2月に、SQL Serverの自動プラン修正に関するブログ投稿を書きました。この投稿では、自動チューニング機能の2番目のコンポーネントである自動インデックス管理について説明します。自動インデックス管理はAzureSQLDatabaseでのみ使用可能であり、現在、オンプレミスのSQLServerの次のリリースで使用できるロードマップには含まれていません。このオプションは、自動プラン修正とは独立して有効になり、名前が示すように、データベース内のインデックスを管理します。具体的には、欠落しているインデックスを作成したり、使用されていないインデックスや重複しているインデックスを削除したりできます。これがどのように発生するかを見てみましょう。
カバーの下
自動インデックス管理は、データに基づいて決定を下します。潜在的なインデックス作成のために、欠落しているインデックスDMVの情報を使用し、それを経時的に追跡し、そのデータを内部モデルと組み合わせて、インデックスの利点を判断します。また、クエリストアを使用してインデックスがメリットを提供するかどうかを判断するため、自動プラン修正の場合と同様に、データベースでインデックスを有効にする必要があります。インデックスの削除に関しては、インデックス使用状況DMV(sys.dm_db_index_usage_stats)からのデータと、インデックスメタデータ(列数、列データ型など)が使用されます。
自動インデックス管理の有効化
前述のように、データベースに対してクエリストアを有効にする必要があります。これは、SSMS、T-SQL、およびAzureSQLデータベース用のRESTAPIを使用して実行できます。クエリストアはAzureのデータベースでデフォルトで有効になっており、2016年第4四半期から有効になっていることに注意してください。
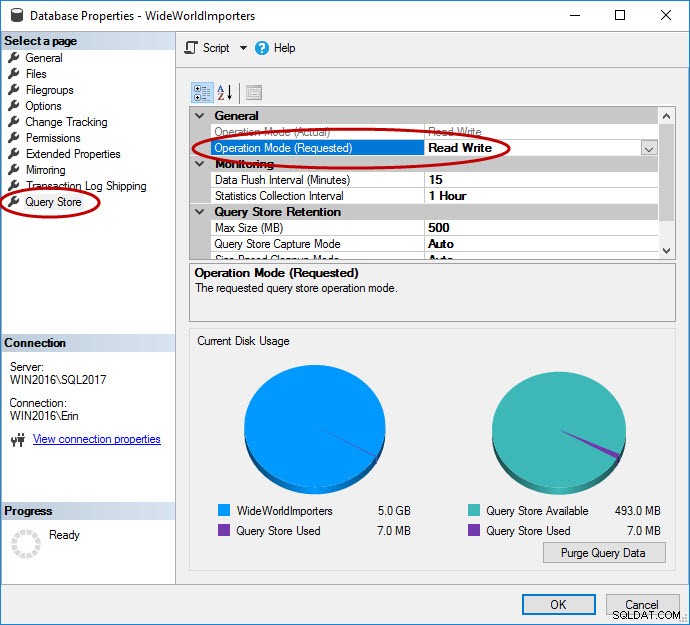
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
クエリストアを有効にすると、Azure Portal、T-SQL、またはEST APIを使用して、Azure SQLデータベースで自動インデックス管理を有効にできます(C#とPowerShellが機能しています)。
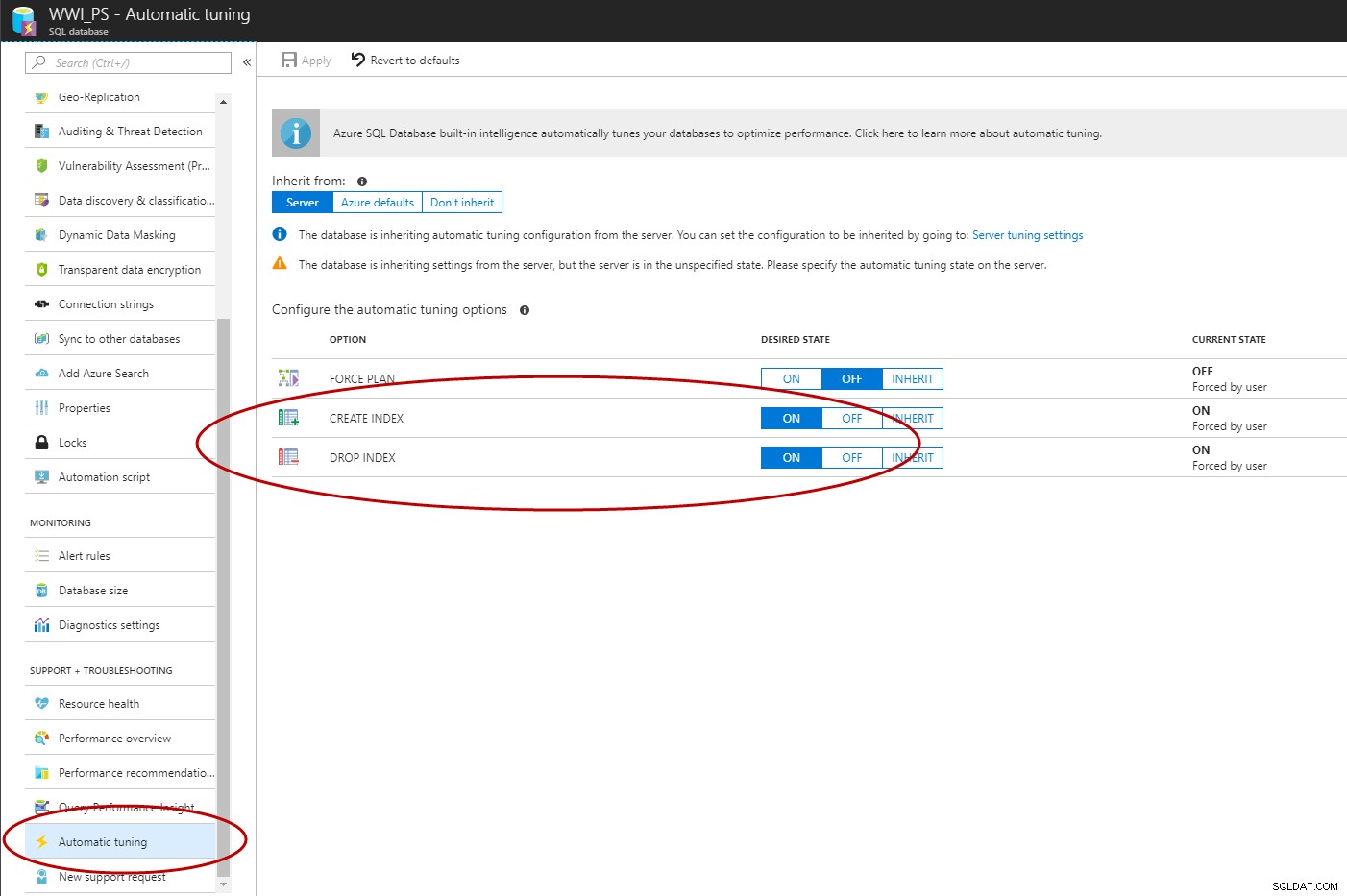
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
近い将来、Azure(https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/)の新しいデータベースで自動インデックス管理がデフォルトで有効になります。 2018年1月から、Microsoftは、まだ有効になっていないAzure SQLデータベースの自動調整を有効にするロールアウトを開始し、必要に応じてオプションを無効にできるように管理者に通知を送信しました。このプロセスには数か月かかるため、まだ通知を受け取っていない場合でも、慌てる必要はありません。
仕組み
現在、インデックスの作成には、データが追跡される7日間*のローリングウィンドウがあり、モデルがインデックスを推奨するには、少なくとも9時間*のデータが必要です。ベースラインとして使用されるクエリストアの12時間*のデータ。インデックスが大きなメリットをもたらすと判断された場合、SQLServerがインデックスを作成します。
*これらの値は、モデルの開発に伴い、将来変更される可能性があります。
注:現在、モデルは推奨事項をマージします。つまり、テーブルに複数のインデックスが推奨されているが、すべてのオプションをカバーする1つのインデックスを作成できる場合、現在その1つのインデックスを作成できます。ただし、このモデルは現在、推奨されるインデックスを既存のインデックスとマージするほどインテリジェントではありません。
インデックスが作成されると、SQL Serverは、クエリストアを使用してインデックスがメリットを提供することを確認します(したがって、データベースに対して有効にする必要があります)。新しいインデックスを使用するクエリのパフォーマンスを監視し、インデックスが追加される前とインデックスを使用する場合のクエリのCPUを比較します。インデックスの結果としてクエリパフォーマンスが低下した場合、インデックスは元に戻ります(ドロップされます)。 SQL Serverは、最大3日間、または関連するワークロードが100%分析されるまで、クエリのパフォーマンスを監視します。その期間の後、インデックスに回帰の兆候が見られない場合、インデックスのパフォーマンスは再度確認されません。
自動インデックス管理でインデックスが作成され、2か月後にワークロードが変更され、以前に自動的に作成された同じインデックスの恩恵を受けるが、列が1つ追加された場合、SQLServerは現在新しいインデックスを作成することを理解してください。現在、既存の自動作成されたインデックスを変更するロジックはありませんが、その機能は機能のロードマップにあります。
インデックスの削除に関して、インデックスに90日間シークまたはスキャンがないが、メンテナンスコストがかかる場合(つまり、挿入、更新、または削除がある場合)、インデックスは削除されます。重複するインデックスも完全に重複していると仮定して削除されます(インデックスが完全に同じであるかどうかを判断するためにスキーマが使用されます)。キー列と含まれる列(該当する場合)に関して重複するインデックスがあるが、それらの1つ以上にフィルターがある場合、それらは真に重複しておらず、インデックスは削除されません。
参考までに、AzureSQLDatabaseにはCREATEINDEXの推奨値の2倍のDROPINDEXの推奨事項があります。
DROP INDEXオプションを有効にすると、SQLServerはユーザーが作成したインデックスを削除します。 CREATE INDEXオプションを有効にすると、SQL Serverにはインデックスを自動的に作成する機能があり、それらのインデックスを削除することもできます(ただし、ユーザーが作成したインデックスは削除されません)。最後に、インデックスは、DTUによって決定されるように、ピーク時以外のワークロード時に作成および削除されます。ワークロードが80%DTUを超える場合、SQL Serverは、システムの負荷が減少するまで、インデックスの作成または削除を待機します。
本当にSQLServerに制御を任せるつもりですか?
たぶん。この機能に関する私の推奨事項は、最初は「信頼するが検証する」アプローチを必要とします。
自動プラン修正と同様に、自動インデックス管理は、ほぼ200万のAzureSQLデータベースからキャプチャされた大量のデータを使用して開発されました。自動インデックス管理機能は、2016年の第1四半期から、インデックスアドバイザーの一部としてAzureSQLDatabaseで利用できるようになりました。
この機能で使用されるアルゴリズムは、より多くのデータベースがそれを使用し、より多くのデータがキャプチャおよび分析されるにつれて、進化し、時間とともに進化し続けています。ただし、現在いくつかの制限があります。
- インデックスの推奨事項は既存のインデックスに対して評価されないため、現在、新しいインデックスと既存のインデックス間のインデックス統合は利用できません。
- インデックスがSELECTにメリットをもたらす場合、INSERT、UPDATE、およびDELETEによる変更のオーバーヘッドは作成前にはわかりません。 SQL Serverは、インデックスが実装された後の検証プロセス中にこのオーバーヘッドを監視します。
自動インデックス管理には、次のようなメリットがあります。
- SQL Serverデータベースを管理する必要があるが、DBAではない人にとって、インデックスの推奨事項は非常に役立ちます。
- インデックスの推奨事項は、CREATEおよびDROPインデックスオプションが有効になっていない場合でも、sys.dm_db_tuning_recommendationsDMVに取り込まれます。したがって、SQL Serverが行う可能性のある変更について確信が持てない場合は、DMVにキャプチャされたものを確認してから、推奨事項を手動で実装することを決定できます。
注:推奨事項を手動で実装した場合、SQLServerは検証を実行しません。ポータル([適用]ボタンを使用)またはREST APIを介して推奨を実装すると、自動アクションであるかのように実行され、検証が実行されます(回帰がある場合は、インデックスが自動的に元に戻される可能性があります)。
- 機能は引き続き改善されています。前にも言ったように、MicrosoftはDBAや開発者を仕事から外すようにコーディングしようとしているのではなく、手に負えない成果に対処しようとしているので、インテリジェントに自動化できないタスクやプロジェクトにより多くの時間を費やすことができます。
概要
インデックス管理の手綱を引き渡す準備ができていない場合は、私が理解します。ただし、少なくともAzure SQLデータベースがある場合は、sys.dm_db_tuning_recommendations DMVを定期的にチェックして、SQL Serverが推奨しているものを確認し、それをユーザーまたはサードパーティの監視ツールがインデックスの使用状況についてキャプチャしている可能性のあるデータと比較する必要があります。結局のところ、インデックスを完全かつ徹底的にレビューして、何が欠落していて、何が実際に使用されているのか、そして何がデータベースにオーバーヘッドを発生させているのかを理解するのはいつでしたか?