SQL Serverデータベースエンジンがインデックス付きビューをベーステーブルと同期させるために使用する一般的な戦略(前回の投稿で詳しく説明しました)は、インクリメンタルメンテナンスを実行することです。 ビューで参照されているテーブルの1つに対してデータ変更操作が発生するたびに、ビューの大まかに言えば、アイデアは次のとおりです。
- ベーステーブルの変更に関する情報を収集する
- ビューで定義された投影、フィルター、および結合を適用します
- インデックス付きビューのクラスター化されたキーごとに変更を集約する
- 各変更により、ビューに対して挿入、更新、または削除を行うかどうかを決定します
- ビューで変更、追加、または削除する値を計算します
- ビューの変更を適用する
または、さらに簡潔に(大幅な簡素化のリスクはありますが):
- 元のデータ変更の増分ビュー効果を計算します。
- これらの変更をビューに適用します
これは通常、基になるデータが変更されるたびにビュー全体を再構築するよりもはるかに効率的な戦略です(安全ですが遅いオプション)が、考えられるすべてのデータ変更に対して、考えられるすべてのインデックス付きビュー定義に対して正しい増分更新ロジックに依存します。
タイトルが示すように、この記事は、増分更新ロジックが機能しなくなり、基になるデータと一致しなくなったインデックス付きビューが破損するという興味深いケースに関係しています。バグ自体に到達する前に、スカラーとベクトルの集計をすばやく確認する必要があります。
スカラーとベクトルの集合体
この用語に慣れていない場合は、2種類の集計があります。 GROUP BY句に関連付けられている集計(group byリストが空の場合でも)は、ベクトル集計と呼ばれます。 。 GROUP BY句のない集合体は、スカラー集合体と呼ばれます。 。
ベクトル集計は、データセットに存在するグループごとに単一の出力行を生成することが保証されていますが、スカラー集計は少し異なります。スカラー骨材常に 入力セットが空の場合でも、単一の出力行を生成します。
ベクトル集計の例
次のAdventureWorksの例では、空の入力セットで2つのベクトル集計(合計とカウント)を計算します。
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
これらのクエリは次の出力を生成します(行なし):

GROUP BY句を空のセットに置き換えた場合(SQL Server 2008以降が必要)、結果は同じです。
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
実行計画はどちらの場合も同じです。これは、カウントクエリの実行プランです:
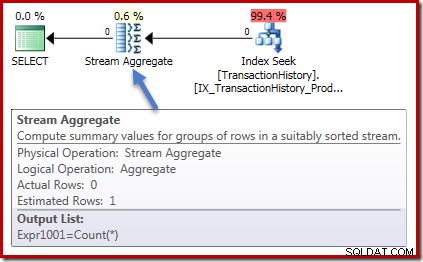
Stream Aggregateに入力された行はゼロで、出力された行はゼロです。合計実行プランは次のようになります:

繰り返しますが、アグリゲートにゼロ行を入れ、ゼロ行を出します。これまでのすべての良いシンプルなもの。
スカラー骨材
次に、クエリからGROUPBY句を完全に削除するとどうなるかを見てみましょう。
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
空の結果の代わりに、COUNT集計はゼロを生成し、SUMはNULLを返します:
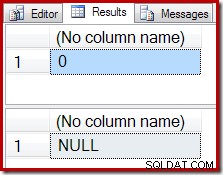
カウント実行プランは、ゼロの入力行がStreamAggregateからの単一行の出力を生成することを確認します。
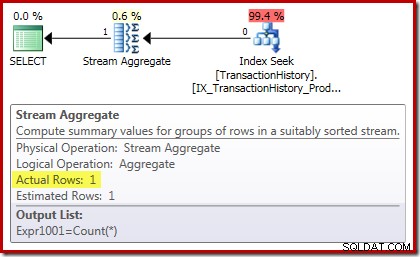
合計実行プランはさらに興味深いものです:
Stream Aggregateプロパティは、要求された合計に加えて、計算されているカウント集計を示します。
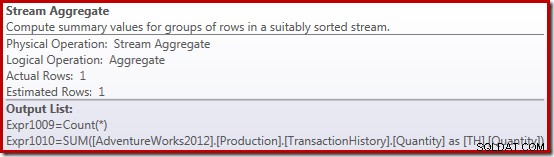
新しいComputeScalar演算子は、Stream Aggregateが受信した行数がゼロの場合はNULLを返すために使用されます。それ以外の場合は、検出されたデータの合計を返します。
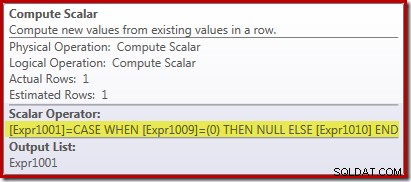
これはすべて少し奇妙に思えるかもしれませんが、これがその仕組みです:
- ゼロ行のベクトル集合はゼロ行を返します。
- Scalarアグリゲートは、入力が空の場合でも、常に1行の出力を生成します。
- ゼロ行のスカラーカウントはゼロです。と
- ゼロ行のスカラー合計はNULLです(ゼロではありません)。
現在の目的で重要な点は、スカラー集計は、何もないところから1行を作成することを意味する場合でも、常に1行の出力を生成することです。また、ゼロ行のスカラー合計はゼロではなくNULLです。
ちなみに、これらの動作はすべて「正しい」ものです。 SQL標準は元々スカラー集計の動作を定義しておらず、実装に任されているため、状況はそのままです。 SQL Serverは、下位互換性の理由から元の実装を保持します。ベクトル集計には、常に明確に定義された動作があります。
インデックス付きビューとベクトル集計
次に、いくつかの(ベクトル)集計を組み込んだ単純なインデックス付きビューについて考えてみます。
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); 次のクエリは、ベーステーブルの内容、インデックス付きビューのクエリ結果、およびビューの基になるテーブルでビュークエリを実行した結果を示しています。
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
結果は次のとおりです。
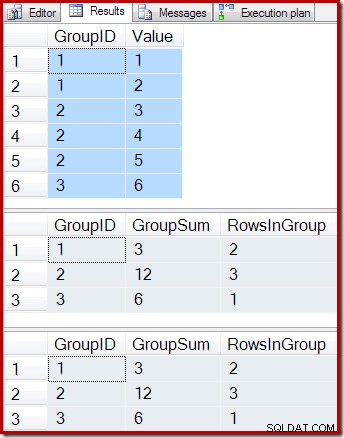
予想どおり、インデックス付きビューと基になるクエリはまったく同じ結果を返します。ベーステーブルT1に可能なすべての変更を加えた後も、結果は同期されたままになります。これがすべてどのように機能するかを思い出させるために、ベーステーブルに1つの新しい行を追加する単純なケースを考えてみましょう。
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); この挿入の実行プランには、インデックス付きビューの同期を維持するために必要なすべてのロジックが含まれています。
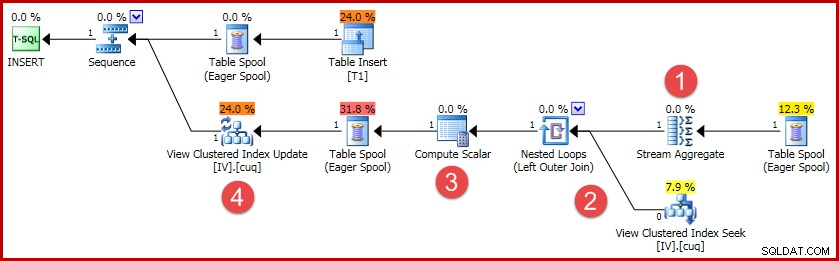
計画の主な活動は次のとおりです。
- Stream Aggregateは、インデックス付きビューキーごとに変更を計算します
- ビューへの外部結合は、変更の概要をターゲットビューの行にリンクします(存在する場合)
- Compute Scalarは、各変更でビューに対して挿入、更新、または削除が必要かどうかを判断し、必要な値を計算します。
- ビュー更新オペレーターは、ビュークラスター化インデックスへの各変更を物理的に実行します。
ベーステーブルに対するさまざまな変更操作(更新や削除など)にはいくつかの計画の違いがありますが、ビューの同期を維持することの背後にある大まかな考え方は同じです。ビューキーごとに変更を集約し、ビュー行が存在する場合はそれを見つけてから、必要に応じて、ビューインデックスに対する挿入、更新、および削除操作の組み合わせ。
この例でベーステーブルにどのような変更を加えても、インデックス付きビューは正しく同期されたままになります。上記のNOEXPANDおよびEXPAND VIEWSクエリは、常に同じ結果セットを返します。これが常に機能する方法です。
インデックス付きビューとスカラー集計
ここで、インデックス付きビューがスカラー集計を使用するこの例を試してください(ビューにGROUP BY句はありません):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); これは完全に合法的なインデックス付きビューです。作成時にエラーは発生しません。ただし、少し奇妙なことをしている可能性があるという手がかりが1つあります。必要な一意のクラスター化インデックスを作成してビューを具体化するとき、キーとして選択する明確な列がありません。もちろん、通常は、ビューのGROUPBY句からグループ化列を選択します。
上記のスクリプトは、NumRows列を任意に選択します。その選択は重要ではありません。選択した方法で、一意のクラスター化インデックスを自由に作成してください。ビューには常に1行だけが含まれます スカラー集計のため、一意キー違反の可能性はありません。その意味で、ビューインデックスキーの選択は冗長ですが、それでも必要です。
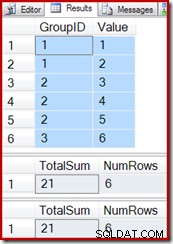
前の例のテストクエリを再利用すると、インデックス付きビューが正しく機能していることがわかります。
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
ベーステーブルへの新しい行の挿入(ベクター集計インデックス付きビューで行ったように)も引き続き正しく機能します:
INSERT dbo.T1
(GroupID, Value)
VALUES
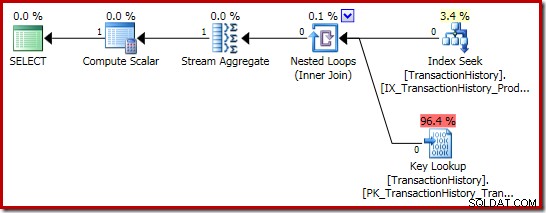
(4, 100); 実行計画は似ていますが、完全に同一ではありません:
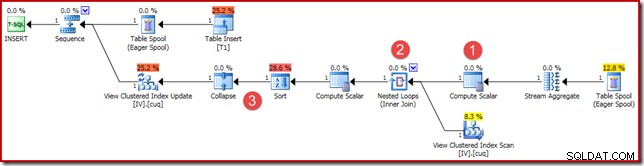
主な違いは次のとおりです。
- この新しいComputeScalarは、以前にベクトルとスカラーの集計結果を比較したときと同じ理由で存在します。集計が空のセットで動作する場合、(ゼロではなく)NULLの合計が返されるようにします。これは、行のないスカラー合計に必要な動作です。
- 以前に表示された外部結合は、内部結合に置き換えられました。インデックス付きビューには常に1つの行が存在するため(スカラー集計のため)、ビューの行が一致するかどうかをテストするために外部結合が必要になることは間違いありません。ビューに表示される1つの行は、常にデータセット全体を表します。この内部結合には述語がないため、技術的には(単一行が保証されたテーブルへの)相互結合です。
- 並べ替え演算子と折りたたみ演算子は、インデックス付きビューのメンテナンスに関する前回の記事で説明した技術的な理由で使用されています。ここでは、インデックス付きビューのメンテナンスの正しい操作には影響しません。
実際、この例では、ベーステーブルT1に対してさまざまなタイプのデータ変更操作を正常に実行できます。効果はインデックス付きビューに正しく反映されます。ベーステーブルに対する次の変更操作はすべて、インデックス付きビューを正しく維持しながら実行できます。
- 既存の行を削除する
- 既存の行を更新する
- 新しい行を挿入
これは包括的なリストのように見えるかもしれませんが、そうではありません。
明らかになったバグ
この問題はかなり微妙であり、(予想どおり)ベクトルとスカラーの集計のさまざまな動作に関連しています。重要な点は、入力で行を受け取らなくても、スカラー集計は常に出力行を生成し、空のセットのスカラー合計はゼロではなくNULLであるということです。
問題を引き起こすには、ベーステーブルに行を挿入または削除しないだけです。
その声明は、最初に聞こえるほどクレイジーではありません。
重要なのは、ベーステーブルの行に影響を与えない挿入クエリまたは削除クエリは引き続きビューを更新するということです。 クエリプランのインデックス付きビューメンテナンス部分にあるスカラーStreamAggregateは、入力がない場合でも出力行を生成するためです。 StreamAggregateに続くComputeScalarも、行数がゼロの場合にNULLの合計を生成します。
次のスクリプトは、動作中のバグを示しています。
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
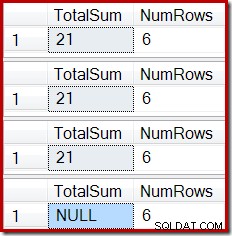
そのスクリプトの出力を以下に示します。
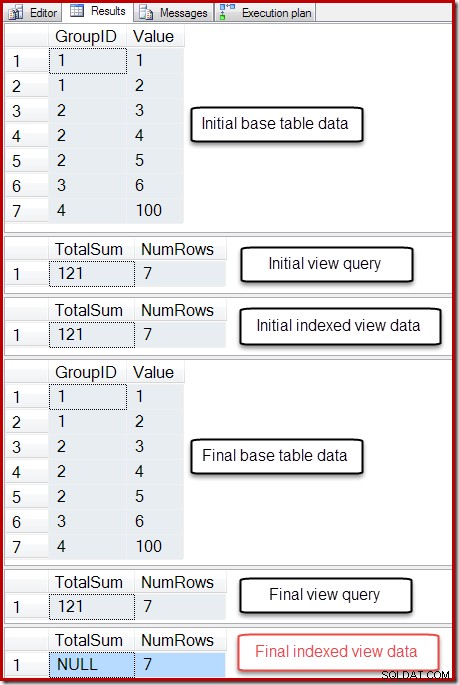
インデックス付きビューの[合計]列の最終状態が、基になるビュークエリまたはベーステーブルデータと一致しません。 NULLの合計がビューを破損しました。これは、(インデックス付きビューで)DBCCCHECKTABLEを実行することで確認できます。
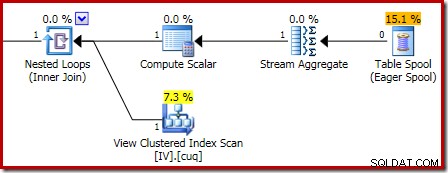
破損の原因となった実行計画を以下に示します。
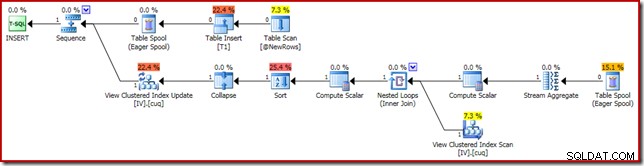
ズームインすると、StreamAggregateへのゼロ行の入力と1行の出力が表示されます。
挿入の代わりに削除を使用して上記の破損スクリプトを試してみたい場合は、次の例を参照してください。
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
削除はベーステーブルの行には影響しませんが、インデックス付きビューの合計列をNULLに変更します。
バグの一般化
おそらく、行に影響を与えず、このインデックス付きビューの破損を引き起こすベーステーブルクエリをいくつでも挿入および削除することができます。ただし、同じ基本的な問題が、ベーステーブルの行に影響を与えない挿入と削除だけではなく、より広範なクラスの問題に当てはまります。
たとえば、実行する挿入を使用して同じ破損を生成する可能性があります。 ベーステーブルに行を追加します。重要な要素は、追加された行がビューの対象にならないことです。 。これにより、Stream Aggregateへの入力が空になり、次のComputeScalarから破損の原因となるNULL行が出力されます。
これを実現する1つの方法は、ベーステーブルの行の一部を拒否するWHERE句をビューに含めることです。
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); ビューに含まれるグループIDの新しい制限を考えると、次の挿入はベーステーブルに行を追加しますが、それでもインデックス付きビューが破損すると、合計がNULLになります。
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; 出力には、今ではおなじみのインデックスの破損が表示されます:
同様の効果は、1つ以上の内部結合を含むビューを使用して生成できます。ベーステーブルに追加された行が拒否される限り(たとえば、結合に失敗したため)、Stream Aggregateは行を受け取らず、Compute ScalarはNULLの合計を生成し、インデックス付きビューが破損する可能性があります。
>最終的な考え
この問題は(少なくとも私が知る限り)更新クエリでは発生しませんが、これは設計よりも偶然のようです。問題のあるStream Aggregateは、潜在的に脆弱な更新計画にまだ存在しますが、ComputeScalarはNULLの合計は追加されません(またはおそらく最適化されます)。更新クエリを使用してバグを再現できた場合はお知らせください。
このバグが修正されるまで(または、インデックス付きビューでスカラー集計が許可されなくなるまで)、GROUPBY句を指定せずにインデックス付きビューで集計を使用する場合は十分に注意してください。
この記事は、Vladimir Moldovanenkoによって提出されたConnectアイテムによって促されました。彼は、私の古いブログ投稿(MERGEステートメントによって引き起こされた別のインデックス付きビューの破損に関する)にコメントを残してくれました。ウラジミールは、健全な理由からインデックス付きビューでスカラー集計を使用していたため、このバグを実稼働環境では決して発生しないエッジケースと判断するのは早すぎないでください。コネクトアイテムについて警告してくれたウラジミールに感謝します。