はじめに
かなり今、あなたのマッチング条件は広すぎるかもしれません。ただし、レーベンシュタイン距離を使用して単語を確認することはできます。音の類似性など、必要なすべての目標を達成するのは簡単ではないかもしれません。したがって、私はあなたの問題を他のいくつかの問題に分割することを提案しています。
たとえば、2つの文字列を受け取り、それらが同じであるかどうかについての質問に答える、渡された呼び出し可能入力を使用するカスタムチェッカーを作成できます(levenshteinの場合) similar_textの場合、これはある値よりも距離が短くなります -類似性の数パーセントet.c. -ルールを定義するのはあなた次第です。
類似性、単語に基づく
部分一致を探している場合、特に順序付けされていない一致の場合は、組み込み関数のすべてが失敗します。したがって、より複雑な比較ツールを作成する必要があります。あなたが持っている:
- データ文字列(たとえば、DBにあります)。 D =D 0のように見えます D 1 D 2 ... D n
- 検索文字列(ユーザー入力になります)。 S =S 0のように見えます S 1 ... S m
ここで、スペースシンボルは、任意のスペースを意味します(スペースシンボルは類似性に影響を与えないと思います)。また、n > m 。この定義では、あなたの問題は-mのセットを見つけることです Dの単語 これはSに似ています 。 setによる 順序付けられていないシーケンスを意味します。したがって、そのようなシーケンスが見つかった場合 Dで 、次にS Dに似ています 。
明らかに、n < mの場合 その場合、入力にはデータ文字列よりも多くの単語が含まれます。この場合、それらは類似していないか、上記のように動作すると思うかもしれませんが、データと入力を切り替えます(ただし、少し奇妙に見えますが、ある意味で適用可能です)
実装
これを行うには、mの一部である文字列のセットを作成できる必要があります。 Dからの単語 。私の
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-したがって、任意の配列の場合、getAssoc() mで構成される順序付けられていない選択の配列を返します それぞれのアイテム。
次のステップは、生産された選択の順序についてです。両方のNiels Andersenを検索する必要があります およびAndersen Niels Dで ストリング。したがって、配列の順列を作成できる必要があります。これは非常に一般的な問題ですが、自分のバージョンもここに配置します:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
この後、mの選択を作成できるようになります 次に、単語を並べ替えて、検索文字列Sと比較するためにすべてのバリアントを取得します。 。その毎回の比較は、levenshteinなどのコールバックを介して行われます。 。サンプルは次のとおりです:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
これにより、ユーザーのコールバックに基づいて類似性がチェックされます。ユーザーのコールバックは、少なくとも2つのパラメーター(つまり、比較された文字列)を受け入れる必要があります。また、コールバックの正の戻りをトリガーした文字列を返したい場合もあります。このコードは大文字と小文字の違いはないことに注意してください。ただし、そのような動作は望ましくない場合があります(strtolower()を置き換えるだけです。 。
完全なコードのサンプルは、このリスト で入手できます。 (コードリストが利用できる期間がわからないため、サンドボックスは使用しませんでした)。この使用例:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
次のような結果が得られます:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-こちら 念のため、このコードのデモです。
複雑さ
メソッドだけでなく、それがどれほど優れているかについても気にかけているので、そのようなコードは非常に過剰な操作を生成することに気付くかもしれません。つまり、少なくとも、ストリングパーツの生成です。ここでの複雑さは2つの部分で構成されています:
- 文字列パーツ生成パーツ。すべての文字列部分を生成する場合は、上記で説明したようにこれを行う必要があります。改善の可能性のあるポイント-順序付けされていない文字列セットの生成(順列の前に来る)。しかし、提供されたコードのメソッドが「ブルートフォース」ではなく、数学的に計算されたもの(カーディナリティ
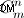 )
) - 類似性チェック部分。ここであなたの複雑さは与えられた類似性チェッカーに依存します。たとえば、
similar_text()O(N)の複雑さがあるため、比較セットが大きいと非常に遅くなります。
ただし、オンザフライでチェックすることで、現在のソリューションを改善できる場合があります。これで、このコードは最初にすべての文字列サブシーケンスを生成し、次にそれらを1つずつチェックし始めます。通常、これを行う必要はないので、次のシーケンスを生成した後すぐにチェックされるときに、動作に置き換えることができます。次に、正解のある文字列のパフォーマンスを向上させます(ただし、一致しない文字列のパフォーマンスは向上しません)。