フィルタリングされたインデックスを追加すると、新しいフィルタリングされたインデックスが完全に無関係であるように見える場合でも、既存のクエリに驚くべき副作用が生じる可能性があります。この投稿では、パフォーマンスの低下とデッドロックのリスクの増加をもたらすDELETEステートメントに影響を与える例を見ていきます。
テスト環境
次の表は、この投稿全体で使用されます:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); 次のステートメントは、499,999行のサンプルデータを作成します。
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; これは、1から499,999までの連続する整数のソースとしてNumbersテーブルを使用します。テスト環境にこれらのいずれかがない場合は、次のコードを使用して、1〜1,000,000の整数を含むコードを効率的に作成できます。
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); 後のテストの基本は、特定のStartDateのテストテーブルから行を削除することです。削除する行を識別するプロセスをより効率的にするには、次の非クラスター化インデックスを追加します。
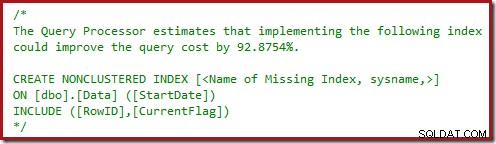
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); サンプルデータ
これらの手順が完了すると、サンプルは次のようになります。
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
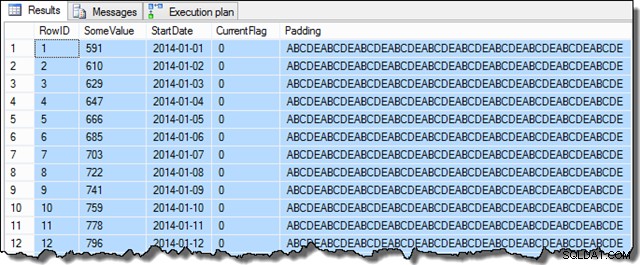
SomeValue列のデータは、疑似乱数生成のためにわずかに異なる場合がありますが、この違いは重要ではありません。全体として、サンプルデータには、2014年1月の31のStartDate日付ごとに16,129行が含まれています。
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
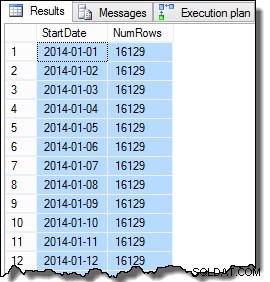
データをある程度現実的にするために実行する必要がある最後のステップは、各StartDateの最大のRowIDに対してCurrentFlag列をtrueに設定することです。次のスクリプトはこのタスクを実行します:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; この更新の実行プランは、1日あたりの最大のRowIDを効率的に見つけるためのSegment-Topの組み合わせを特徴としています。

実行プランが、記述された形式のクエリとほとんど類似していないことに注意してください。これは、SQLを直接実装するのではなく、論理SQL仕様からオプティマイザーがどのように機能するかを示す優れた例です。ご参考までに、ハロウィーンの保護には、そのプランのEagerTableSpoolが必要です。
1日のデータの削除
さて、準備が完了したら、当面のタスクは特定のStartDateの行を削除することです。これは、データが耐用年数の終わりに達したテーブルの最も早い日付に日常的に実行する可能性のある種類のクエリです。
2014年1月1日を例にとると、テスト削除クエリは単純です。
DELETE dbo.Data WHERE StartDate = '20140101';
実行計画も同様に非常に単純ですが、少し詳しく調べる価値があります。

計画分析
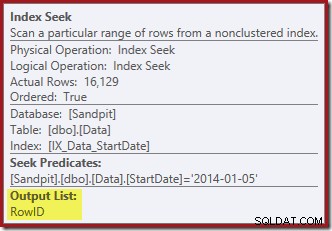
右端のインデックスシークは、非クラスター化インデックスを使用して、指定されたStartDate値の行を検索します。オペレーターのツールチップが確認するように、検出したRowID値のみを返します。
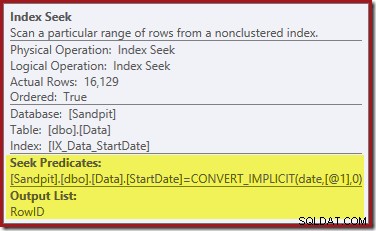
StartDateインデックスがどのようにRowIDを返すのか疑問に思っている場合は、RowIDがテーブルの一意のクラスター化インデックスであるため、StartDate非クラスター化インデックスに自動的に含まれることに注意してください。
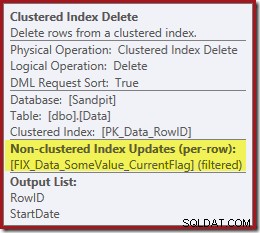
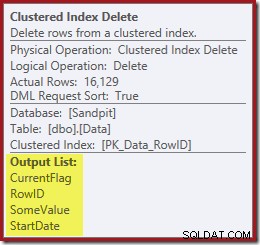
計画の次の演算子は、クラスター化インデックスの削除です。これは、インデックスシークによって検出されたRowID値を使用して、削除する行を検索します。
プランの最後の演算子はインデックス削除です。これにより、非クラスター化インデックスIX_Data_StartDateから行が削除されます。 ClusteredIndexDeleteによって削除されたRowIDに関連するもの。非クラスター化インデックスでこれらの行を見つけるには、クエリプロセッサにStartDate(非クラスター化インデックスのキー)が必要です。
元のインデックスシークは開始日を返さず、RowIDのみを返したことを思い出してください。では、クエリプロセッサはどのようにしてインデックス削除の開始日を取得するのでしょうか。この特定のケースでは、オプティマイザーはStartDate値が定数であることに気づき、それを最適化した可能性がありますが、これは起こったことではありません。答えは、クラスター化インデックス削除演算子が読み取るということです。 現在の行のStartDate値を取得し、それをストリームに追加します。以下に示すクラスター化インデックス削除の出力リストを、すぐ上のインデックスシークの出力リストと比較します。
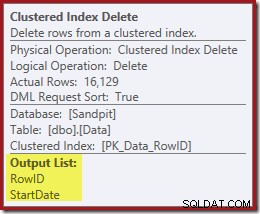
Delete演算子がデータを読み取るのを見るのは意外に思われるかもしれませんが、これが機能する方法です。クエリプロセッサは、行を削除するためにクラスター化インデックス内の行を見つける必要があることを認識しているため、可能であれば、非クラスター化インデックスを維持するために必要な列の読み取りをその時点まで延期することもできます。
フィルタリングされたインデックスの追加
ここで、パフォーマンスが悪いこのテーブルに対して誰かが重要なクエリを実行していると想像してください。役立つDBAが分析を実行し、次のフィルタリングされたインデックスを追加します。
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; 新しいフィルタリングされたインデックスは、問題のあるクエリに望ましい効果をもたらし、誰もが満足しています。新しいインデックスはStartDate列をまったく参照していないため、日削除クエリにまったく影響しないことに注意してください。
フィルタリングされたインデックスを使用して1日を削除する
データをもう一度削除することで、その期待をテストできます:
DELETE dbo.Data WHERE StartDate = '20140102';
突然、実行プランが並列クラスター化インデックススキャンに変更されました:

新しいフィルタリングされたインデックスには、個別のインデックス削除演算子がないことに注意してください。オプティマイザーは、クラスター化インデックス削除オペレーター内でこのインデックスを維持することを選択しました。これは、上記のようにSQL Sentry Plan Explorerで強調表示され(「+1非クラスター化インデックス」)、ツールチップに詳細が表示されます:
テーブルが大きい場合(データウェアハウスを考えてください)、並列スキャンへのこの変更は非常に重要になる可能性があります。 StartDateの素敵なインデックスシークはどうなりましたか?完全に無関係なフィルタリングされたインデックスが物事を劇的に変えたのはなぜですか?
問題の発見
最初の手がかりは、クラスター化インデックススキャンのプロパティを確認することです。
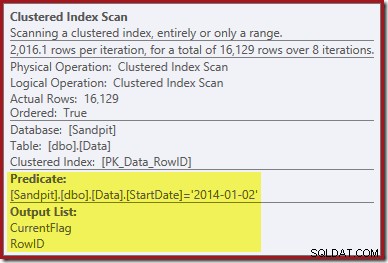
削除するクラスター化インデックス削除演算子のRowID値を見つけるだけでなく、この演算子はCurrentFlag値を読み取っています。この列の必要性は明確ではありませんが、少なくともスキャンの決定を説明し始めています。CurrentFlag列はStartDate非クラスター化インデックスの一部ではありません。
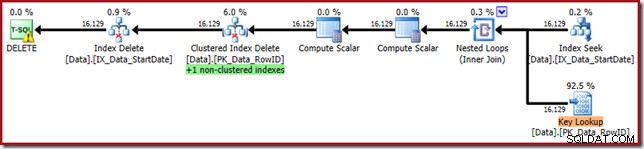
これを確認するには、削除クエリを書き直して、StartDate非クラスター化インデックスを強制的に使用します。
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; 実行プランは元の形式に近いですが、キールックアップを備えています:
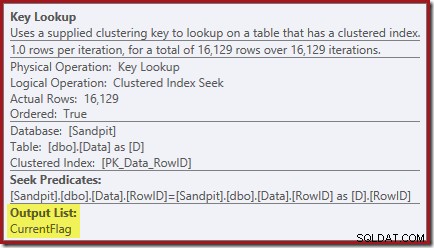
キールックアッププロパティは、この演算子がCurrentFlag値を取得していることを確認します:
また、最後の2つの計画で三角表示板に気づいたかもしれません。インデックスの警告がありません:
これは、SQLServerが非クラスター化インデックスに含まれるCurrentFlag列を確認することをさらに確認するものです。並列クラスター化インデックススキャンに変更された理由は明らかです。クエリプロセッサは、テーブルのスキャンはキールックアップを実行するよりも安価であると判断します。
はい、でもなぜですか?
これはすべて非常に奇妙です。元の実行プランでは、SQLServerは読み取ることができました ClusteredIndexDelete演算子で非クラスター化インデックスを維持するために必要な追加の列データ。フィルター処理されたインデックスを維持するにはCurrentFlag列の値が必要ですが、SQLServerが同じ方法でインデックスを処理しないのはなぜですか。
簡単に言えば、それは可能ですが、フィルタリングされたインデックスが別のインデックス削除演算子で維持されている場合に限ります。文書化されていないトレースフラグ8790を使用して、現在のクエリに対してこれを強制できます。このフラグがない場合、オプティマイザは、各インデックスを個別の演算子で維持するか、ベーステーブル操作の一部として維持するかを選択します。
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
実行プランは、StartDate非クラスター化インデックスの検索に戻ります:
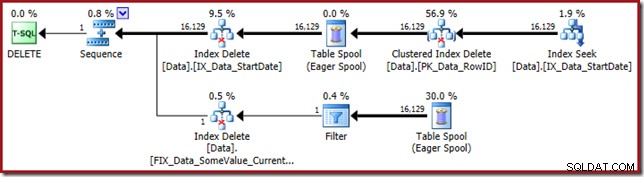
インデックスシークはRowID値のみを返します(CurrentFlagは返しません):
そして、クラスター化されたインデックスの削除読み取り CurrentFlagを含む非クラスター化インデックスを維持するために必要な列:
このデータはテーブルスプールに熱心に書き込まれ、テーブルスプールは、更新が必要なインデックスごとに再生されます。フィルタリングされたインデックスのインデックス削除演算子の前にある明示的なフィルタ演算子にも注意してください。
注意すべきもう1つのパターン
この問題により、インデックスシークではなくテーブルスキャンが発生するとは限りません。この例を見るには、テストテーブルに別のインデックスを追加してください:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); このインデックスはないことに注意してください フィルタリングされ、StartDate列は含まれません。次に、日削除クエリを再試行します:
DELETE dbo.Data WHERE StartDate = '20140104';
オプティマイザーはこのモンスターを思い付きます:
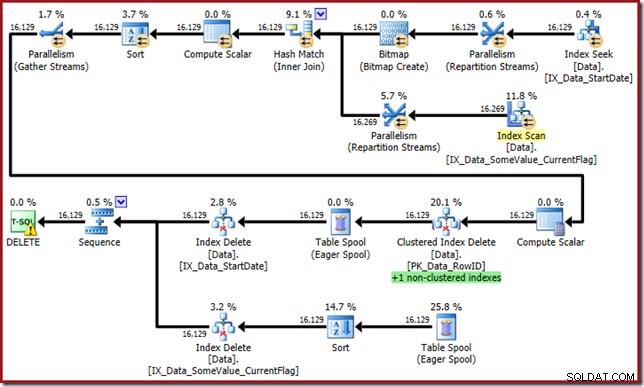
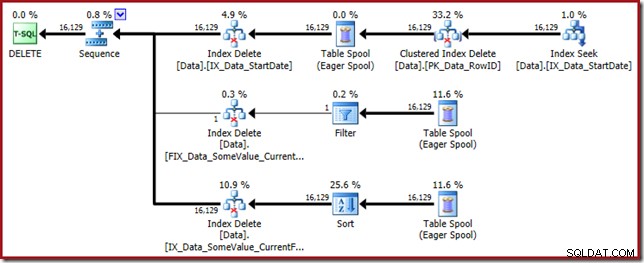
このクエリプランには高い驚きの要素がありますが、根本的な原因は同じです。 CurrentFlag列は引き続き必要ですが、オプティマイザーはテーブルスキャンの代わりにインデックス交差戦略を選択して取得します。トレースフラグを使用すると、インデックスごとのメンテナンスプランが強制され、健全性が再び復元されます(唯一の違いは、新しいインデックスを維持するための追加のスプール再生です):
フィルタリングされたインデックスのみがこれを引き起こします
この問題は、オプティマイザーがクラスター化インデックス削除オペレーターでフィルター処理されたインデックスを維持することを選択した場合にのみ発生します。次の例に示すように、フィルタリングされていないインデックスは影響を受けません。最初のステップは、フィルタリングされたインデックスを削除することです:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
次に、クラスター化インデックスの削除ですべてのインデックスを維持するようにオプティマイザーを説得する方法でクエリを作成する必要があります。これに対する私の選択は、変数とヒントを使用して、オプティマイザーの行数の期待値を下げることです。
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); 実行計画は次のとおりです。
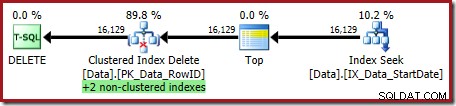
非クラスター化インデックスは両方とも、クラスター化インデックスの削除によって維持されます:
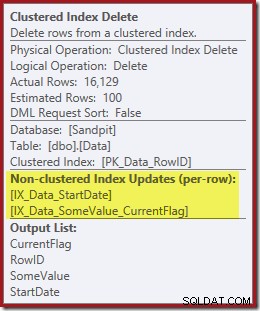
インデックスシークはRowIDのみを返します:
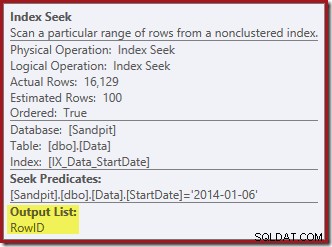
インデックスの保守に必要な列は、削除演算子によって内部的に取得されます。これらの詳細は、show planの出力には表示されません(したがって、delete演算子の出力リストは空になります)。 OUTPUTを追加しました クエリの句を使用して、入力で受信しなかったデータを返すクラスター化インデックスの削除をもう一度表示します。
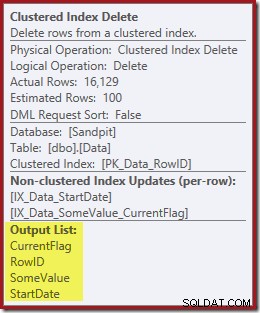
最終的な考え
これは回避するのが難しい制限です。一方では、通常、本番システムで文書化されていないトレースフラグを使用することは望ましくありません。
自然な「修正」は、フィルター処理されたインデックスのメンテナンスに必要な列をすべてに追加することです。 削除する行を見つけるために使用される可能性のある非クラスター化インデックス。これは、多くの観点から、あまり魅力的な提案ではありません。もう1つの方法は、フィルター処理されたインデックスをまったく使用しないことですが、それも理想的とは言えません。
私の感じでは、クエリオプティマイザーは、フィルター処理されたインデックスのインデックスごとのメンテナンスの代替案を自動的に検討する必要がありますが、その推論は現在この領域では不完全であるように見えます(そして、インデックスごと/行ごとに適切なコストをかけるのではなく、単純なヒューリスティックに基づいています代替案)。
そのステートメントの周りにいくつかの数字を置くために、オプティマイザーによって選択された並列クラスター化インデックススキャンプランは 5.5で入ってきました 私のテストのユニット。トレースフラグを使用した同じクエリでは、 1.4のコストが見積もられます。 ユニット。 3番目のインデックスが設定されているため、オプティマイザーによって選択された並列インデックス交差プランの推定コストは 4.9 でした。 、一方、トレースフラグプランは 2.7で導入されました 単位(SQL Server 2014 RTM CU1ビルド12.0.2342でのすべてのテストは、120カーディナリティ推定モデルで、トレースフラグ4199が有効になっています)。
これは改善すべき行動だと思います。このConnectアイテムについて、私に賛成または反対に投票できます。