、T1のインデックスを誤って推論します T1IDで行を提供できます 注文。これまで見てきたように、これは当てはまりません。インデックスシークは、すでに見たクエリと同じ出力を生成します:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

T1IDには最初の5行のみが含まれます 注文。次の値(5)は確かに昇順ではなく、Merge Joinはこれをエラーを生成するのではなく、ストリームの終わりとして解釈します(個人的にはここで小売りの主張を期待していました)。とにかく、その効果は、マージ結合が誤って処理を早期に終了することです。注意として、(不完全な)結果は次のとおりです。

結論
これは私の見解では非常に深刻なバグです。単純なインデックスシークは、ORDER BYを尊重しない結果を返す可能性があります 句。さらに重要なことに、オプティマイザーの内部推論は完全に壊れています 降順の先行キーを持つパーティション化された非一意の非クラスター化インデックスの場合。
はい、これは少し 珍しい配置。しかし、これまで見てきたように、誰かが降順のインデックスを追加したという理由だけで、正しい結果が突然誤った結果に置き換えられる可能性があります。追加されたインデックスは十分に無害に見えたことを覚えておいてください。明示的なASC/DESCはありません。 キーの不一致、および明示的なパーティショニングなし。
バグはマージ結合に限定されません。パーティション化されたテーブルを含み、インデックスの並べ替え順序(明示的または暗黙的)に依存するクエリは、犠牲になる可能性があります。このバグは、2008年から2014年までのCTP1を含むSQLServerのすべてのバージョンに存在します。 Windows SQL Azureデータベースはパーティショニングをサポートしていないため、問題は発生しません。 SQL Server 2005は、パーティショニングに異なる実装モデルを使用しました(APPLYに基づく) )そしてこの問題にも悩まされていません。
時間があれば、このバグについて私のConnectアイテムに投票することを検討してください。
解決策
この問題の修正が利用可能になり、ナレッジベースの記事に記載されています。修正にはコードの更新とトレースフラグ4199が必要であることに注意してください 、これにより、他のさまざまなクエリプロセッサの変更が可能になります。誤った結果のバグが4199で修正されるのは珍しいことです。それについて説明を求めたところ、次のように回答されました。
この問題には、クエリプロセッサに関連する他の修正プログラムのような誤った結果が含まれますが、SQL Server 2008、2008 R2、および2012のトレースフラグ4199でのみこの修正を有効にしました。ただし、この修正はSQL Server2014RTMのトレースフラグなしのデフォルト。