データの専門家は、常に最適な設計のデータベースを使用できるとは限りません。時々、あなたを泣かせるのは、当時は良いアイデアのように思えたので、私たちが自分たちでやったことです。サードパーティのアプリケーションが原因の場合もあります。時々彼らは単にあなたよりも前にいます。
この投稿で私が考えているのは、datetime(またはdatetime2、さらにはdatetimeoffset)列が実際には2つの列である場合です。1つは日付用、もう1つは時刻用です。 (オフセット用に別の列がある場合は、おそらくあらゆる種類の傷に対処しなければならなかったので、次に会うときに抱擁をします。)
Twitterで調査したところ、これは非常に現実的な問題であり、約半数の人が時々日付と時刻を処理する必要があることがわかりました。
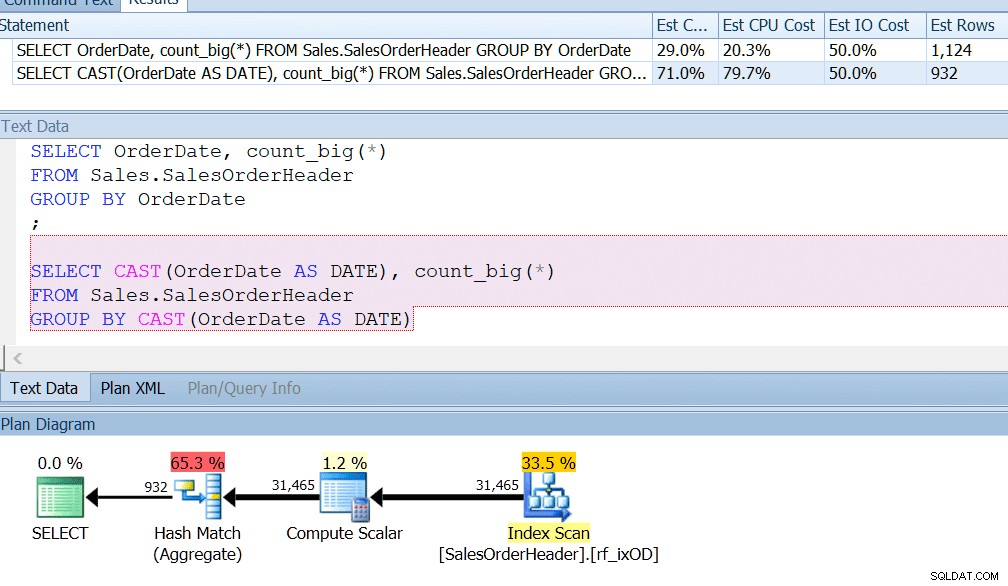
AdventureWorksはこれをほぼ実行します。Sales.SalesOrderHeaderテーブルを見ると、OrderDateという日時列が表示されます。この列には、常に正確な日付が含まれています。あなたがAdventureWorksのレポート開発者であれば、GROUP BY OrderDateなどを使用して、特定の日の注文数を検索するクエリを作成した可能性があります。これが日時列であり、深夜以外の時刻も格納される可能性があることを知っていたとしても、インデックスを適切に使用するためだけにGROUPBYOrderDateと言うことになります。 GROUP BY CAST(OrderDate AS DATE)はそれをカットしません。
OrderDateにインデックスがあり、その列を定期的にクエリしている場合と同じように、CAST(OrderDate AS DATE)によるグループ化はCPUの観点から約4倍悪いことがわかります。
そのため、列の使用法が変更された場合に苦痛の世界があることを知っているだけで、日付であるかのように列にクエリを実行できる理由を理解しています。たぶん、あなたはテーブルに制約を設けることによってこれを解決します。たぶん、あなたはただ頭を砂に置いただけです。
そして、誰かがやって来て「注文が発生した時刻も保存する必要があります」と言うと、OrderDateが単なる日付であると想定するすべてのコードを考え、OrderTime(データ型)と呼ばれる別の列があることを理解します。時間の、お願いします)が最も賢明なオプションになります。理解します。理想的ではありませんが、多くのものを壊すことなく機能します。
この時点で、OrderDateTimeも作成することをお勧めします。これは、時間を追加するのではなく、2つを結合する計算列になります(これは、0日目からの日数をCAST(OrderDate as datetime2)に追加することによって行う必要があります)。日付、これは一般的にかなり厄介です)。そして、それが賢明であるため、OrderDateTimeにインデックスを付けます。
しかし、多くの場合、日付と時刻が別々の列になっていることに気付くでしょう。基本的には、それについて何もできません。計算列はサードパーティのアプリケーションであり、何が壊れるかわからないため、追加することはできません。 SELECT *を実行しないでよろしいですか?いつの日か、列を追加して非表示にできるようになることを願っていますが、当面の間は、間違いなく何かを壊すリスクがあります。
そして、ご存知のように、msdbでさえこれを行います。どちらも整数です。そして、それは下位互換性のためだと思います。ただし、msdbのテーブルに計算列を追加することを検討しているとは思えません。
では、これをどのように照会しますか?特定の日時範囲内にあったエントリを検索するとしますか?
実験してみましょう。
まず、300万行のテーブルを作成し、関心のある列にインデックスを付けましょう。
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID);にインデックスixDateTimeを作成します。 (クラスター化されたインデックスを作成することもできましたが、クラスター化されていないインデックスの方が環境に適していると思います。)
データは次のようになります。たとえば、2011年8月2日の8:30と2011年8月5日の21:30の間の行を検索します。
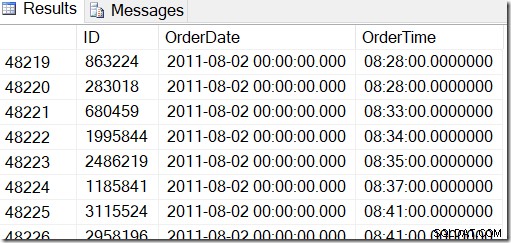
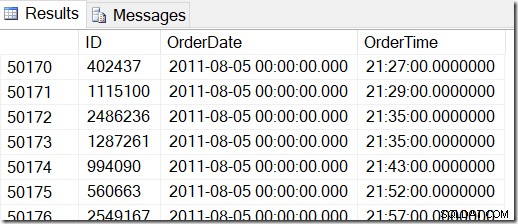
データを見ると、48221から50171までのすべての行が必要であることがわかります。これは50171-48221 + 1 =1951行です(+1は包括的範囲であるためです)。これは、私の結果が正しいことを確信するのに役立ちます。テーブルを生成するときにランダムな値を使用したため、おそらくマシン上で同様のことがありますが、正確ではありません。
私はこのようなことをすることはできないことを知っています:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…これには、4日に一晩で起こったことは含まれないためです。これにより、1268行になります–明らかに正しくありません。
1つのオプションは、列を結合することです:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
これにより、正しい結果が得られます。します。これは完全に引数不可であり、テーブル内のすべての行をスキャンすることができます。 300万行では、これを実行するのに数秒かかる場合があります。
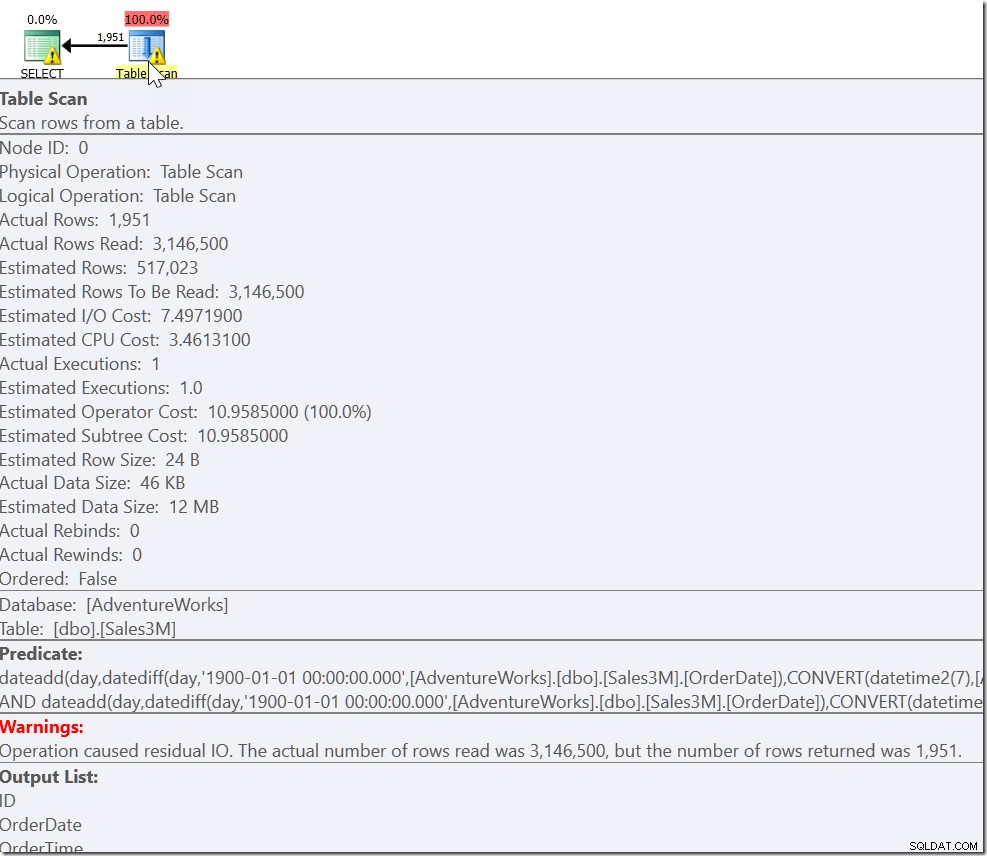
私たちの問題は、通常のケースと2つの特殊なケースがあることです。 OrderDate> ‘20110802’ AND OrderDate <‘20110805’を満たすすべての行が必要な行であることがわかっています。ただし、20110802の8:30以降、および20110805の21:30以前のすべての行も必要です。これにより次のようになります。
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
またはひどいです、私は知っています。必ずしもそうとは限りませんが、スキャンにつながる可能性もあります。ここでは、連結されて一意性がチェックされている3つのインデックスシークが表示されます。クエリオプティマイザは、同じ行を2回返す必要がないことを明らかに認識していますが、3つの条件が相互に排他的であることを認識していません。実際、1日以内の範囲でこれを行うと、間違った結果が得られます。
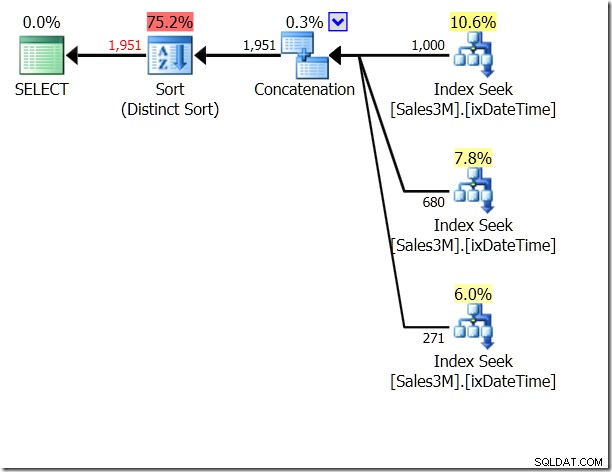
これにUNIONALLを使用できます。つまり、QOは、条件が相互に排他的であるかどうかを気にしません。これにより、連結された3つのシークが得られます。これはかなり良いことです。
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

しかし、それでも3つのシークです。統計IOによると、私のマシンでは20回の読み取りが行われています。

さて、sargabilityについて考えるとき、式の中にインデックス列を配置することを避けることだけでなく、何かが見えるのに何が役立つかについても考えます。 sargable。
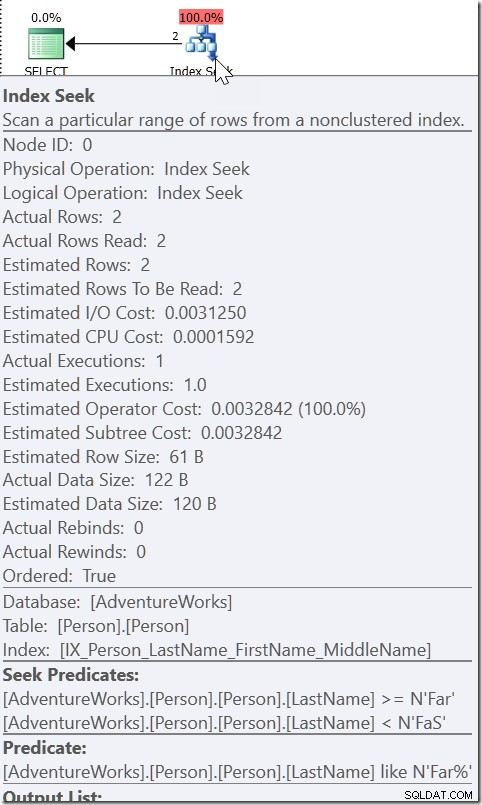
たとえば、WHERE LastName LIKE'Far%'を取り上げます。この計画を見ると、Seekがあり、Seek PredicateはFaSまで(ただしFaSを含まない)の任意の名前を探しています。そして、LIKE条件をチェックする残余述語があります。これは、QOがLIKEが引数可能であると見なしているためではありません。もしそうなら、それはシーク述語でLIKEを使用することができるでしょう。それは、そのLIKE条件によって満たされるすべてのものがその範囲内になければならないことを知っているからです。
WHERE CAST(OrderDate AS DATE)='20110805'
を取得します
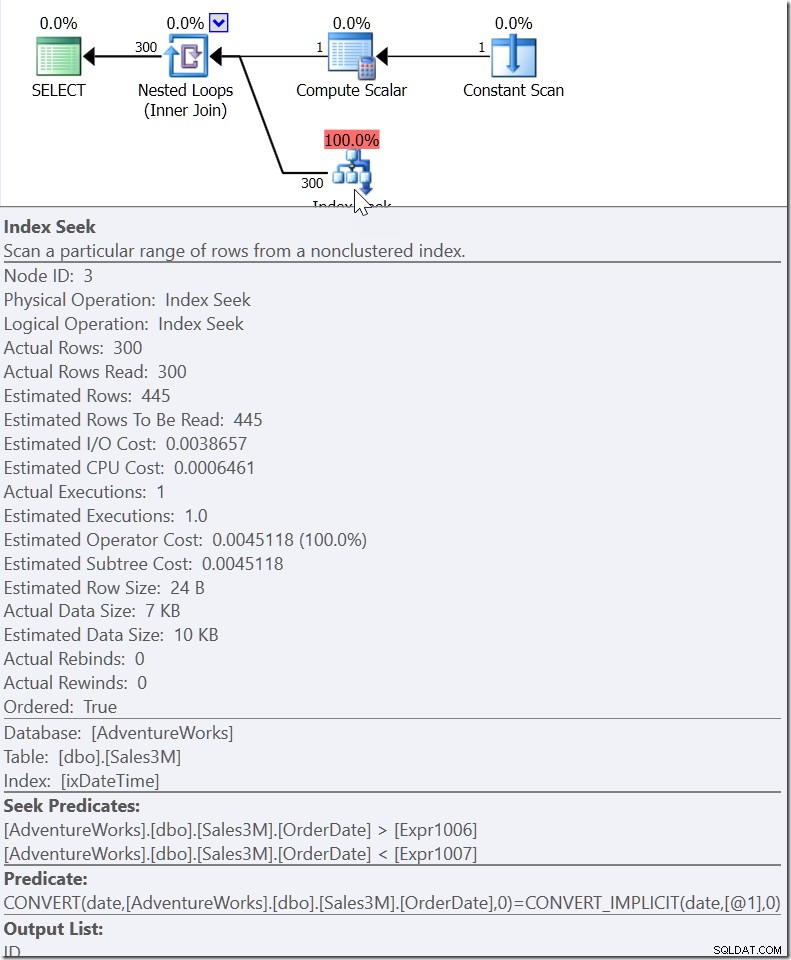
ここに、プランの他の場所で処理された2つの値の間でOrderDate値を検索するが、適切な値が存在する必要がある範囲を作成するSeek述語が表示されます。これは、> =2011080500:00および<2011080600:00(これは私が作成したものです)ではなく、別のものです。この範囲の開始値は、> =ではなく>であるため、2011080500:00よりも小さくする必要があります。私たちが本当に言えるのは、Microsoft内の誰かが、QOがこの種の述語にどのように応答するかを実装したとき、私が「ヘルパー述語」と呼ぶものを思い付くのに十分な情報を提供したということです。
さて、私はMicrosoftにもっと多くの関数を引数可能にしたいと思っていますが、その特定の要求はConnectを廃止するずっと前に閉じられました。
しかし、おそらく私が意味するのは、彼らがより多くのヘルパー述語を作成することです。
ヘルパー述語の問題は、ほぼ確実に、必要以上の行を読み取ることです。ただし、インデックス全体を調べるよりもはるかに優れています。
返したいすべての行のOrderDateが20110802から20110805の間にあることはわかっています。それは、私が望まない行があるということだけです。
それらを削除するだけで、これは有効です:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
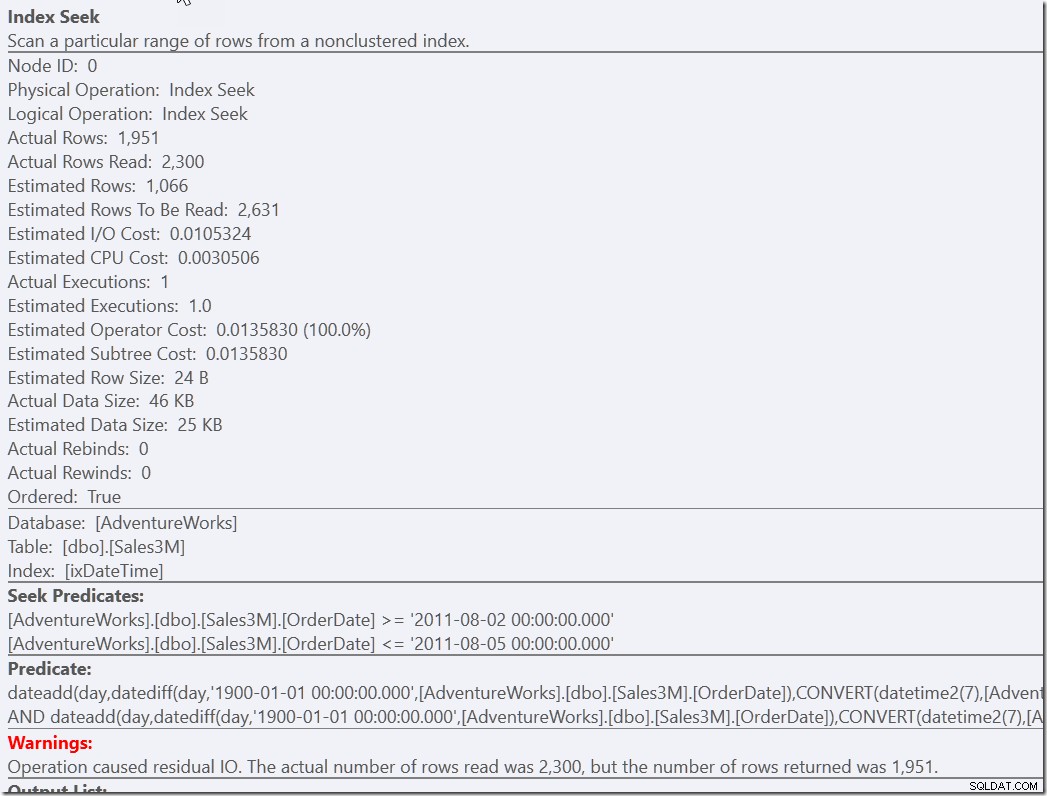
しかし、これは考え出すためにいくらかの努力を必要とする解決策であるように私は感じます。開発者側の労力は、正しいが遅いバージョンのヘルパー述語を提供するだけです。
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
これらのクエリは両方とも、適切な日にある2300行を見つけ、それらのすべての行を他の述語と照合する必要があります。 1つは2つのNOT条件をチェックする必要があり、もう1つは型変換と数学を実行する必要があります。しかし、どちらも以前よりもはるかに高速で、1回のシーク(13回の読み取り)を実行します。確かに、非効率的なRangeScanについての警告が表示されますが、これは3つの効率的なRangeScanを実行するよりも私の好みです。
ある意味で、この最後の例の最大の問題は、善意のある人がヘルパー述語が冗長であることに気づき、それを削除する可能性があることです。これは、すべてのヘルパー述語に当てはまります。コメントを入れてください。
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
素敵な仮の述語に収まらないものがある場合は、その述語を見つけて、それから何を除外する必要があるかを考えてください。より良い解決策を思い付くかもしれません。
@rob_farley