パフォーマンススプール 内側の推定コストを削減するためにオプティマイザーによって追加された遅延スプールです。 ネストされたループの結合 。 3種類あります:レイジーテーブルスプール 、レイジーインデックススプール 、および Lazy Row Count Spool 。怠惰なテーブルパフォーマンススプールを示す平面形状の例を以下に示します。
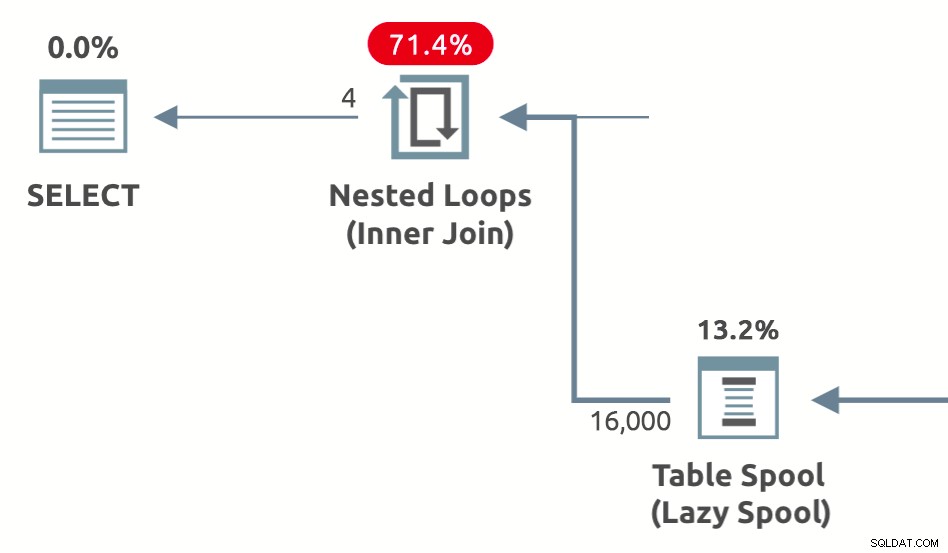
この記事で答えるために設定した質問は、クエリオプティマイザが各タイプのパフォーマンススプールを導入する理由、方法、および時期です。
始める直前に、重要な点を強調したいと思います。実行プランには、ネストされたループ結合には2つの異なるタイプがあります。 外部参照で品種を参照します 適用として 、およびjoin述語を持つタイプ ネストされたループの結合として結合演算子自体に 。明確にするために、この違いは実行プランオペレーターに関するものです。 、T-SQLクエリ構文ではありません。詳細については、リンク先の記事をご覧ください。
下の写真は、パフォーマンススプールを示しています。 プランエクスプローラー(上の行)とSSMS 18.3(下の行)に表示される実行プランオペレーター:
すべてのパフォーマンススプール 怠惰な 。行がスプールを流れるにつれて、スプールの作業テーブルは一度に1行ずつ徐々に移入されます。 (対照的に、熱心なスプールは、行を親に返す前に、子オペレーターからのすべての入力を消費します。)
パフォーマンススプールは常に内側に表示されます ネストされたループの(グラフィカル実行プランの下位入力)joinまたはapply演算子。一般的な考え方は、結果をキャッシュして再生し、可能な限り内部演算子の繰り返し実行を保存することです。
スプールがキャッシュされた結果を再生できる場合、これは巻き戻しと呼ばれます。 。スプールが正しいデータを取得するために子演算子を実行する必要がある場合、再バインド 発生します。
スプールの再バインドについて考えると役立つ場合があります キャッシュミスとして、および巻き戻し キャッシュヒットとして。
このタイプのパフォーマンススプールは、両方の apply で使用できます。 およびネストされたループが参加します 。
適用
再バインド (キャッシュミス)外部参照が発生するたびに発生します 値が変わります。遅延テーブルスプールは、切り捨てによって再バインドされます その作業台とその子オペレーターから完全に再作成します。
巻き戻し (キャッシュヒット)は、内側が同じで実行されたときに発生します。 直前としての外部参照値 ループの反復。巻き戻しは、スプールの作業テーブルからキャッシュされた結果を再生し、スプールの下でプランオペレーターを再実行するコストを節約します。
注:遅延テーブルスプールは、1セットの applyの結果のみをキャッシュします。 外部参照 一度に値。
ネストされたループが参加します
レイジーテーブルスプールは、最初のループ反復中に1回入力されます。スプールは、結合が繰り返されるたびに内容を巻き戻します。ネストされたループの結合では、結合述語が結合自体にあるため、結合の内側は静的な行のセットになります。したがって、静的な内側の行セットをキャッシュして、スプールを介して複数回再利用できます。ネストされたループがパフォーマンススプールに参加し、再バインドされることはありません。
行数スプールは、テーブルスプールにすぎません。 列なし。行の存在をキャッシュしますが、列データは投影しません。その存在に注目し、できると言及することは別として ソースクエリのエラーを示しているので、行数スプールについてこれ以上言うことはありません。
これ以降、テキストに「テーブルスプール」と表示されている場合は、非常に類似しているため、「テーブル(または行数)スプール」と読んでください。
レイジーインデックススプール 演算子は適用時にのみ使用可能です 。
インデックススプールは、切り捨てられないワークテーブルを維持します 外部参照の場合 値が変わります。代わりに、新しいデータが既存のキャッシュに追加され、外部参照値によってインデックスが付けられます。レイジーインデックススプールは、 any の結果を再生できるという点で、レイジーテーブルスプールとは異なります。 最新のものだけでなく、以前のループ反復。
パフォーマンススプールが実行計画にいつ表示されるかを理解するための次のステップでは、オプティマイザーがどのように機能するかについて少し理解する必要があります。
ソースクエリは、解析、代数化、単純化、および正規化によって論理ツリー表現に変換されます。結果のツリーが簡単な計画の対象とならない場合、コストベースのオプティマイザは、同じ結果を生成することが保証されているが、推定コストが低い論理的な代替案を探します。
オプティマイザが潜在的な代替案を生成すると、適切な物理演算子を使用してそれぞれを実装し、推定コストを計算します。最終的な実行計画は、各オペレーターグループで見つかった最低コストのオプションから作成されます。プロセスの詳細については、クエリオプティマイザーディープダイブシリーズをご覧ください。
パフォーマンススプールがオプティマイザの最終計画に表示されるために必要な一般的な条件は次のとおりです。
- オプティマイザは探索する必要があります 論理スプールを含む論理代替 生成された代替で。これは思ったよりも複雑なので、次のメインセクションで詳細を解凍します。
- 論理スプールは実装可能である必要があります 物理スプールとして 実行エンジンの演算子。 SQL Serverの最新バージョンの場合、これは基本的に、インデックススプール内のすべてのキー列が比較可能でなければならないことを意味します。 タイプ、合計900バイト*以下、64キー列以下。
- 最高 コストベースの最適化後の完全な計画には、代替スプールの1つを含める必要があります。言い換えれば、スプールオプションと非スプールオプションの間で行われたコストベースの選択は、スプールを優先して行われる必要があります。
*この値はSQLServerにハードコードされており、非クラスター化で1700バイトに増加しても変更されていません。 SQLServer2016以降のインデックスキー。これは、スプールインデックスがクラスター化されているためです。 非クラスター化インデックスではなく、インデックス。
T-SQLを使用してスプールを指定することはできないため、実行プランでスプールを取得することは、オプティマイザーがスプールを追加することを選択する必要があることを意味します。最初のステップとして、これは、オプティマイザが探索することを選択した選択肢の1つに論理スプールを含める必要があることを意味します。
オプティマイザは、知っているすべての論理等価規則をすべてのクエリツリーに完全に適用するわけではありません。合理的な計画を迅速に作成するというオプティマイザーの目標を考えると、これは無駄になります。これには複数の側面があります。まず、オプティマイザは段階的に進行し、より安価でより頻繁に適用可能なルールが最初に試行されます。妥当な計画が初期段階で見つかった場合、またはクエリが後の段階に適格でない場合、最適化の取り組みは、これまでに見つかった最低コストの計画で早期に終了する可能性があります。この戦略は、段階的なコスト改善によって節約されるよりも最適化に多くの時間を費やすことを防ぐのに役立ちます。
クエリツリーの各論理演算子は、現在の最適化段階で使用可能なルールとのパターン一致がないかすぐにチェックされます。たとえば、各ルールは論理演算子のサブセットにのみ一致し、ソートされた入力の保証など、特定のプロパティを設定する必要がある場合もあります。ルールは、個々の論理操作(単一のグループ)または複数の連続するグループ(計画のサブセクション)に一致する場合があります。
一致すると、候補ルールは約束値を生成するように求められます 。これは、ローカルコンテキストを前提として、現在のルールが有用な結果を生成する可能性を表す数値です。たとえば、ターゲットの入力に多数の重複がある場合、推定行数が多い場合、ソートされた入力が保証されている場合、またはその他の望ましいプロパティがある場合、ルールはより高いpromise値を生成する可能性があります。
有望な探索ルールが特定されると、オプティマイザーはそれらを約束値の順序に並べ替え、新しい論理代替を生成するように要求し始めます。各ルールは、後で物理演算子を使用して実装される1つ以上の代替を生成する場合があります。そのプロセスの一環として、推定コストが計算されます。
パフォーマンススプールに適用されるこのすべてのポイントは、論理プランの形状とプロパティがスプール対応ルールの一致に役立つ必要があり、ローカルコンテキストは、オプティマイザーがルールを使用して代替を生成することを選択するのに十分高いpromise値を生成する必要があることです。 。
論理的なネストされたループの結合を調査するルールがいくつかあります。 または適用 代替案。これらのルールの一部は、特定のタイプのパフォーマンススプールで1つ以上の代替を生成できます。ネストされたループの結合または適用に一致する他のルールは、スプールの代替を生成しません。
たとえば、ルールApplyToNL 論理的な適用を実装します 物理ループが外部参照と結合するため。このルールは、いくつかの選択肢を生成する可能性があります 実行するたびに。物理結合演算子に加えて、各置換には、レイジーテーブルスプール、レイジーインデックススプール、またはスプールがまったく含まれていない場合があります。論理スプールの代替は、後で個別に実装され、BuildSpoolと呼ばれる別のルールによって、適切に型指定された物理スプールとしてコストがかかります。 。
2番目の例として、ルールJNtoIdxLookup 論理結合を物理的な適用として実装します 、すぐ内側にインデックスシークがあります。このルールは決してありません スプールコンポーネントで代替を生成します。 JNtoIdxLookup は早期に評価され、一致すると高いpromise値を返すため、単純なインデックス検索プランがすばやく見つかります。
オプティマイザがこのような低コストの代替案を早い段階で見つけた場合、より複雑な代替案が積極的に排除されるか、完全にスキップされる可能性があります。その理由は、すでに見つかった低コストの代替案で改善される可能性が低いオプションを追求することは意味がないということです。同様に、現在の最良の完全な計画の総コストがすでに十分に低い場合は、さらに調査する価値はありません。
3番目のルールの例:ルールJNtoNL ApplyToNLに似ています 、ただし、物理的なネストされたループ結合のみを実装します。 、遅延テーブルスプールがあるか、スプールがまったくない。このルールは決してありません そのタイプのスプールには適用が必要なため、インデックススプールを生成します。
対応のルール 論理スプールを生成することは、それが呼び出されるたびに必ずしもそうなるとは限りません。最も安価なものとして選ばれる可能性がほとんどない論理的な代替案を作成するのは無駄です。また、新しい代替案を生成するためのコストもあります。これにより、さらに多くの代替案が生成される可能性があります。それぞれに実装とコストが必要になる場合があります。
これを管理するために、オプティマイザーはすべてのスプール対応ルールに共通のロジックを実装して、ローカルプランの条件に基づいて生成する代替スプールのタイプを決定します。
ネストされたループの結合 、レイジーテーブルスプールを取得するチャンス 次のように増加します:
- 推定行数 結合の外部入力。
- 推定費用 内側の計画演算子の。
スプールのコストは、内部のオペレーターの実行を回避することで節約できることによって返済されます。内部反復が多くなり、内部コストが高くなると、節約が増加します。コストモデルでは、テーブルスプールの巻き戻し(キャッシュヒット)に比較的低いI / OおよびCPUコストの数値が割り当てられるため、これは特に当てはまります。パラメータがないということは内部データセットが静的であることを意味するため、ネストされたループ結合のテーブルスプールでは巻き戻しが発生するだけであることに注意してください。
スプールはデータをより密に保存する場合があります それを供給するオペレーターより。たとえば、ベーステーブルのクラスター化インデックスは、平均して1ページあたり100行を格納する場合があります。クエリに必要なのは、各ワイドクラスター化インデックス行からの単一の整数列値のみであるとします。スプール作業テーブルに整数値だけを格納するということは、1ページに800をはるかに超えるそのような行を格納できることを意味します。オプティマイザは、ワークテーブルページの数の見積もりを使用してテーブルスプールのコストを部分的に評価するため、これは重要です。 必要です。その他のコスト要因には、ループの反復の推定回数に対する、スプールの書き込みと読み取りに関連する行ごとのCPUコストが含まれます。
オプティマイザは、ネストされたループ結合の内側にレイジーテーブルスプールを追加するには、おそらく少し熱心すぎます。それでも、オプティマイザーの決定は、推定コストの観点からは常に理にかなっています。私は個人的にネストされたループの結合を高リスクと見なしています 、どちらかの結合入力カーディナリティの推定値が低すぎると、すぐに遅くなる可能性があるためです。
テーブルスプールmay コストを削減するのに役立ちますが、単純なネストされたループ結合の最悪の場合のパフォーマンスを完全に隠すことはできません。通常、インデックス付きの適用結合が望ましく、推定エラーに対してより耐性があります。オプティマイザーが必要に応じてハッシュまたはマージ結合を使用して実装できるクエリを作成することもお勧めします。
適用の場合 、レイジーテーブルスプールを取得する可能性 重複の推定数とともに増加します 適用の外部入力でキー値を結合します。重複が増えると、統計的に スプールが各反復で現在保存されている結果を巻き戻す可能性が高くなります。推定コストが低いレイジーテーブルスプールを適用すると、最終的な実行プランに登場する可能性が高くなります。
適用外部入力に到着する行に特定の順序がない場合、オプティマイザーは統計的評価を行います。 各反復が安価な巻き戻しまたは高価な再バインドをもたらす可能性がどの程度あるかを示します。この評価では、可能な場合はヒストグラムのステップからのデータを使用しますが、この最良のシナリオでさえ、より知識に基づいた推測です。保証がない場合、適用外部入力に到達する行の順序は予測できません。
論理スプールの代替を生成するのと同じオプティマイザルールが 適用演算子が必要であることを指定します 並べ替えられた行 その外側の入力に。これにより、遅延スプールが最大化されます巻き戻し すべての重複がブロック内で検出されることが保証されているためです。保存された順序または明示的な並べ替えのいずれかによって、外部入力の並べ替え順序が保証されている場合 、スプールのコストが大幅に削減されます。オプティマイザーは、スプールの巻き戻しと再バインドの数に対するソート順の影響を考慮に入れています。
並べ替えを使用したプラン 適用外部入力、およびレイジーテーブルスプール 内部入力では非常に一般的です。外側の並べ替えの最適化は、逆効果になる可能性があります。たとえば、これは、外側のカーディナリティの推定値が非常に低く、ソートが tempdbに流出する場合に発生する可能性があります。 。
適用の場合 、レイジーインデックススプールを取得する 代替案は、計画の形状と原価計算によって異なります。
オプティマイザには以下が必要です:
- 一部の重複 外部入力の値を結合します。
- 平等 結合述語(または
x <= y AND x >= yなどのオプティマイザーが理解する論理的等価物) 。 - 保証 外側の参照が一意であること 提案されたレイジーインデックススプールの下。
実行計画では、必要な一意性は、多くの場合、外部参照による集計グループ化、またはスカラー集計(group byのないもの)によって提供されます。一意性は、他の方法でも提供される場合があります。たとえば、一意のインデックスや制約が存在する場合などです。
平面図を示すおもちゃの例を以下に示します。
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
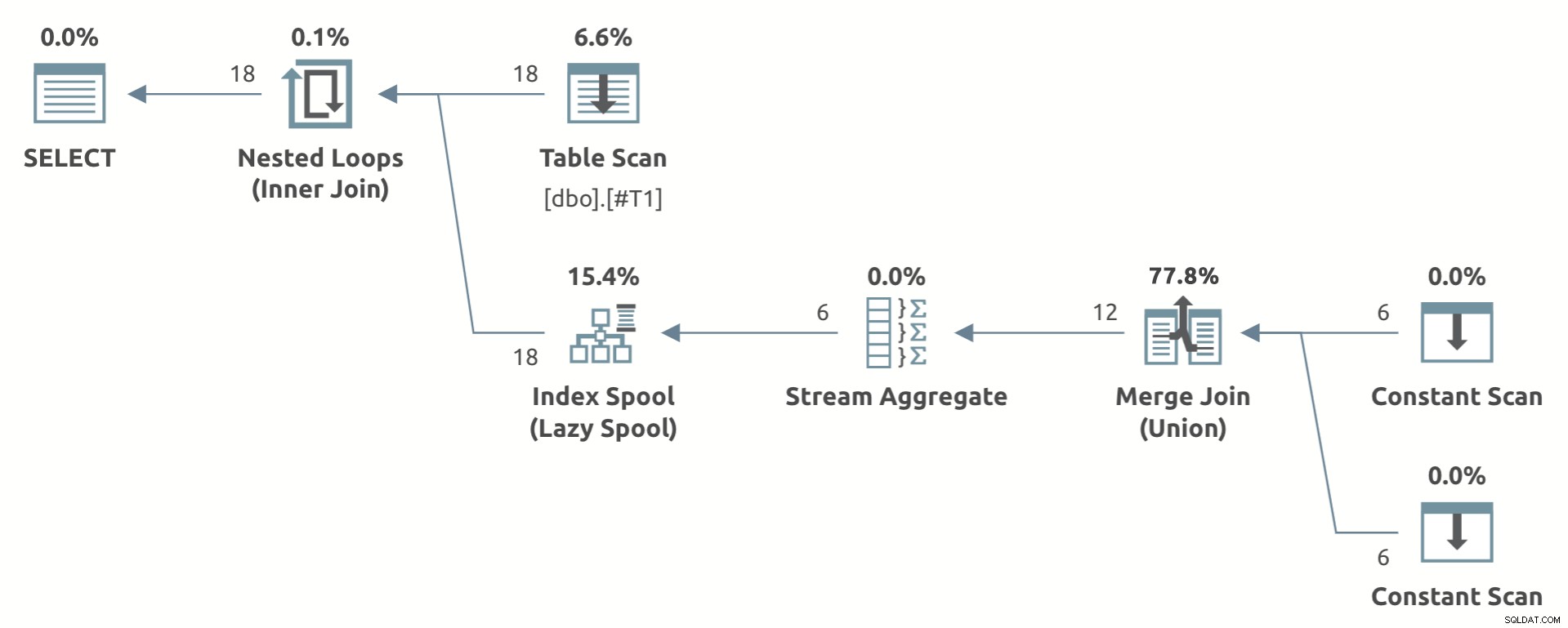
Stream Aggregateに注目してください レイジーインデックススプールの下 。
平面形状の要件が満たされている場合、オプティマイザーはレイジーインデックスの代替案を生成することがよくあります(前述の注意事項があります)。最終計画にレイジーインデックススプールが含まれるかどうかは、コストに依存します。
推定される巻き戻しの数 および再バインド 怠惰なインデックススプールの場合は同じです 怠惰なテーブルスプールについてはなし ソートされた外部入力を適用します。
これはかなり不幸な状況のように思えるかもしれません。インデックススプールの主な利点は、以前に表示されたすべての結果をキャッシュすることです。これにより、インデックススプールが巻き戻されるようになります。 同じ状況では、テーブルスプール(外部入力ソートなし)よりも可能性が高くなります。私の理解では、この癖がないと、オプティマイザーがインデックススプールを頻繁に選択するため、この癖が存在します。
とにかく、コストモデルは、インデックススプールとテーブルスプールに異なる初期行と後続行のI / OおよびCPUコスト数を使用することにより、上記をある程度調整します。正味の効果は、インデックススプールは通常、外部入力がソートされていないテーブルスプールよりもコストが低いことですが、レイジーインデックススプールを比較的にする制限的なプラン形状要件を覚えておいてください。 まれです。
それでも、レイジースプールインデックスの主なコスト競争相手は、withのテーブルスプールです。 ソートされた外部入力。これに対する直感はかなり単純です。ソートされた外部入力は、テーブルスプールがすべての重複する外部参照を順番に表示することが保証されていることを意味します。これは、再バインドすることを意味します 個別の値ごとに1回だけ、巻き戻し すべての重複に対して。これは、インデックススプールの予想される動作と同じです(少なくとも論理的に言えば)。
実際には、重複する適用キー値が少ないため、ソートが最適化されたテーブルスプールよりもインデックススプールが優先される可能性が高くなります。重複するキーが少ないほど、巻き戻しが減少します 前述の「不幸な」インデックススプールの見積もりと比較した、ソートが最適化されたテーブルスプールの利点。
インデックススプールオプションは、テーブルスプールの外側の推定コストとしてもメリットがあります並べ替え 増加します。これはほとんどの場合、計画のその時点でより多くの(またはより広い)行に関連付けられます。
-
パフォーマンススプールは無効にすることができます わずかに文書化されたトレースフラグ8690 、または文書化されたクエリヒント
NO_PERFORMANCE_SPOOLSQLServer2016以降。 -
文書化されていないトレースフラグ8691 (テストシステムで)常にパフォーマンススプールを追加するために使用できます 可能であれば。 タイプ 取得したレイジースプール(行数、テーブル、またはインデックス)を強制することはできません。それでもコスト見積もりに依存します。
-
文書化されていないトレースフラグ2363 新しいカーディナリティ推定モデルとともに使用して、個別の推定の導出を確認できます。 適用への外部入力、および一般的なカーディナリティ推定について。
-
文書化されていないトレースフラグ9198 レイジーインデックスパフォーマンススプールを無効にするために使用できます 具体的には。コストに応じて、代わりに(ソートの最適化の有無にかかわらず)レイジーテーブルまたは行カウントスプールを取得する場合があります。
-
文書化されていないトレースフラグ2387 CPUコストの削減に使用できます レイジーインデックススプールから行を読み取る 。このフラグは、bツリーから行の範囲を読み取るための一般的なCPUコストの見積もりに影響します。このフラグは、コスト上の理由から、インデックススプールを選択する可能性が高くなる傾向があります。
クエリのコンパイル中にアクティブ化されたオプティマイザルールを判別するための他のトレースフラグとメソッドは、私のクエリオプティマイザディープダイブシリーズにあります。
最終的な実行プランがパフォーマンススプールを使用するかどうかに影響を与える内部の詳細は非常に多くあります。私は、スプールオペレーターの原価計算式の非常に複雑な詳細に深く踏み込むことなく、この記事の主な考慮事項をカバーしようとしました。うまくいけば、実行プラン内の特定のパフォーマンススプールタイプ(またはその欠如)の考えられる理由を判断するのに役立つ十分な一般的なアドバイスがここにあります。
パフォーマンススプールはしばしば悪いラップを取得します、私は言うのは公正だと思います。これのいくつかは間違いなく値する。多くの人は、「パフォーマンススプール」がない場合よりもプランが速く実行されるデモを見たことがあるでしょう。ある程度、それは予想外ではありません。エッジケースが存在し、原価計算モデルは完全ではありません。デモでは、カーディナリティの見積もりが不十分なプランや、オプティマイザを制限するその他の問題が取り上げられることがよくあります。
とは言うものの、ネストされたループ結合にレイジーテーブルスプールを追加する(またはサポートする内部インデックスを使用せずに適用する)場合に、SQLServerが何らかの警告やその他のフィードバックを提供することを望む場合があります。本体で述べたように、これらは、カーディナリティの推定値がひどく低いことが判明したときに、私が最も頻繁にひどく間違っていると感じる状況です。
おそらくいつの日か、クエリオプティマイザは、リスクの概念を考慮して選択を計画したり、より「適応性のある」機能を提供したりするでしょう。それまでの間、ネストされたループの結合を有用なインデックスでサポートし、可能な場合はネストされたループを使用してのみ実装できるクエリの記述を回避することにはメリットがあります。もちろん一般化していますが、オプティマイザーは、より多くの選択肢、適切なスキーマ、優れたメタデータ、および操作可能な管理可能なT-SQLステートメントがある場合に、より適切に機能する傾向があります。私もそうですが、考えてみてください。
非パフォーマンススプールは、SQLServer内で次のような多くの目的で使用されます。
- ハロウィーンの保護
- 一部の行モードウィンドウ関数
- 複数の集計の計算
- データを変更するステートメントの最適化