この記事は、テーブル式に関するシリーズの第5部です。パート1では、テーブル式の背景を説明しました。パート2、パート3、およびパート4では、派生テーブルの論理的側面と最適化の側面の両方について説明しました。今月は、Common Table Expression(CTE)の取り上げを開始します。派生テーブルと同様に、最初にCTEの論理的な処理について説明し、将来的には最適化の考慮事項について説明します。
私の例では、TSQLV5というサンプルデータベースを使用します。これを作成してデータを設定するスクリプトはここにあり、そのER図はここにあります。
CTE
共通テーブル式という用語から始めましょう。 。この用語もその頭字語CTEも、ISO /IECSQL標準仕様には含まれていません。したがって、この用語はデータベース製品の1つに由来し、後に他のデータベースベンダーの一部に採用された可能性があります。これは、MicrosoftSQLServerおよびAzureSQLDatabaseのドキュメントに記載されています。 T-SQLは、SQLServer2005以降でサポートされています。標準ではクエリ式という用語が使用されています。 外部クエリを含む、1つ以上のCTEを定義する式を表します。 リスト要素付きという用語を使用します T-SQLがCTEと呼ぶものを表すため。クエリ式の構文については、後ほど説明します。
用語の出典はさておき、一般的なテーブル式 、または CTE は、この記事の焦点となる構造に対してT-SQLの実践者が一般的に使用する用語です。それでは、最初に、それが適切な用語であるかどうかについて説明しましょう。 テーブル式という用語はすでに結論付けています 概念的にテーブルを返す式に適しています。派生テーブル、CTE、ビュー、およびインラインテーブル値関数はすべて、名前付きテーブル式のタイプです。 T-SQLがサポートしている。つまり、テーブル式 共通テーブル式の一部 確かに適切なようです。 共通について 用語の一部として、派生テーブルに対するCTEの設計上の利点の1つに関係している可能性があります。派生テーブル名(より正確には範囲変数名)を外部クエリで複数回再利用することはできないことに注意してください。逆に、CTE名は外部クエリで複数回使用できます。つまり、CTE名は共通です。 外側のクエリに。もちろん、この記事ではこの設計の側面を示します。
CTEは、モジュラーソリューションの開発の有効化、列エイリアスの再利用、通常は許可されない句のウィンドウ関数との間接的な相互作用、順序指定でTOPまたはOFFSET FETCHに間接的に依存する変更のサポートなど、派生テーブルと同様の利点を提供します。その他。ただし、派生テーブルと比較して設計上の利点がいくつかあります。これについては、構造の構文を説明した後で詳しく説明します。
構文
クエリ式の標準の構文は次のとおりです。
7.17<クエリ式>
機能
テーブルを指定します。
フォーマット
<クエリ式>::=
[
[
<リスト要素付き>::=
<クエリ名>[<左パレン><列リスト付き><右パレン>]
AS<テーブルサブクエリ>[<検索またはサイクル句> ]
<列リスト付き>::=<列名リスト>
<クエリ式本体>::=
<クエリ用語>
| <クエリ式本体>UNION[ALL | DISTINCT]
[<対応する仕様>]<クエリ用語>
| <クエリ式本体>EXCEPT[ALL | DISTINCT]
[<対応する仕様>]<クエリ用語>
<クエリ用語>::=
<クエリプライマリ>
| <クエリ用語>INTERSECT[ALL | DISTINCT]
[<対応する仕様>]<クエリプライマリ>
<クエリプライマリ>::=
<単純なテーブル>
| <左のパレン><クエリ式の本文>
[<順序による句>][<結果のオフセット句>][<最初の句をフェッチ>]
<右のパレン>
<単純なテーブル> ::=
<クエリ仕様>| <テーブル値コンストラクター>| <明示的なテーブル>
<明示的なテーブル>::=TABLE<テーブルまたはクエリ名>
<対応する仕様>::=
対応する[BY<左の親><対応する列のリスト>
<対応する列リスト>::=<列名リスト>
<最初の句をフェッチ>::=
FETCH {FIRST | NEXT}[<最初の数量を取得>]{ROW|行}{のみ|ネクタイ付き}
<最初の数量を取得>::=
<最初の行数を取得>
| <フェッチ最初のパーセンテージ>
<オフセット行数>::=<単純な値の指定>
<フェッチ最初の行数>::=<単純な値の指定>
<フェッチ最初のパーセンテージ>: :=<単純な値の指定>PERCENT
7.18<検索またはサイクル句>
機能
再帰クエリ式の結果で順序付けと循環検出情報の生成を指定します。
フォーマット
<検索またはサイクル句>::=
<検索句>| <サイクル句>| <検索句><サイクル句>
<検索句>::=
SEARCH<再帰検索順序>SET<シーケンス列>
<再帰検索順序>::=
DEPTH FIRSTBY<列名リスト>| BREADTH FIRSTBY<列名リスト>
<シーケンス列>::=<列名>
<サイクル句>::=
CYCLE<サイクル列リスト>SET<サイクルマーク列> TO<サイクルマーク値>
DEFAULT<非サイクルマーク値>USING<パス列>
<サイクル列リスト>::=<サイクル列>[{<カンマ><サイクル列>}… ]
<サイクル列>::=<列名>
<サイクルマーク列>::=<列名>
<パス列>::=<列名>
<サイクルマーク値>::=<値式>
<非サイクルマーク値>::=<値式>
7.3<テーブル値コンストラクター>
機能
テーブルに作成する<行値式>のセットを指定します。
標準用語クエリ式 WITH句、withリストを含む式を表します 、1つ以上のリスト要素で構成されている 、および外部クエリ。 T-SQLは、標準のリスト要素を使用を参照します。 CTEとして。
T-SQLは、すべての標準構文要素をサポートしているわけではありません。たとえば、グラフ構造で検索方向を制御し、サイクルを処理できる、より高度な再帰クエリ要素の一部はサポートされていません。再帰クエリは来月の記事の焦点です。
CTEに対する簡略化されたクエリのT-SQL構文は次のとおりです。
米国の顧客を表すCTEに対する簡単なクエリの例を次に示します。
派生テーブルに対するステートメントの場合と同じように、CTEに対するステートメントにも同じ3つの部分があります。
派生テーブルと比較したCTEの設計の違いは、コード内のこれら3つの要素がどこにあるかです。派生テーブルでは、内部クエリは外部クエリのFROM句内にネストされ、テーブル式の名前はテーブル式自体の後に割り当てられます。要素は一種の絡み合っています。逆に、CTEの場合、コードは3つの要素を分離します。最初にテーブル式の名前を割り当てます。次に、テーブル式を指定します—最初から最後まで中断なしで。 3番目に、外部クエリを指定します。最初から最後まで、中断することはありません。後で、「設計上の考慮事項」で、これらの設計の違いの影響について説明します。
CTEとステートメントターミネータとしてのセミコロンの使用について一言。残念ながら、標準のSQLとは異なり、T-SQLではすべてのステートメントをセミコロンで終了する必要はありません。ただし、T-SQLでは、ターミネータがないとコードがあいまいになる場合はほとんどありません。そのような場合、終了は必須です。そのようなケースの1つは、WITH句が複数の目的で使用されるという事実に関係しています。 1つはCTEを定義することであり、もう1つはクエリのテーブルヒントを定義することであり、いくつかの追加のユースケースがあります。例として、次のステートメントでは、WITH句を使用して、テーブルヒントを使用してシリアル化可能な分離レベルを強制します。
あいまいさの可能性があるのは、CTE定義の前に終了していないステートメントがある場合です。この場合、パーサーはWITH句が最初のステートメントに属しているか2番目のステートメントに属しているかを判別できない可能性があります。これを示す例を次に示します。
ここで、パーサーは、WITH句を使用して、最初のステートメントでCustomersテーブルのテーブルヒントを定義するのか、CTE定義を開始するのかを判断できません。次のエラーが発生します:
もちろん、修正はCTE定義の前にあるステートメントを終了することですが、ベストプラクティスとして、実際にはすべてのステートメントを終了する必要があります。
次のように、CTE定義をセミコロンで始める人もいることに気づいたかもしれません。
このプラクティスのポイントは、将来のエラーの可能性を減らすことです。後で誰かがスクリプトのCTE定義の直前に終了していないステートメントを追加し、スクリプト全体をチェックせず、ステートメントだけをチェックした場合はどうなりますか? WITH句の直前のセミコロンは、事実上、ステートメントターミネータになります。この練習の実用性は確かにわかりますが、少し不自然です。達成するのは難しいですが、推奨されるのは、すべてのステートメントの終了を含め、組織に優れたプログラミング手法を浸透させることです。
CTE定義で内部クエリとして使用されるテーブル式に適用される構文規則に関しては、派生テーブル定義で内部クエリとして使用されるテーブル式に適用される構文規則と同じです。それらは:
詳細については、シリーズのパート2の「テーブル式はテーブルです」のセクションを参照してください。
経験豊富なT-SQL開発者が派生テーブルとCTEのどちらを使用するかについて調査した場合、どちらが優れているかについて全員が同意するわけではありません。当然、人によってスタイリングの好みは異なります。派生テーブルを使用することもあれば、CTEを使用することもあります。 2つのツール間の特定の言語設計の違いを意識的に識別し、特定のソリューションの優先順位に基づいて選択できるのは良いことです。時間と経験があれば、より直感的に選択できます。
さらに、テーブル式と一時テーブルの使用を混同しないことが重要ですが、これはパフォーマンス関連のディスカッションであり、今後の記事で取り上げます。
CTEには再帰的なクエリ機能があり、派生テーブルにはありません。したがって、それらに依存する必要がある場合は、当然CTEを使用します。再帰クエリは来月の記事の焦点です。
パート2では、派生テーブルのネストは、ロジックに従うのが難しくなるため、コードが複雑になると考えていることを説明しました。次の例を示し、70人を超える顧客が注文した注文年を特定しました。
CTEはネストをサポートしていません。したがって、CTEに基づいてソリューションを確認またはトラブルシューティングするときに、ネストされたロジックで迷子になることはありません。ネストする代わりに、同じWITHステートメントで複数のCTEをコンマで区切って定義することにより、よりモジュール化されたソリューションを構築します。各CTEは、中断することなく最初から最後まで書き込まれるクエリに基づいています。コードの明確さと保守性の観点からは、これは良いことだと思います。
CTEを使用した前述のタスクの解決策は次のとおりです。
私はCTEベースのソリューションの方が好きです。しかし、繰り返しになりますが、経験豊富な開発者に、上記の2つのソリューションのどちらを好むかを尋ねてください。そうすれば、全員が同意するわけではありません。実際には、ネストされたロジックを好み、すべてを1か所で確認できることを好む人もいます。
派生テーブルに対するCTEの非常に明確な利点の1つは、ソリューション内の同じテーブル式の複数のインスタンスと対話する必要がある場合です。シリーズのパート2の派生テーブルに基づく次の例を思い出してください。
このソリューションは、注文年数、1年あたりの注文数、および当年と前年度の数の差を返します。はい、LAG関数を使用するとより簡単に実行できますが、ここでの私の焦点は、この非常に具体的なタスクを達成するための最良の方法を見つけることではありません。この例を使用して、名前付きテーブル式の特定の言語設計の側面を説明します。
このソリューションの問題は、テーブル式に名前を割り当てて、同じ論理クエリ処理ステップで再利用できないことです。 FROM句のテーブル式自体にちなんで派生テーブルに名前を付けます。派生テーブルを結合の最初の入力として定義して名前を付ける場合、その派生テーブル名を同じ結合の2番目の入力として再利用することもできません。同じテーブル式の2つのインスタンスを派生テーブルで自己結合する必要がある場合は、コードを複製する以外に選択肢はありません。上記の例で行ったことです。逆に、CTE名は、前述の3つ(CTE名、内部クエリ、外部クエリ)の中でコードの最初の要素として割り当てられます。論理クエリ処理の用語では、外部クエリに到達するまでに、CTE名はすでに定義されており、使用可能です。これは、次のように、外部クエリでCTE名の複数のインスタンスを操作できることを意味します。
このソリューションには、同じテーブル式の2つのコピーを維持する必要がないという点で、派生テーブルに基づくソリューションよりもプログラム性に明らかな利点があります。物理的な処理の観点からそれについてもっと言うことがあり、一時的なテーブルの使用と比較しますが、パフォーマンスに焦点を当てた将来の記事でそうします。
派生テーブルに基づくコードがCTEに基づくコードと比較した場合の利点のひとつは、テーブル式が持つはずのクロージャープロパティに関係しています。関係式のクロージャープロパティは、入力と出力の両方が関係であり、したがって、関係が期待される場所で、さらに別の関係式への入力として関係式を使用できることを覚えておいてください。同様に、テーブル式はテーブルを返し、別のテーブル式の入力テーブルとして使用できるはずです。これは、派生テーブルに基づくクエリにも当てはまります。テーブルが期待される場所で使用できます。たとえば、次の例のように、派生テーブルに基づくクエリをCTE定義の内部クエリとして使用できます。
ただし、CTEに基づくクエリには同じことが当てはまりません。概念的にはテーブル式と見なされると想定されていますが、派生テーブル定義、サブクエリ、およびCTE自体の内部クエリとして使用することはできません。たとえば、次のコードはT-SQLでは無効です。
幸いなことに、CTEに基づくクエリを、ビューおよびインラインのテーブル値関数の内部クエリとして使用できます。これについては、今後の記事で取り上げます。
また、最後のクエリに基づいていつでも別のCTEを定義し、最も外側のクエリをそのCTEと相互作用させることができることを忘れないでください:
トラブルシューティングの観点から、前述のように、私は通常、派生テーブルに基づくコードと比較して、CTEに基づくコードのロジックに従う方が簡単だと思います。ただし、派生テーブルに基づくソリューションには、図1に示すように、任意のネストレベルを強調表示して、それを個別に実行できるという利点があります。
CTEを使用すると、事態はさらに複雑になります。 CTEを含むコードを実行可能にするには、WITH句で始まり、コンマで区切られた1つ以上の名前付きの括弧で囲まれたテーブル式が続き、その後にコンマのない括弧のないクエリが続く必要があります。完全なソリューションのコードだけでなく、真に自己完結型の内部クエリを強調表示して実行することができます。ただし、ソリューションの他の中間部分を強調表示して正常に実行することはできません。たとえば、図2は、C2を表すコードを実行しようとして失敗したことを示しています。
したがって、CTEを使用する場合、ソリューションの中間ステップのトラブルシューティングを行うには、やや厄介な手段に頼る必要があります。たとえば、一般的な解決策の1つは、関連するCTEのすぐ下にSELECT *FROMyour_cteクエリを一時的に挿入することです。次に、挿入されたクエリを含むコードを強調表示して実行し、完了したら、挿入されたクエリを削除します。図3は、この手法を示しています。
問題は、コードに変更を加えるたびに(上記のような一時的なマイナーなものであっても)、元のコードに戻そうとすると、新しいバグが発生する可能性があることです。
もう1つのオプションは、コードのスタイルを少し変えることです。たとえば、最初以外の各CTE定義は、次のような個別のコード行で始まります。
そうすれば、コードの中間部分を特定のCTEまで実行したいときはいつでも、コードに最小限の変更を加えるだけで実行できます。行コメントを使用して、そのCTEに対応する1行のコードのみをコメントアウトします。次に、コードを強調表示して、そのCTEの内部クエリまで実行します。これは、図4に示すように、最も外側のクエリと見なされます。
このスタイルに満足できない場合は、さらに別のオプションがあります。図5に示すように、対象のCTEの前にあるコンマの直前で始まり、開き括弧の後に終わるブロックコメントを使用できます。
それは個人的な好みに要約されます。私は通常、一時的に挿入されたSELECT*クエリ手法を使用します。
標準と比較して、テーブル値コンストラクターに対するT-SQLのサポートには一定の制限があります。構成に慣れていない場合は、最初にシリーズのパート2を確認してください。ここで、詳細を説明します。 T-SQLでは、テーブル値コンストラクターに基づいて派生テーブルを定義できますが、テーブル値コンストラクターに基づいてCTEを定義することはできません。
派生テーブルを使用するサポートされている例は次のとおりです。
残念ながら、CTEを使用する同様のコードはサポートされていません:
このコードは次のエラーを生成します:
ただし、いくつかの回避策があります。 1つは、派生テーブルに対してクエリを使用することです。派生テーブルは、次のように、CTEの内部クエリとしてテーブル値コンストラクターに基づいています。
もう1つは、テーブル値コンストラクターがT-SQLに導入される前に人々が使用していた手法に頼ることです。たとえば、次のように、UNIONALL演算子で区切られた一連のFROMlessクエリを使用します。
列エイリアスはCTE名の直後に割り当てられていることに注意してください。
2つの方法は同じように代数化および最適化されるため、より快適な方を使用してください。
私のソリューションで頻繁に使用するツールは、数値の補助テーブルです。 1つのオプションは、データベースに実際の数値テーブルを作成し、それに適度なサイズのシーケンスを入力することです。もう1つは、その場で数列を生成するソリューションを開発することです。後者のオプションでは、入力を目的の範囲の区切り文字にする必要があります(
このコードは次の出力を生成します:
L0と呼ばれる最初のCTEは、2行のテーブル値コンストラクターに基づいています。そこにある実際の値は重要ではありません。重要なのは、2つの行があることです。次に、L1からL5という名前の5つの追加のCTEのシーケンスがあり、それぞれが先行するCTEの2つのインスタンス間にクロス結合を適用します。次のコードは、各CTEによって生成される可能性のある行数を計算します。ここで、@LはCTEレベル番号です。
各CTEで得られる数値は次のとおりです。
レベル5に上がると、40億行を超える行になります。これは、私が考えることができる実際のユースケースには十分なはずです。次のステップは、Numsと呼ばれるCTEで行われます。 ROW_NUMBER関数を使用して、定義されていない順序(ORDER BY(SELECT NULL))に基づいて1から始まる整数のシーケンスを生成し、結果の列にrownumという名前を付けます。最後に、外部クエリは、rownumの順序に基づくTOPフィルターを使用して、目的のシーケンスカーディナリティ(@high – @low + 1)と同じ数の数値をフィルター処理し、結果の数値nを@low + rownum –1として計算します。
ここでは、CTE設計の美しさと、モジュール方式でソリューションを構築するときに実現する節約を実際に評価できます。最終的に、ネスト解除プロセスは、定数に基づく2つの行で構成される32個のテーブルを解凍します。これは、SentryOneプランエクスプローラーを使用した図6に示すように、このコードの実行プランで明確に確認できます。
各定数スキャン演算子は、2行の定数のテーブルを表します。つまり、Top演算子はそれらの行を要求する演算子であり、目的の数を取得した後に短絡します。 Top演算子に流れ込む矢印の上に示されている10行に注目してください。
この記事の焦点はCTEの概念的な扱いであり、物理的/パフォーマンスの考慮事項ではないことを私は知っていますが、計画を見ると、コードが舞台裏で翻訳されるものの長蛇の列と比較して、コードの簡潔さを本当に理解できます。
派生テーブルを使用して、各CTE参照をそれが表す基になるクエリで置き換えるソリューションを実際に作成できます。あなたが得るものはかなり怖いです:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
フォーマット
<テーブル値コンストラクタ>::=VALUES<行値式リスト>
<行値式リスト>::=
<テーブル行値式>[{
<コンテキストで入力されたテーブル値のコンストラクタ>::=
VALUES<コンテキストで入力された行の値の式リスト>
<コンテキストで入力された行の値の式リスト>::=
<コンテキストで入力された行の値の式>
[{WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
'UC'の近くの構文が正しくありません。これが一般的なテーブル式であることが意図されている場合は、前のステートメントをセミコロンで明示的に終了する必要があります。 SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
設計上の考慮事項
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70;> WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 図1:派生テーブルを使用してコードの一部を強調表示して実行できます>
図1:派生テーブルを使用してコードの一部を強調表示して実行できます>  図2:CTEでコードの一部を強調表示して実行できない
図2:CTEでコードの一部を強調表示して実行できない  図3:関連するCTEの下にSELECT*を挿入
図3:関連するCTEの下にSELECT*を挿入 , cte_name AS (
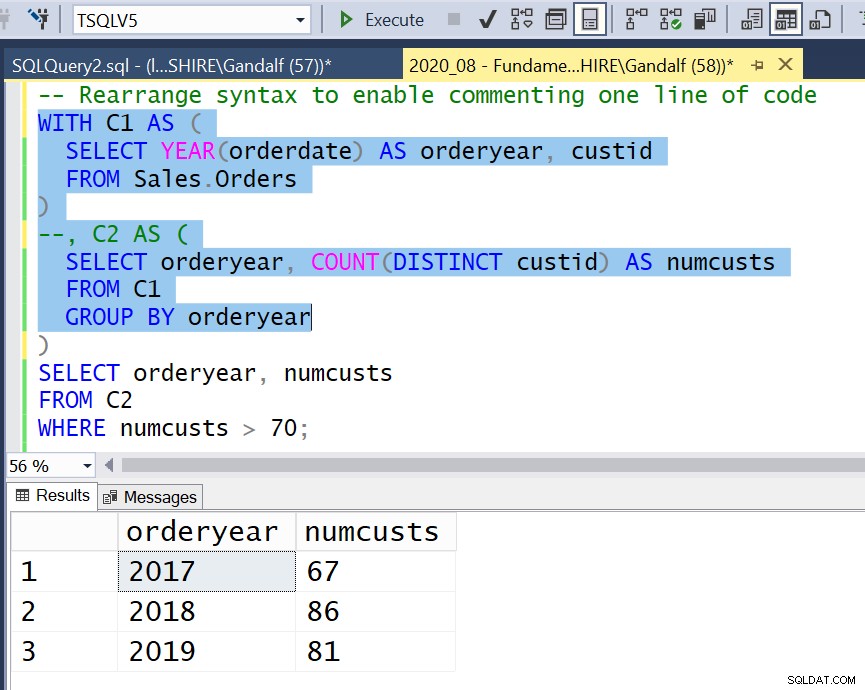 図4:構文を並べ替えて1行のコードにコメントできるようにする
図4:構文を並べ替えて1行のコードにコメントできるようにする  図5:ブロックコメントを使用する
図5:ブロックコメントを使用する テーブル値コンストラクター
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
キーワード「VALUES」の近くの構文が正しくありません。 WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; 数列の生成
@lowと呼びます)。 および@high )。ソリューションが潜在的に広い範囲をサポートすることを望んでいます。この特定の例では、CTEを使用して、1001から1010の範囲をリクエストする、この目的のための私のソリューションを次に示します。DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE カーディナリティ L0 2 L1 4 L2 16 L3 256 L4 65,536 L5 4,294,967,296  図6:数列を生成するクエリの計画
図6:数列を生成するクエリの計画 DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
概要
アイテム Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes