完璧な世界では、クエリを表現するためにどの特定のT-SQL構文を選択したかは問題ではありません。意味的に同一の構造は、まったく同じパフォーマンス特性を備えた、まったく同じ物理実行プランにつながります。
これを実現するには、SQL Serverクエリオプティマイザーは、考えられるすべての論理的等価性を認識し(すべてを知ることができると想定)、すべてのオプションを検討するための時間とリソースを提供する必要があります。 T-SQLで同じ要件を表現できる方法が非常に多く、可能な変換が非常に多いことを考えると、非常に単純な場合を除いて、組み合わせはすぐに管理できなくなります。
完全な構文に依存しない「完璧な世界」は、適度に複雑なクエリがコンパイルされるまで数日、数週間、さらには数年も待たなければならないユーザーにとっては、それほど完璧に見えないかもしれません。したがって、クエリオプティマイザは妥協します。いくつかの一般的な同等性を調査し、実行時間の節約よりもコンパイルと最適化に多くの時間を費やさないように努めます。その目標は、妥当なリソースを消費しながら、妥当な時間内に妥当な実行計画を見つけようとすることとして要約できます。
このすべての結果の1つは、実行計画がクエリの記述形式に敏感であることが多いということです。オプティマイザーには、広く使用されている同等の構造を一般的な形式にすばやく変換するためのロジックがありますが、これらの機能は十分に文書化されておらず、(どこでも)包括的でもありません。
より単純なクエリを記述し、有用なインデックスを提供し、優れた統計を維持し、よりリレーショナルな概念に限定することで(カーソル、明示的なループ、非インライン関数を回避するなど)、優れた実行プランを取得できる可能性を確実に最大化できますが、これは完全なソリューションではありません。また、1つのT-SQL構造が常に 意味的に同一の代替案よりも優れた実行計画を作成します。
私の通常のアドバイスは、必要に応じてT-SQL構文を使用して、ニーズを満たす最も単純なリレーショナルクエリフォームから始めることです。物理的な最適化(インデックス作成など)後にクエリが要件を満たしていない場合は、元のセマンティクスを維持しながら、少し異なる方法でクエリを表現することをお勧めします。これは難しい部分です。クエリのどの部分を書き直してみるべきですか?どの書き直しを試してみるべきですか?これらの質問に対する単純な万能の答えはありません。クエリの最適化と実行エンジンの内部について少し知っていると、経験に基づいたものもあります。
例
この例では、AdventureWorksTransactionHistoryテーブルを使用しています。以下のスクリプトは、テーブルのコピーを作成し、クラスター化されたインデックスとクラスター化されていないインデックスを作成します。データを変更することはありません。この手順は、インデックスを明確にする(そしてテーブルに短い名前を付ける)ためだけのものです:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
タスクは、6つの特定の製品の製品IDと履歴IDのリストを作成することです。クエリを表現する1つの方法は次のとおりです。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
このクエリは、次の実行プラン(SentryOneプランエクスプローラーに表示)を使用して764行を返します。

この単純なクエリは、TRIVIALプランのコンパイルに適しています。実行プランは、6つの個別のインデックスシーク操作を1つにまとめたものです。
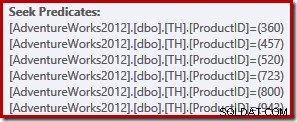
イーグルアイの読者は、6つのシークが昇順にリストされていることに気付くでしょう。 元のクエリのINリストで指定された(任意の)順序ではなく、製品IDの順序。実際、自分でクエリを実行すると、製品IDの昇順で結果が返される可能性が非常に高くなります。クエリは保証されていません もちろん、最上位のORDER BY句を指定しなかったため、この順序で結果を返します。ただし、この場合に作成された実行プランを変更せずに、このようなORDERBY句を追加できます。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
実行プランの図はまったく同じであるため、繰り返しません。クエリはまだ些細なプランに該当し、シーク操作はまったく同じであり、2つのプランの推定コストはまったく同じです。 ORDER BY句を追加しても、まったく費用はかかりませんが、結果セットの順序が保証されます。
これで、結果が製品IDの順序で返されることが保証されますが、クエリでは現在、同じの行を指定していません。 商品IDをご注文いただきます。結果を見ると、同じ商品IDの行がトランザクションIDの昇順で並べられているように見える場合があります。
明示的なORDERBYがない場合、これは単なる別の観察です(つまり、この順序に依存することはできません)が、クエリを変更して、各製品ID内のトランザクションIDで行が順序付けられるようにすることができます:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
この場合も、このクエリの実行プランは以前とまったく同じです。同じ推定コストで同じ些細な計画が作成されます。違いは、結果が保証されているということです。 最初に製品IDで注文し、次にトランザクションIDで注文します。
実行計画が同じであるため、前の2つのクエリも常にこの順序で行を返すと結論付けたくなる人もいるかもしれません。すべての実行エンジンの詳細が実行計画で公開されているわけではないため(XML形式であっても)、これは安全な意味ではありません。明示的なorderby句がない場合、SQL Serverは、プランが同じように見えても、任意の順序で行を自由に返すことができます(たとえば、クエリテキストで指定された順序でシークを実行できます)。重要なのは、クエリオプティマイザが、ユーザーには表示されないエンジン内の特定の動作を認識しており、強制できることです。
商品IDの非一意の非クラスター化インデックスが商品との行をどのように返すことができるか疑問に思っている場合 トランザクションIDの順序では、答えは、非クラスター化インデックスキーにトランザクションID(一意のクラスター化インデックスキー)が組み込まれているということです。実際、物理的 非クラスター化インデックスの構造は正確に 次の定義でインデックスを作成したかのように、すべてのレベルで同じです。
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
明示的なDISTINCTまたはGROUPBYを使用してクエリを記述しても、まったく同じ実行プランを取得できます。
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
明確にするために、これは元の非クラスター化インデックスを変更する必要はありません。最後の例として、結果を降順でリクエストすることもできることに注意してください。
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
実行プランのプロパティに、インデックスが逆方向にスキャンされることが示されるようになりました:

それを除けば、計画は同じです。それは、些細な計画の最適化段階で作成されたものであり、推定コストは同じです。
クエリの書き換え
以前のクエリまたは実行プランに問題はありませんが、クエリを別の方法で表現することを選択した可能性があります:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
明らかに、このフォームは元のフォームとまったく同じ結果を指定し、実際、新しいクエリは同じ実行プランを生成します(簡単なプラン、1つの複数のシーク、同じ推定コスト)。 OR形式を使用すると、結果が6つの個別の製品IDの結果の組み合わせであることが少し明確になります。これにより、このアイデアをさらに明確にする別のバリエーションを試すことができます。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
UNION ALLクエリの実行プランはまったく異なります:
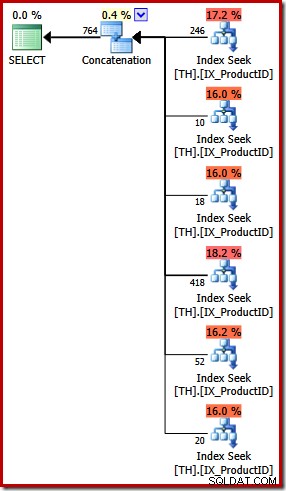
明らかな視覚的な違いは別として、この計画にはコストベース(FULL)の最適化が必要であり(些細な計画には適合しませんでした)、推定コストは(比較的)かなり高く、約 0.02 > ユニット対0.005 前のユニット。
これは私の冒頭の発言に戻ります。クエリオプティマイザはすべての論理的等価性を認識しているわけではなく、同じ結果を指定するものとして代替クエリを常に認識するとは限りません。この段階で私が指摘しているのは、INではなくUNION ALLを使用してこの特定のクエリを表現すると、実行プランが最適化されなくなるということです。
2番目の例
この例では、6つの製品IDの異なるセットを選択し、トランザクションIDの順序で結果を要求します。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
非クラスター化インデックスは要求された順序で行を提供できないため、クエリオプティマイザーは、非クラスター化インデックスをシークして並べ替えるか、クラスター化インデックス(トランザクションIDのみをキーとする)をスキャンして製品ID述語を次のように適用するかを選択できます。残差。リストされている製品IDは、前のセットよりも選択性が低いため、この場合、オプティマイザーはクラスター化されたインデックススキャンを選択します。
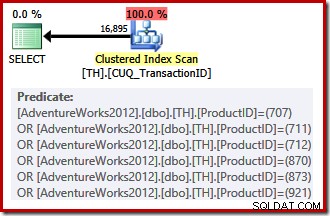
コストベースの選択があるため、この実行計画は簡単な計画の対象にはなりませんでした。最終計画の推定コストは約0.714 ユニット。クラスタ化されたインデックスをスキャンするには、 797が必要です 実行時の論理読み取り。
クエリが製品インデックスを使用していなかったことに驚いたかもしれませんが、インデックスヒントを使用するか、FORCESEEKを指定して、非クラスター化インデックスのシークを強制しようとする場合があります。
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
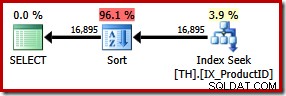
これにより、トランザクションIDによる明示的な並べ替えが行われます。新しい種類は96%を占めると推定されています 新しい計画の1.15 単価。この高い推定コストは、オプティマイザーが独自のデバイスに任せたときに明らかに安価なクラスター化インデックススキャンを選択した理由を説明しています。ただし、新しいクエリのI / Oコストは低くなります。実行すると、インデックスシークは 49しか消費しません。 論理読み取り(797から減少)。
(以前は失敗した)UNION ALLアイデアを使用してこのクエリを表現することも選択した可能性があります:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
は、次の実行プランを生成します(画像をクリックして新しいウィンドウで拡大します):

この計画はもっと複雑に見えるかもしれませんが、推定費用は 0.099だけです。 単位。これは、クラスター化されたインデックススキャン( 0.714 )よりもはるかに低くなります。 ユニット)またはシークプラスソート( 1.15 ユニット)。さらに、新しいプランは 49しか消費しません 実行時の論理読み取り–シーク+ソート計画と同じであり、クラスター化インデックススキャンに必要な797よりもはるかに低くなります。
今回は、UNION ALLを使用してクエリを表現すると、推定コストと論理読み取りの両方の点で、はるかに優れた計画が作成されました。ソースデータセットは少し小さすぎて、クエリ期間やCPU使用率を真に意味のある比較を行うことはできませんが、クラスター化インデックススキャンには、システム上の他の2つのスキャンの2倍の時間(26ミリ秒)かかります。
ヒント付きプランの余分な並べ替えは、ディスクに流出する可能性が低いため、この単純な例ではおそらく無害ですが、多くの人は、非ブロッキングであり、メモリの付与を回避し、クエリのヒント。
結論
クエリが論理的にまったく同じ結果セットを指定している場合でも、クエリ構文がオプティマイザによって選択された実行プランに影響を与える可能性があることを確認しました。同じ書き直し(例:UNION ALL)により、改善が見られる場合があり、より悪い計画が選択される場合があります。
クエリを書き直して別の構文を試すことは有効な調整手法ですが、注意が必要です。 1つのリスクは、製品への将来の変更により、別のクエリフォームが突然より良いプランの作成を停止する可能性があることですが、それは常にリスクであり、アップグレード前のテストまたはプランガイドの使用によって軽減されると主張することができます。
>この手法に夢中になってしまうリスクもあります。「奇妙な」または「異常な」クエリ構造を使用してよりパフォーマンスの高い計画を取得することは、多くの場合、境界線を越えたことを示しています。有効な代替構文と「異常/奇妙な」の違いが正確にどこにあるかは、おそらくかなり主観的です。私自身の個人的なガイドは、同等のリレーショナルクエリフォームを使用し、可能な限りシンプルにすることです。