ギャップとアイランドのタスクは、欠落している値の範囲と既存の値の範囲をシーケンスで特定する必要がある、古典的なクエリの課題です。シーケンスは多くの場合、特定の日付、または日付と時刻の値に基づいており、通常は定期的に表示されますが、一部のエントリが欠落しています。ギャップタスクは欠落している期間を探し、アイランドタスクは既存の期間を探します。私は過去に私の本や記事でギャップや島のタスクに対する多くの解決策を取り上げました。最近、友人のアダム・マハニックから新しい特別な島への挑戦が提示されました。それを解決するには、少しの創造性が必要でした。この記事では、私が思いついた課題と解決策を紹介します。
課題
データベースでは、CompanyServicesというテーブルで会社がサポートするサービスを追跡します。各サービスは通常、1分に1回程度、EventLogというテーブルでオンラインであることを報告します。次のコードは、これらのテーブルを作成し、サンプルデータの小さなセットをそれらに入力します。
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
EventLogテーブルには、現在次のデータが入力されています。
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
特別なアイランドタスクは、可用性期間(サービス、開始時間、終了時間)を特定することです。 1つの落とし穴は、サービスが正確に毎分オンラインであると報告するという保証がないことです。たとえば、前のログエントリから最大66秒の間隔を許容し、それでも同じ可用性期間(アイランド)の一部であると見なす必要があります。 66秒を超えると、新しいログエントリが新しい可用性期間を開始します。したがって、上記の入力サンプルデータの場合、ソリューションは次の結果セットを返すことになっています(必ずしもこの順序である必要はありません)。
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00>
たとえば、前のログエントリからの間隔が120秒(> 66)であるため、ログエントリ5が新しいアイランドを開始する方法に注意してください。一方、前のエントリからの間隔が62秒(> 66)であるため、ログエントリ6は新しいアイランドを開始しません。 <=66)。もう1つの問題は、AdamがソリューションをSQL Server 2012より前の環境と互換性があることを望んでいたことです。これは、フレームでウィンドウ集計関数を使用して現在の合計とオフセットウィンドウ関数を計算できないため、非常に困難な課題です。 LAGやLEADのように、いつものように、自分の解決策を検討する前に、自分で課題を解決することをお勧めします。サンプルデータの小さなセットを使用して、ソリューションの有効性を確認します。次のコードを使用して、テーブルに大量のサンプルデータ(500サービス、ソリューションのパフォーマンスをテストするための最大1,000万のログエントリ)を入力します。
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; ソリューションのステップで提供する出力は、サンプルデータの小さなセットを想定しており、提供するパフォーマンスの数値は、大きなセットを想定しています。
ここで紹介するすべてのソリューションは、次のインデックスの恩恵を受けています。
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
頑張ってください!
SQLServer2012以降のソリューション1
SQL Server 2012より前の環境と互換性のあるソリューションについて説明する前に、SQLServer2012以上を必要とするソリューションについて説明します。これをソリューション1と呼びます。
ソリューションの最初のステップは、イベントが新しいアイランドを開始しない場合は0、それ以外の場合は1であるisstartというフラグを計算することです。これは、LAG関数を使用して前のイベントのログ時間を取得し、前のイベントと現在のイベントの間の秒単位の時間差が許容ギャップ以下であるかどうかを確認することで実現できます。この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog;> このコードは次の出力を生成します:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
次に、isstartフラグの単純な現在の合計により、アイランド識別子が生成されます(これをgrpと呼びます)。この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; このコードは次の出力を生成します:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
最後に、サービスIDとアイランド識別子で行をグループ化し、各アイランドの開始時刻と終了時刻として最小ログ時間と最大ログ時間を返します。完全なソリューションは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; このソリューションは、私のシステムで完了するのに41秒かかり、図1に示す計画を作成しました。
 図1:ソリューション1の計画
図1:ソリューション1の計画
ご覧のとおり、両方のウィンドウ関数は、明示的な並べ替えを必要とせずに、インデックスの順序に基づいて計算されます。
SQL Server 2016以降を使用している場合は、ここで説明するトリックを使用して、次のように空のフィルター処理された列ストアインデックスを作成することにより、バッチモードのウィンドウ集計演算子を有効にできます。
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
同じソリューションが私のシステムで完了するのに5秒しかかからず、図2に示す計画が作成されます。
 図2:バッチモードのウィンドウ集計演算子を使用したソリューション1の計画>
図2:バッチモードのウィンドウ集計演算子を使用したソリューション1の計画>
これはすべて素晴らしいことですが、前述のように、Adamは2012年以前の環境で実行できるソリューションを探していました。
続行する前に、クリーンアップのために列ストアインデックスを削除してください:
DROP INDEX idx_cs ON dbo.EventLog;
SQLServer2012より前の環境向けのソリューション2
残念ながら、SQL Server 2012より前は、LAGのようなオフセットウィンドウ関数はサポートされていませんでした。また、フレームを使用したウィンドウ集計関数を使用した積算合計の計算もサポートされていませんでした。これは、合理的な解決策を考え出すために、もっと一生懸命働く必要があることを意味します。
私が使用したトリックは、各ログエントリを、開始時刻がエントリのログ時刻であり、終了時刻がエントリのログ時刻に許容ギャップを加えたものである人工的な間隔に変換することです。その後、タスクを従来のインターバルパッキングタスクとして扱うことができます。
ソリューションの最初のステップでは、人工的な間隔区切り文字と、各イベントの種類(カウント)の位置を示す行番号を計算します。この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
このコードは次の出力を生成します:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
次のステップは、間隔を、それぞれイベントタイプ「s」および「e」として識別される開始イベントと終了イベントの時系列にアンピボットすることです。文字sとeの選択が重要であることに注意してください('s' > 'e' )。このステップでは、両方のイベントの種類の正しい時系列順を示す行番号を計算します。これらのイベントの種類は、現在インターリーブされています(両方ともカウントされます)。ある間隔が別の間隔の開始位置で正確に終了する場合は、開始イベントを終了イベントの前に配置することで、それらをまとめます。この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; このコードは次の出力を生成します:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
前述のように、counteachは同じ種類のイベントのみの中でイベントの位置をマークし、countbothは両方の種類のイベントを組み合わせたインターリーブの中でイベントの位置をマークします。
次に、魔法は次のステップで処理されます。つまり、counteachとcountbothの両方に基づいて、すべてのイベントの後にアクティブな間隔のカウントを計算します。アクティブな間隔の数は、これまでに発生した開始イベントの数から、これまでに発生した終了イベントの数を引いたものです。開始イベントの場合、counteachは、これまでに発生した開始イベントの数を示します。countbothからcounteachを引くことにより、これまでに終了したイベントの数を把握できます。したがって、アクティブな間隔の数を示す完全な式は次のようになります。
counteach - (countboth - counteach)
終了イベントの場合、counteachは、これまでに発生した終了イベントの数を示します。countbothからcounteachを引くことにより、これまでに開始されたイベントの数を把握できます。したがって、アクティブな間隔の数を示す完全な式は次のようになります。
(countboth - counteach) - counteach
次のCASE式を使用して、イベントタイプに基づいてcountactive列を計算します。
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END 同じ手順で、パックされた間隔の開始と終了を表すイベントのみをフィルタリングします。パックされた間隔の開始にはタイプ「s」とカウントアクティブ1があります。パックされた間隔の終了にはタイプ「e」とカウントアクティブ0があります。
フィルタリング後、パックされた間隔の開始-終了イベントのペアが残りますが、各ペアは2つの行に分割されます。1つは開始イベント用で、もう1つは終了イベント用です。したがって、同じ手順で、式(rownum – 1)/ 2+1を使用して行番号を使用してペア識別子を計算します。
この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); このコードは次の出力を生成します:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
最後のステップでは、イベントのペアを間隔ごとに1行にピボットし、終了時間から許容ギャップを差し引いて、正しいイベント時間を再生成します。完全なソリューションのコードは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; このソリューションは、私のシステムで完了するのに43秒かかり、図3に示す計画を生成しました。
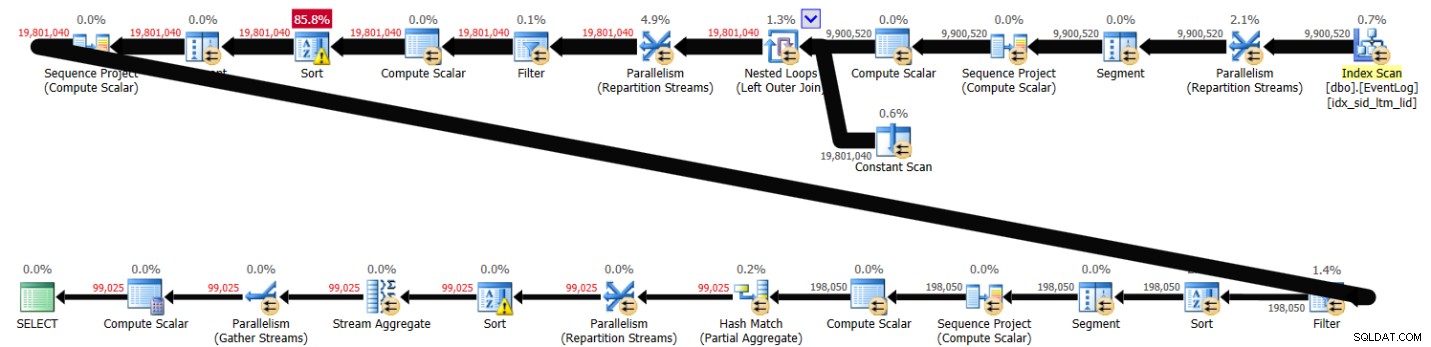 図3:ソリューション2の計画
図3:ソリューション2の計画
ご覧のとおり、最初の行番号の計算はインデックスの順序に基づいて計算されますが、次の2つには明示的な並べ替えが含まれます。それでも、約10,000,000行が含まれていることを考えると、パフォーマンスはそれほど悪くありません。
このソリューションのポイントはSQLServer2012より前の環境を使用することですが、楽しみのために、フィルター処理された列ストアインデックスを作成した後、そのパフォーマンスをテストして、バッチ処理を有効にした場合の動作を確認しました。
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
バッチ処理を有効にすると、このソリューションはシステムで完了するのに29秒かかり、図4に示す計画が作成されました。
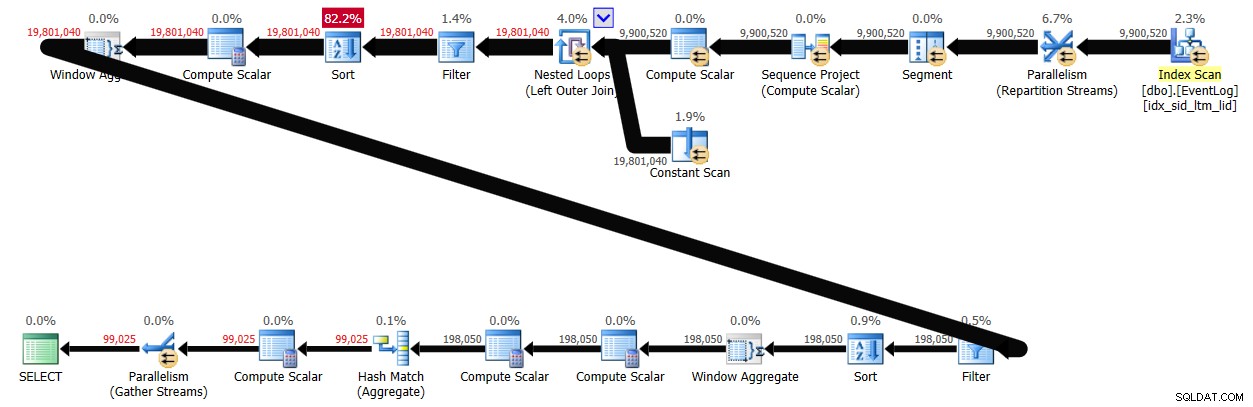
結論
環境が制限されているほど、クエリタスクの解決が難しくなるのは当然です。 Adamの特別なIslandsの課題は、古いバージョンよりも新しいバージョンのSQLServerで解決する方がはるかに簡単です。しかし、その後、より創造的な手法を使用するように強制します。したがって、演習として、クエリスキルを向上させるために、すでに慣れ親しんでいる課題に取り組むことができますが、意図的に特定の制限を課すことができます。どんな面白いアイデアに出くわすかわからない!