SQL Serverのすべてのテーブルのすべてのインデックスを再構築する方法はいくつかありますが、その中には次のものがあります。
- SQLServerメンテナンスプランの使用。
- 断片化率に基づくT-SQLスクリプトの使用。
- ALTERINDEXコマンドの使用。
この記事では、これらの方法を検討し、実際の例を使用して説明します。
1。 SQLServer再構築インデックスメンテナンスプラン
確認する最初のオプションは、データベース保守計画を使用して索引を再構築することです。メンテナンスプランは、SQL ServerManagementStudioの管理フォルダーから入手できます。
SQLデータベースのメンテナンスプランを作成するには、 SQL Server Management Studioを起動します >データベースインスタンスを拡張します >管理 >メンテナンスプランを右クリック >新しいメンテナンスプラン 。
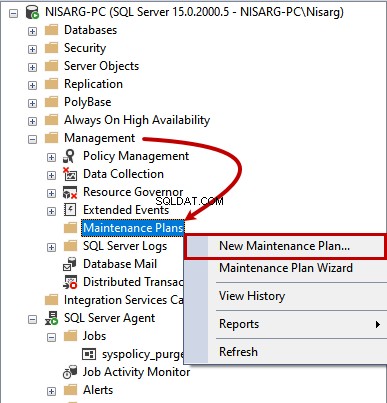
保守計画の名前を指定してください。次に、インデックスの再構築タスクをドラッグアンドドロップします メンテナンスプランの設計者に。タスクの名前をインデックスのメンテナンスに変更します 。
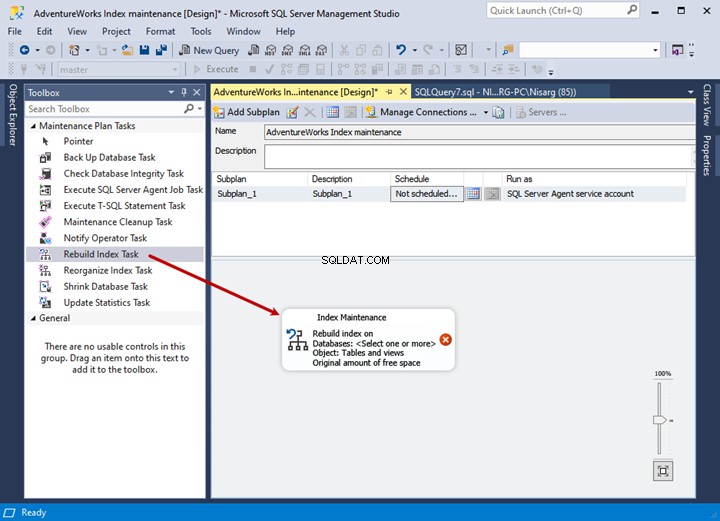
次のステップは、メンテナンスプランの構成です。それをダブルクリックして、インデックスの再構築タスクのオプションを構成します 次のように:
- AdventureWorks2017を選択します [データベース]ドロップダウンメニューからのデータベース。
- すべてのテーブルのインデックスを再構築するには、テーブルとビューを選択します オブジェクトから ドロップダウンボックス。
- 結果をtempdbに並べ替えるを確認します 。
- MAXDOP – 2を設定します (2つ)。
- この場合、フラグメンテーションの場合にのみインデックスを再構築します 値が20%を超えています。したがって、 20を設定します それぞれの分野で。
- [ OK]をクリックします インデックス構成を保存して、インデックスの再構築タスクを閉じます。 ウィンドウ。
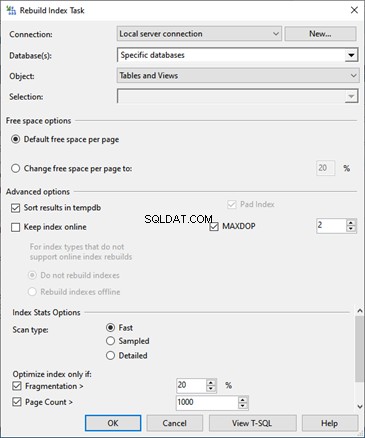
それでは、スケジュールを設定しましょう。
カレンダーをクリックします メンテナンスプランデザイナーの上部にあるアイコン:
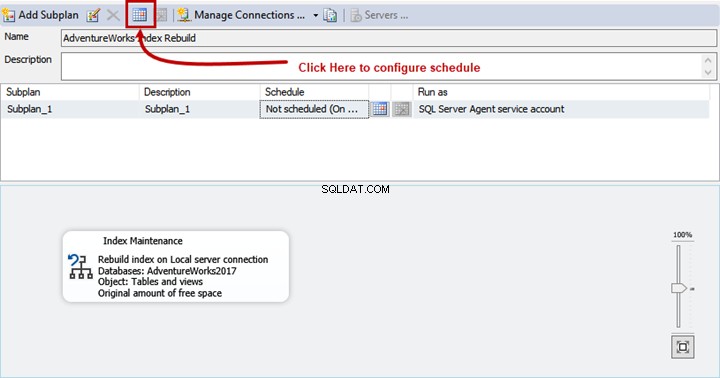
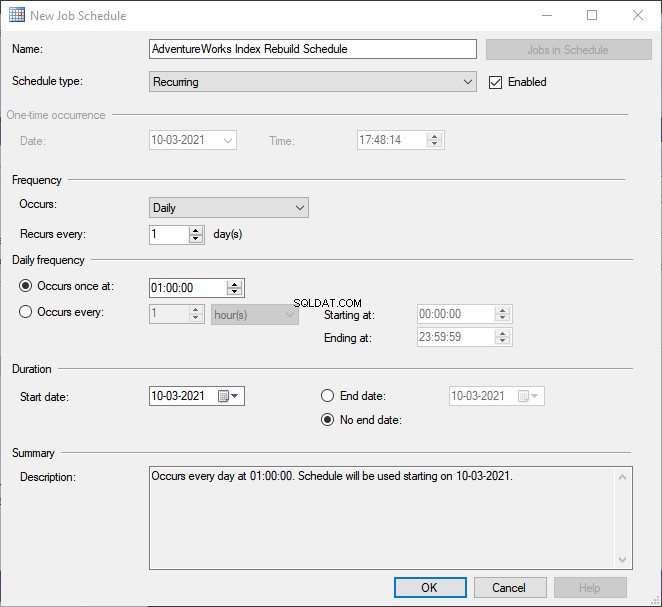
新しいジョブスケジュール ウィンドウが開きます。次の設定を構成しましょう:
- 毎日ジョブを実行します。 スケジュールタイプ メニューで、 Recurring を選択します 。次に、頻度で セクションでは、発生を選択します >毎日 。
- 毎回繰り返される > 1(日)。
- 毎日の頻度 >で1回発生 >正確な時刻を指定します。私たちの場合は午前1時です。
- OKをクリックします 。
その後、メンテナンスプランを保存します。
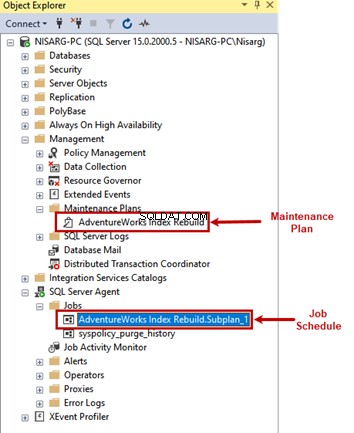
作成されたメンテナンスプランは、SSMSメンテナンスプランで利用できます。 ディレクトリ。特定のメンテナンスプランに関連するスケジュールを表示するには、ジョブを確認してください。 SQLServerエージェントの下のディレクトリ 。
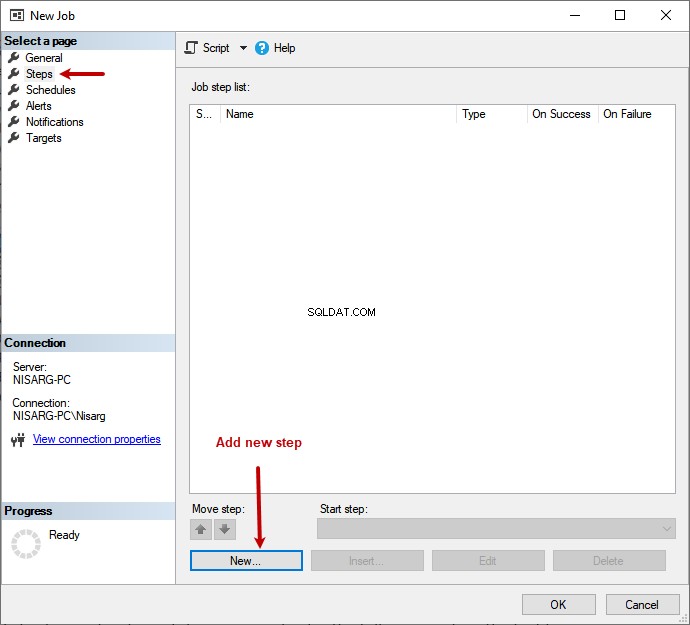
ジョブをテストするには、メンテナンスプランでその名前を右クリックします ディレクトリを選択し、実行を選択します メニューから:
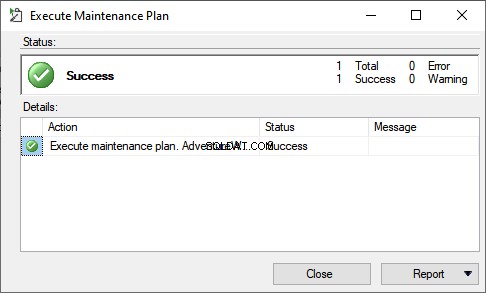
実行が開始されます。正常に完了すると、次のダイアログボックスが表示されます。
これは、メンテナンスプランを使用してインデックスを再構築する一般的な方法でした。それでは、次の方法であるT-SQLスクリプトを使用してみましょう。
2。 SQL ServerALTERINDEXの再構築
ALTER INDEXコマンドを使用して、テーブルのすべてのインデックスを再構築できます。構文は次のとおりです。
ALTER INDEX ALL ON [table_name] REBUILD注: table_name パラメータは、SQLServerのすべてのインデックスを再構築するテーブルの名前を指定します。
たとえば、[HumanResources]。[Employee]のすべてのインデックスを再構築したいとします。 。クエリは次のようになります。
use AdventureWorks2017
go
ALTER INDEX ALL ON [HumanResources].[Employee] REBUILD
Go
3。 フラグメンテーションに基づいてすべてのテーブルのすべてのインデックスを再構築するSQLServerスクリプト
インデックスのメンテナンスはリソースを大量に消費します。さらに、インデックスを再構築しているテーブルをロックします。このような複雑さを回避するには、SQL Serverのインデックスの断片化が40%を超えるインデックスを再構築する必要があります。
ケースを説明するために、断片化度が30%を超えるインデックスを再構築するT-SQLスクリプトを作成しました。その部分と機能を調べてみましょう。
変数と一時テーブルの宣言
まず、一時テーブルと変数を作成する必要があります:
- @IndexFregQuery –断片化されたインデックスの作成に使用される動的クエリを格納します。
- @IndexRebuildQuery –ALTERINDEXクエリを保持します。
- @IndexName –再構築するインデックス名
- @TableName –インデックスを再構築するテーブル名。
- @SchemaName –インデックスを再構築するスキーマ名。
- #Fregmentedindex –3列のテーブル インデックス名、テーブル名、スキーマ名を格納します。
次のコードは、変数と一時テーブルを宣言しています。
declare @i int=0
declare @IndexCount int
declare @IndexFregQuery nvarchar(max)
declare @IndexRebuildQuery nvarchar(max)
declare @IndexName varchar(500)
declare @TableName varchar(500)
declare @SchemaName varchar(500)
create table #Fregmentedindex(Index_name varchar(max),table_name varchar(max),schema_name varchar(max))
断片化されたインデックスのリストを取得する
次のステップは、30%以上の断片化度でインデックスのリストを作成することです。これらのインデックスを#FregmentedIndexesに挿入する必要があります テーブル。
クエリは、スキーマ名、テーブル名、およびインデックス名を入力して、それらを一時テーブルに挿入する必要があります。そのクエリを見てください:
set @IndexFregQuery='SELECT i.[name],o.name,sch.name
FROM [' + @DatabaseName + '].sys.dm_db_index_physical_stats (DB_ID('''+ @DatabaseName +'''), NULL, NULL, NULL, NULL) AS s
INNER JOIN [' + @DatabaseName + '].sys.indexes AS i ON s.object_id = i.object_id AND s.index_id = i.index_id
INNER JOIN [' + @DatabaseName + '].sys.objects AS o ON i.object_id = o.object_id
INNER JOIN [' + @DatabaseName + '].sys.schemas AS sch ON o.schema_id=sch.schema_id
WHERE (s.avg_fragmentation_in_percent > 30 ) and i.name is not null'
insert into #Fregmentedindex(Index_name,table_name,schema_name) exec sp_executesql @IndexFregQuery
動的SQLクエリを作成する
最後に、動的な ALTER INDEXを作成する必要があります コマンドを実行して実行します。
コマンドを生成するために、WHILEループを使用しています。 #FregmentedIndexesを繰り返します テーブルを作成し、スキーマ名、テーブル名、およびインデックス名を入力して、 @SchemaNameに保存します。 、 @TableName 、および @IndexName 。パラメータの値は、ALTERINDEXコマンドで追加されます。
コードは次のとおりです。
set @IndexCount=(select count(1) from #Fregmentedindex)
While (@IndexCount>@i)
begin
(select top 1 @TableName=table_name, @IndexName=Index_name,@SchemaName= schema_name from #Fregmentedindex)
Set @IndexRebuildQuery ='Alter index [' + @IndexName +'] on ['example@sqldat.com +'].['example@sqldat.com+'].[' + @TableName +'] rebuild'
exec sp_executesql @IndexRebuildQuery
set @example@sqldat.com+1
delete from #Fregmentedindex where example@sqldat.com and example@sqldat.com
End
コード全体をsp_index_maintenanceにカプセル化しました DBAToolsで作成されたストアドプロシージャ データベース。コードは次のとおりです:
use DBATools
go
Create procedure sp_index_maintenance_daily
@DatabaseName varchar(50)
as
begin
declare @i int=0
declare @IndexCount int
declare @IndexFregQuery nvarchar(max)
declare @IndexRebuildQuery nvarchar(max)
declare @IndexName varchar(500)
declare @TableName varchar(500)
declare @SchemaName varchar(500)
create table #Fregmentedindex(Index_name varchar(max),table_name varchar(max),schema_name varchar(max))
set @IndexFregQuery='SELECT i.[name],o.name,sch.name
FROM [' + @DatabaseName + '].sys.dm_db_index_physical_stats (DB_ID('''+ @DatabaseName +'''), NULL, NULL, NULL, NULL) AS s
INNER JOIN [' + @DatabaseName + '].sys.indexes AS i ON s.object_id = i.object_id AND s.index_id = i.index_id
INNER JOIN [' + @DatabaseName + '].sys.objects AS o ON i.object_id = o.object_id
INNER JOIN [' + @DatabaseName + '].sys.schemas AS sch ON o.schema_id=sch.schema_id
WHERE (s.avg_fragmentation_in_percent > 30 ) and i.name is not null'
insert into #Fregmentedindex(Index_name,table_name,schema_name) exec sp_executesql @IndexFregQuery
set @IndexCount=(select count(1) from #Fregmentedindex)
While (@IndexCount>@i)
begin
(select top 1 @TableName=table_name, @IndexName=Index_name,@SchemaName= schema_name from #Fregmentedindex)
Set @IndexRebuildQuery ='Alter index [' + @IndexName +'] on ['example@sqldat.com +'].['example@sqldat.com+'].[' + @TableName +'] rebuild'
exec sp_executesql @IndexRebuildQuery
set @example@sqldat.com+1
delete from #Fregmentedindex where example@sqldat.com and example@sqldat.com
End
End
手順の準備ができたら、SQLジョブを構成できます。
SQLServerエージェントを展開します >ジョブを右クリックします >新しい仕事 。
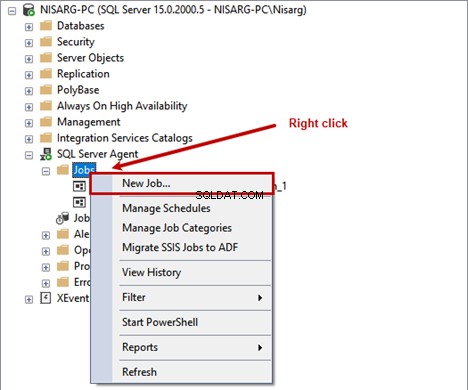
新しい仕事 ウィンドウが開き、目的のジョブ名を指定する必要があります。
ジョブステップを作成するには、ステップに移動します セクション>新規 ボタン:
新しいジョブステップに移動します そのステップを構成するためのウィンドウ。
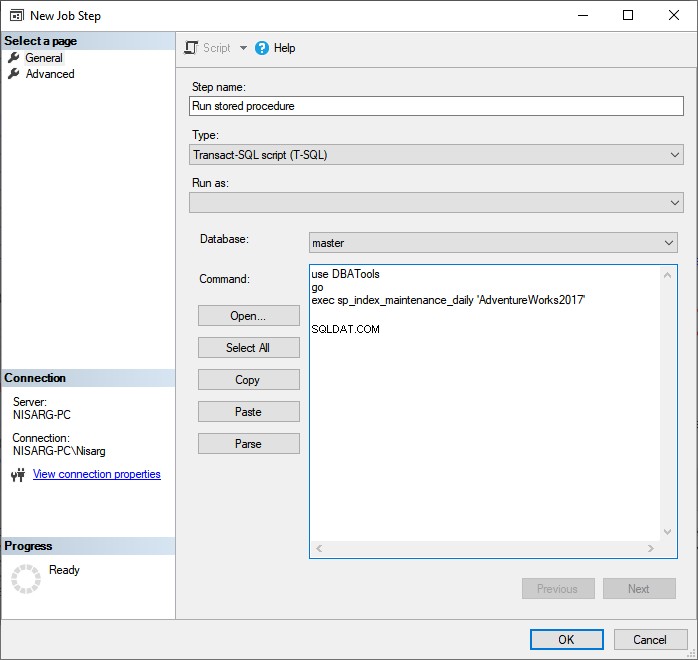
目的のステップ名を入力し、テキストボックスに次のコードを入力します。
use DBATools
go
exec sp_index_maintenance_daily 'AdventureWorks2017'
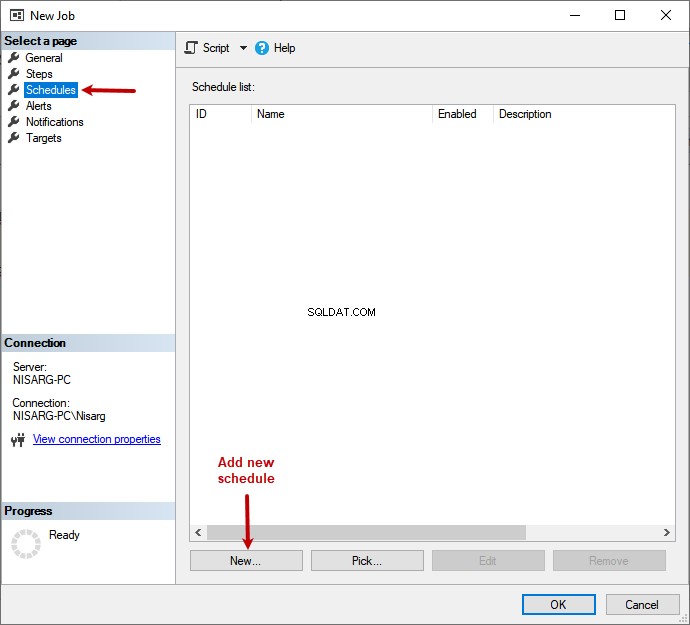
スケジュールを設定するには、スケジュールに移動します >新規をクリックします 。
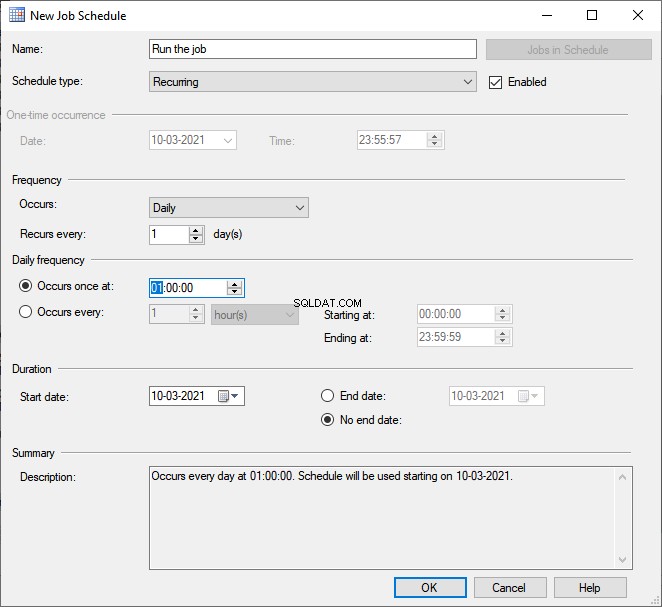
私たちの仕事は午前1時に実行する必要があります。したがって、スケジュールを構成します。
- スケジュールタイプ >繰り返し 。
- 頻度 セクション>発生 >毎日 ; 毎回繰り返される > 1 (1つ)。
- 毎日の頻度 セクション>で1回発生 >01:00:00。
- OKをクリックします 。
新しい仕事に戻されます セクション。 OKをクリックします そこにもジョブを作成します。
新しく作成されたジョブは、ジョブで利用できます。 SQLServerエージェントの下のディレクトリ フォルダ。
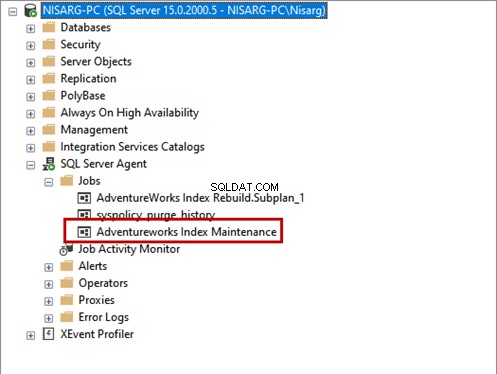
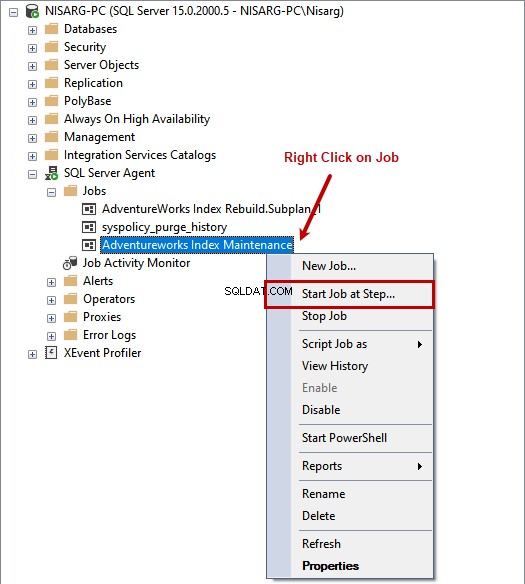
ここで、ジョブをテストする必要があります。ジョブを右クリックして、ジョブの開始…を選択します。
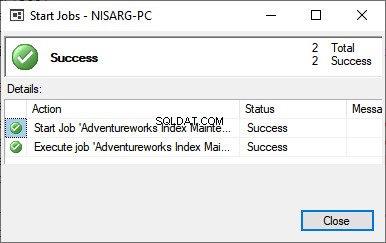
ジョブが開始され、正常に完了すると、次のメッセージが表示されます。
クラスター化インデックスと非クラスター化インデックスを比較すると、一意のクラスター化インデックスを作成すると、クエリのパフォーマンスが向上することがわかります。 SQL Serverのインデックス付きビューは、クエリの実行を高速化するために使用できます。 SQLIndexManagerを使用してインデックスを管理する方法も確認してください。
概要
現在の記事では、すべてのテーブルのインデックスを再構築する3つの機能的な方法を紹介しました。ジョブ構成を説明するために、ステップバイステップのガイドラインと実用的なSQLインデックスの例を使用してそれらすべてを調査しました。適切なバリアントの選択はあなた次第です。この記事がお役に立てば幸いです。