この投稿は、行の目標に関するシリーズの一部です。他の部分はここにあります:
- パート1:行の目標の設定と特定
- パート2:セミジョイン
- パート3:アンチジョイン
トップオペレーターによるアンチジョインの適用
反結合の適用では、内側のトップ(1)演算子がよく表示されます。 実行計画。たとえば、AdventureWorksデータベースの使用:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); 計画では、適用(外部参照)アンチジョインの内側にトップ(1)演算子が表示されています:
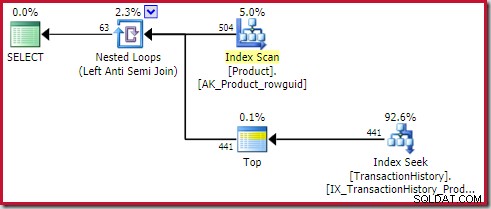
このトップオペレーターは完全に冗長です 。正確性、効率性、または行の目標が設定されていることを確認するために必要ではありません。
適用アンチ結合演算子は、結合で1つの行が表示されるとすぐに、(現在の反復の)内側の行のチェックを停止します。トップなしで適用アンチジョインプランを生成することは完全に可能です。では、なぜこの計画にトップオペレーターがいるのですか?
トップ演算子のソース
この無意味なTop演算子がどこから来ているのかを理解するには、サンプルクエリのコンパイルと最適化中に実行される主要な手順に従う必要があります。
いつものように、クエリは最初にツリーに解析されます。これは、サブクエリを持つ論理的な「存在しない」演算子を特徴としています。これは、この場合のクエリの記述形式と厳密に一致します。

存在しないサブクエリは、適用アンチジョインに展開されます:

次に、これはさらに論理的な左アンチセミジョインに変換されます。コストベースの最適化に渡される結果のツリーは次のようになります。

コストベースのオプティマイザによって実行される最初の調査は、論理的に異なるを導入することです。 アンチジョインキーの一意の値を生成するための、下部のアンチジョイン入力に対する操作。一般的な考え方は、結合時に重複した値をテストする代わりに、計画はそれらの値を事前にグループ化することでメリットが得られる可能性があるということです。
責任ある探索ルールはLASJNtoLASJNonDistと呼ばれます (左アンチセミジョインから左アンチセミジョインまで)。物理的な実装やコスト計算はまだ実行されていないため、これは重複する ProductID の存在に基づいて、論理的等価性を調査するオプティマイザーにすぎません。 値。グループ化操作が追加された新しいツリーを以下に示します。

考慮される次の論理変換は、結合を適用として書き直すことです。 。これは、ルール LASJNtoApplyを使用して調査されます (リレーショナル選択で適用するために左アンチセミ結合)。シリーズの前半で述べたように、適用から結合への以前の変換は、特に結合で機能する変換を有効にすることでした。結合を適用として書き換えることは常に可能であるため、これにより利用可能な最適化の範囲が広がります。
現在、オプティマイザは常にではありません コストベースの最適化の一環として、リライトの適用を検討してください。結合述語を内側にプッシュする価値があるようにするには、論理ツリーに何かが必要です。通常、これは一致するインデックスの存在になりますが、他の有望なターゲットがあります。この場合、これは ProductIDの論理キーです。 集計操作によって作成されます。
このルールの結果は、内側の選択との相関アンチ結合です:

次に、オプティマイザは、リレーショナル選択(相関結合述語)を、オプティマイザによって以前に導入された個別の(group bygreg)を超えて、さらに内側に移動することを検討します。これはルールSelOnGbAggによって行われます。 、可能な限り集約によって適切なグループを通過する選択(述語)の多くを移動します(選択の一部が取り残される場合があります)。このアクティビティは、選択をプッシュするのに役立ちます リーフレベルのデータアクセス演算子にできるだけ近づけて、行を早く削除し、後でインデックスの照合を容易にします。
この場合、フィルターはグループ化操作と同じ列にあるため、変換は有効です。その結果、選択全体が集計の下にプッシュされます:

対象となる最後の操作は、ルール GbAggToConstScanOrTopによって実行されます。 。この変換は、置換に見えます コンスタントスキャンまたはトップを使用した集計によるグループ化 論理演算。グループ化列は、プッシュダウンされた選択を通過する各行で一定であるため、このルールはツリーと一致します。すべての行が同じProductIDを持つことが保証されています 。その単一の値でグループ化すると、常に1つの行が生成されます。したがって、集合体をTop(1)に変換することは有効です。だから、これがトップの由来です。
実装と原価計算
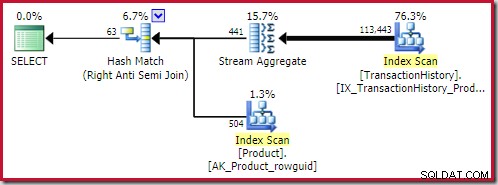
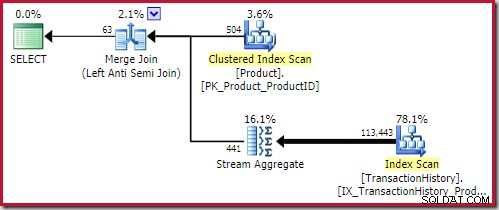
オプティマイザは、一連の実装ルールを実行して、これまでに検討した有望な論理的代替案のそれぞれの物理演算子を検索します(メモ構造に効率的に格納されます)。ハッシュとマージのアンチジョイン物理オプションは、導入された集計を含む最初のツリーから取得されます( rule LASJNtoLASJNonDist の提供) 覚えて)。アプライは、物理的なトップを構築し、選択をインデックスシークに一致させるためにもう少し作業が必要です。
最高のハッシュアンチジョイン 見つかったソリューションのコストは0.362143 単位:
最高のマージアンチジョイン ソリューションは0.353479で提供されます ユニット(やや安い):
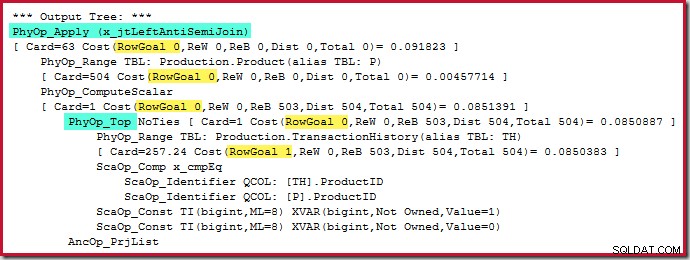
アンチジョインを適用 費用0.091823 ユニット(大幅に安い):
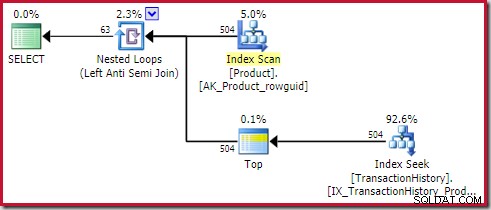
賢明な読者は、適用アンチジョイン(504)の内側の行数が、同じプランの前のスクリーンショットと異なることに気付くかもしれません。これは、前の計画が実行後だったのに対し、これは推定計画であるためです。この計画が実行されると、すべての反復で内側に合計441行しか見つかりません。これは、セミ/アンチ結合プランを適用する際の表示の問題の1つを浮き彫りにします。オプティマイザーの最小推定値は1行ですが、セミ結合またはアンチ結合では、各反復で常に1行または行が見つかりません。上に示した504行は、504回の反復ごとに1行を表しています。数値を一致させるには、推定値を毎回441/504 =0.875行にする必要があります。これは、おそらく同じくらい人々を混乱させるでしょう。
とにかく、上記の計画は、2つの理由から、反結合の適用の内側で行ゴールの資格を得るのに十分な「幸運」です。
- アンチジョインは、コストベースのオプティマイザでジョインからアプライに変換されます。これにより、行の目標が設定されます(パート3で設定)。
- Top(1)演算子は、そのサブツリーにも行の目標を設定します。
1の行の目標は少なくないため、Top演算子自体には(適用からの)行の目標はありません。 通常の見積もりよりも1行です(以下のPhyOp_Topの場合はCard =1):
アンチジョインアンチパターン
次の一般的な平面形状は、私がアンチパターンと見なすものです。
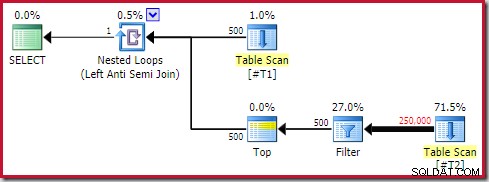
内側にTop(1)演算子を使用したapplyantijoinを含むすべての実行プランで問題が発生するわけではありません。それにもかかわらず、それは認識するパターンであり、ほとんどの場合、さらなる調査が必要です。
注意すべき4つの主な要素は次のとおりです。
- 相関するネストされたループ(適用 )アンチジョイン
- トップ(1) すぐ内側のオペレーター
- 外側の入力にかなりの数の行があります(したがって、内側は何度も実行されます)
- 潜在的に高価 トップの下のサブツリー
「$$$」サブツリーは、実行時にコストがかかる可能性があるサブツリーです。 。これは認識が難しい場合があります。運が良ければ、フルテーブルやインデックススキャンのような明らかなものがあります。より困難なケースでは、サブツリーは一見完全に無害に見えますが、より詳しく見るとコストのかかるものが含まれています。かなり一般的な例を挙げると、少数の行を返すことが期待されているが、非常に多数の行をテストして適格な少数の行を見つける高価な残差述語が含まれているインデックスシークが表示される場合があります。
前述のAdventureWorksコード例には、「潜在的に高価な」サブツリーがありませんでした。インデックスシーク(残りの述語なし)は、行の目標の考慮事項に関係なく、最適なアクセス方法になります。これは重要なポイントです。オプティマイザーに常に効率的なを提供することです。 相関結合の内側にあるデータアクセスパスは常に良い考えです。これは、アプライが内側にトップ(1)演算子を使用してアンチジョインモードで実行されている場合に、さらに当てはまります。
このアンチパターンが原因で実行時のパフォーマンスがかなり悪い例を見てみましょう。
例
次のスクリプトは、2つのヒープ一時テーブルを作成します。最初の行には、1から500までの整数を含む500行があります。 2番目のテーブルには、最初のテーブルの各行の500コピー、合計250,000行があります。どちらのテーブルもsql_variantを使用しています データ型。
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; パフォーマンス
ここで、大きなテーブルには存在しない(もちろん存在しない)小さなテーブルの行を検索するクエリを実行します。
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); このクエリは約20秒実行されます 、500行を250,000行と比較するには非常に長い時間がかかります。 SSMSの見積もり計画では、パフォーマンスが非常に悪い理由を理解するのが困難です。
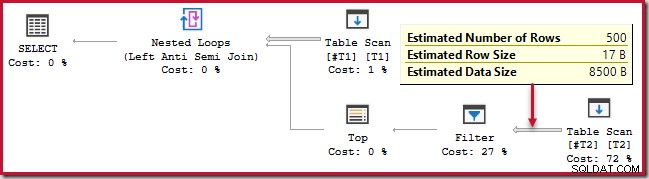
オブザーバーは、SSMSの推定計画が反復ごとの内側の推定を示していることに注意する必要があります。 ネストされたループ結合の。紛らわしいことに、SSMSの実際の計画では、すべての反復の行数が表示されます。 。 Plan Explorerは、推定された計画に必要な簡単な計算を自動的に実行して、予想される行の総数も表示します。
それでも、実行時のパフォーマンスは推定よりもはるかに劣ります。実行後(実際の)実行計画は次のとおりです。
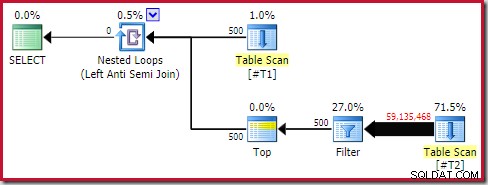
別のフィルターに注意してください。これは通常、残りの述語としてスキャンにプッシュダウンされます。これがsql_variantを使用する理由です データ・タイプ;述語をプッシュすることを防ぎ、スキャンからの膨大な数の行をより見やすくします。
分析
不一致の理由は、オプティマイザーがフィルターで設定された1行の目標を達成するためにテーブルスキャンから読み取る必要がある行数をどのように推定するかにあります。単純な仮定は、値がテーブル内で均一に分散されていることです。したがって、存在する500の一意の値のうちの1つに遭遇するには、SQLServerは250,000/ 500=500行を読み取る必要があります。 500回を超える反復、つまり250,000行になります。
オプティマイザの均一性の仮定は一般的なものですが、ここではうまく機能しません。これについて詳しくは、JoeObbishによるARow Goal Requestをご覧ください。また、Connect交換フィードバックフォーラムのUse More Than Density to Cost a Scan on the Inner Side of the Nested LoopwithTOPで彼の提案に投票してください。
この特定の側面に関する私の見解は、演算子がネストされたループ結合の内側にいる場合(つまり、推定巻き戻しと再バインドが1より大きい場合)、オプティマイザーは単純な均一性の仮定からすぐに戻る必要があるということです。ループの最初の反復で一致するものを見つけるには、500行を読み取る必要があると想定することが1つあります。すべての反復でこれを想定することは、正確である可能性が非常に低いようです。これは、検出された最初の500行に、それぞれ異なる値の1つが含まれている必要があることを意味します。これが実際に当てはまる可能性はほとんどありません。
一連の不幸な出来事
繰り返されるトップオペレーターのコストに関係なく、私には、全体の状況をそもそも回避する必要があるように思われます。 。この計画のトップがどのように作成されたかを思い出してください:
- オプティマイザーは、パフォーマンスの最適化として内側の個別の集計を導入しました 。
- この集計は、定義上、結合列にキーを提供します(一意性を生成します)。
- この構築されたキーは、結合から適用への変換のターゲットを提供します。
- 適用に関連付けられた述語(選択)は、集約を超えてプッシュダウンされます。
- アグリゲートは、反復ごとに1つの異なる値で動作することが保証されています(相関値であるため)。
- 集計はトップ(1)に置き換えられます。
これらの変換はすべて個別に有効です。これらは、妥当な実行プランを検索するため、通常のオプティマイザー操作の一部です。残念ながら、ここでの結果は、オプティマイザーによって導入された投機的な集計が、関連する行の目標を持つトップ(1)に変換されることです。 。行の目標は、均一性の仮定に基づく不正確な原価計算につながり、次に、うまく機能する可能性が非常に低い計画の選択につながります。
さて、上記の変換シーケンスがなければ、適用された反結合がとにかく行ゴールを持つことに反対するかもしれません。反論は、オプティマイザが考慮しないというものです。 アンチジョインから適用への変換 LASJNtoApply にオプティマイザーが導入された集計を使用せずに、結合防止(行の目標を設定) バインドするものを支配します。さらに、(パート3で)反結合が(結合ではなく)適用としてコストベースの最適化に入った場合、再び行の目標がないことがわかりました。 。
つまり、最終計画の行の目標は完全に人為的なものであり、元のクエリ仕様には根拠がありません。トップと行の目標に関する問題は、このより基本的な側面の副作用です。
回避策
この問題には多くの解決策が考えられます。上記の最適化シーケンスのいずれかのステップを削除することで、オプティマイザーが大幅に(そして人為的に)コストを削減して、適用アンチジョインの実装を生成しないようにします。うまくいけば、この問題はSQLServerで後でではなく早く解決されるでしょう。
それまでの間、私のアドバイスは、アンチジョインアンチパターンに注意することです。適用アンチジョインの内側に、すべての実行時条件に対して常に効率的なアクセスパスがあることを確認してください。これが不可能な場合は、ヒントを使用するか、行の目標を無効にするか、プランガイドを使用するか、クエリストアプランを強制して結合防止クエリから安定したパフォーマンスを得る必要があります。
シリーズの概要
4回の記事で多くのことをカバーしたので、ここに概要を示します。
- パート1-行の目標の設定と特定
- クエリ構文は、行の目標の有無を決定しません。
- 行の目標は、目標が通常の見積もりよりも少ない場合にのみ設定されます。
- 物理トップ演算子(オプティマイザーによって導入されたものを含む)は、サブツリーに行ゴールを追加します。
-
FASTまたはSET ROWCOUNTステートメントは、計画のルートに行の目標を設定します。 - セミジョインとアンチジョイン5月 行の目標を追加します。
- SQL Server 2017 CU3は、showplan属性を追加します EstimateRowsWithoutRowGoal 行の目標の影響を受けるオペレーターの場合
- 行の目標情報は、文書化されていないトレースフラグ8607および8612によって明らかになります。
- パート2–セミジョイン
- T-SQLで直接半結合を表現することはできないため、間接構文を使用します。
IN、EXISTS、またはINTERSECT。 - これらの構文は、適用(相関結合)を含むツリーに解析されます。
- オプティマイザは、適用を通常の結合に変換しようとします(常に可能とは限りません)。
- ハッシュ、マージ、および通常のネストされたループの半結合は、行の目標を設定しません。
- セミジョインを適用すると、常に行の目標が設定されます。
- セミ結合の適用は、ネストされたループの外部参照を結合演算子にすることで認識できます。
- セミジョインの適用では、内側にトップ(1)演算子を使用しません。
- パート3–アンチジョイン
- また、applyに解析され、それを結合として書き直そうとします(常に可能とは限りません)。
- ハッシュ、マージ、および通常のネストされたループのアンチジョインは、行の目標を設定しません。
- アンチジョインを適用しても、必ずしも行の目標が設定されるとは限りません。
- アンチジョインを適用に変換するコストベースの最適化(CBO)ルールのみが行の目標を設定します。
- アンチジョインは、ジョインとしてCBOに入る必要があります(適用されません)。そうしないと、変換を適用するための結合が発生しません。
- CBOを結合として入力するには、CBO前のapplyからjoinへの書き換えが成功している必要があります。
- CBOは、有望な場合にのみ、アンチジョインをアプライに書き換えることを検討します。
- CBO以前の簡略化は、文書化されていないトレースフラグ8621で表示できます。
- パート4–アンチジョインアンチパターン
- オプティマイザは、有望な理由がある場合にのみ、アンチジョインを適用するための行の目標を設定します。
- 残念ながら、複数の相互作用するオプティマイザトランスフォームは、適用アンチジョインの内側にトップ(1)演算子を追加します。
- Top演算子は冗長です。正確性や効率性には必要ありません。
- トップは常に行の目標を設定します(適用とは異なり、正当な理由が必要です)。
- 不当な行の目標は、パフォーマンスを極端に低下させる可能性があります。
- 人工トップ(1)の下にある潜在的に高価なサブツリーに注意してください。