文字列データ型は、プログラミング言語で最も重要なデータ型の1つです。それなしでは、役に立つプログラムを書くことはほとんどできません。それにもかかわらず、多くの開発者はこのタイプの特定の側面を知りません。したがって、これらの側面について考えてみましょう。
メモリ内の文字列の表現
.Netでは、文字列はBSTR(基本文字列またはバイナリ文字列)ルールに従って配置されます。この文字列データ表現の方法は、COMで使用されます(「基本」という単語は、最初に使用されたVisual Basicプログラミング言語に由来します)。ご存知のように、PWSZ(ワイド文字ストリングへのポインター、ゼロで終了)は、ストリングの表現のためにC /C++で使用されます。メモリ内のそのような場所では、nullで終了する文字列が文字列の最後にあります。このターミネータを使用すると、文字列の終わりを判別できます。 PWSZの文字列の長さは、空き領域の量によってのみ制限されます。
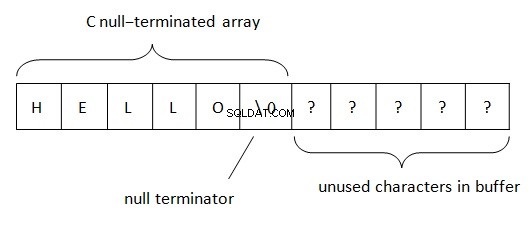
BSTRでは、状況が少し異なります。
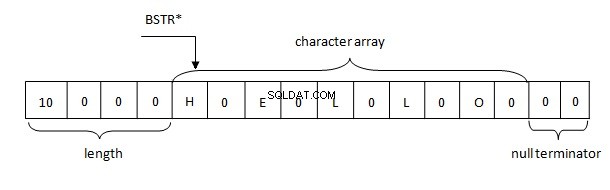
メモリ内のBSTR文字列表現の基本的な側面は次のとおりです。
- 文字列の長さは特定の数によって制限されます。 PWSZでは、文字列の長さは空きメモリの可用性によって制限されます。
- BSTR文字列は、常にバッファの最初の文字を指します。 PWSZは、バッファ内の任意の文字を指すことができます。
- BSTRでは、PWSZと同様に、ヌル文字は常に最後に配置されます。 BSTRでは、ヌル文字は有効な文字であり、文字列のどこにでもあります。
- ヌルターミネータが最後にあるため、BSTRはPWSZと互換性がありますが、その逆はありません。
したがって、.NETの文字列は、BSTRルールに従ってメモリ内で表されます。バッファには、4バイトの文字列長とそれに続くUTF-16形式の文字列の2バイト文字が含まれ、その文字列の後に2つのヌルバイト(\ u0000)が続きます。
この実装を使用すると、多くの利点があります。文字列の長さはヘッダーに格納されるため再計算しないでください。文字列にはどこにでもヌル文字を含めることができます。そして最も重要なことは、文字列(固定)のアドレスをネイティブコードに簡単に渡すことができることです。 WCHAR * 期待されています。
文字列オブジェクトはどのくらいのメモリを消費しますか?
文字列オブジェクトのサイズがsize=20 +(length / 2)* 4に等しいという記事に遭遇しましたが、この式は完全には正しくありません。
まず、文字列はリンクタイプであるため、最初の4バイトには SyncBlockIndexが含まれます。 次の4バイトにはタイプポインタが含まれています。
文字列サイズ=4+4+…
上で述べたように、文字列の長さはバッファに保存されます。これはint型のフィールドであるため、さらに4バイトを追加する必要があります。
文字列サイズ=4+ 4 +4+…
文字列を(コピーせずに)ネイティブコードにすばやく渡すために、2バイトを使用する各文字列の最後にnullターミネータが配置されています。したがって、
文字列サイズ=4+ 4 + 4 +2+…
残っているのは、文字列の各文字がUTF-16コーディングであり、2バイトかかることを思い出してください。したがって:
文字列サイズ=4+ 4 + 4 + 2 +2*長さ=14+2*長さ
もう1つ、これで完了です。 CLRのメモリマネージャによって割り当てられるメモリは、4バイトの倍数(4、8、12、16、20、24、…)です。したがって、文字列の長さが合計34バイトの場合、36バイトが割り当てられます。値を4の倍数である最も近い大きい数値に丸める必要があります。このために必要なもの:
文字列サイズ=4*((14 + 2*長さ+3)/ 4)(整数除算)
バージョンの問題 :.NET v4までは、追加の m_arrayLength がありました 4バイトを使用したStringクラスのint型のフィールド。このフィールドは、ヌルターミネータを含む、文字列に割り当てられたバッファの実際の長さです。つまり、長さ+1です。.NET4.0では、このフィールドはクラスから削除されました。その結果、文字列型オブジェクトが占める占有バイト数は4バイト少なくなります。
m_arrayLengthのない空の文字列のサイズ フィールド(つまり、.Net 4.0以降)は=4 + 4 + 4 + 2 =14バイトに等しく、このフィールド(つまり、.Net 4.0よりも小さい)では、そのサイズは=4 + 4 + 4 + 4 +2=になります。 18バイト。 4バイトを丸めると、サイズはそれぞれ16バイトと20バイトになります。
文字列の側面
そこで、文字列の表現と、文字列がメモリに取り込むサイズを検討しました。それでは、それらの特性について話しましょう。
.NETの文字列の基本的な側面は次のとおりです。
- 文字列は参照型です。
- 文字列は不変です。一度作成された文字列は(公正な手段で)変更できません。このクラスのメソッドを呼び出すたびに新しい文字列が返されますが、前の文字列はガベージコレクターの餌食になります。
- 文字列はObject.Equalsメソッドを再定義します。その結果、このメソッドは、リンク値ではなく、文字列内の文字値を比較します。
それぞれのポイントを詳しく考えてみましょう。
文字列は参照型です
文字列は実際の参照型です。つまり、それらは常にヒープに配置されます。あなたの振る舞いは同じなので、私たちの多くはそれらを値型と混同します。たとえば、それらは不変であり、それらの比較は参照ではなく値によって実行されますが、これは参照型であることに注意する必要があります。
文字列は不変です
- 文字列は目的のために不変です。文字列の不変性には多くの利点があります。
- 文字列の内容を変更できるスレッドは1つもないため、文字列タイプはスレッドセーフです。
- 不変の文字列を使用すると、同じ文字列の2つのインスタンスを格納する必要がないため、メモリの負荷が軽減されます。その結果、参照のみが比較されるため、消費されるメモリが少なくなり、比較がより高速に実行されます。 .NETでは、このメカニズムは文字列インターン(文字列プール)と呼ばれます。後で話します。
- 不変パラメータをメソッドに渡すとき、変更される心配をやめることができます(もちろん、refまたはoutとして渡されなかった場合)。
データ構造は、エフェメラルとパーシステントの2つのタイプに分けることができます。エフェメラルデータ構造は、最新バージョンのみを格納します。永続データ構造は、変更中に以前のすべてのバージョンを保存します。後者は、実際には、操作によってサイトの構造が変更されないため、不変です。代わりに、前の構造に基づく新しい構造を返します。
文字列は不変であるという事実を考えると、永続的である可能性がありますが、そうではありません。 .Netでは文字列は一時的なものです。
比較のために、Java文字列を見てみましょう。それらは.NETのように不変ですが、さらに永続的です。 JavaでのStringクラスの実装は次のようになります。
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
タイプへの参照と同期オブジェクトへの参照を含む、オブジェクトのヘッダーの8バイトに加えて、文字列には次のフィールドが含まれます。
- char配列への参照;
- char配列内の文字列の最初の文字のインデックス(最初からオフセット)
- 文字列の文字数;
- 最初にHashCode()を呼び出した後に計算されたハッシュコード メソッド。
Javaの文字列は、永続化できる追加のフィールドを含んでいるため、.NETよりも多くのメモリを消費します。永続性のため、 String.substring()の実行 JavaのメソッドはO(1)を取ります 、.NETのように文字列のコピーを必要としないため、このメソッドの実行には O(n)が必要です。 。
JavaでのString.substring()メソッドの実装:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} ただし、ソース文字列が十分に大きく、カットアウトサブ文字列の長さが数文字の場合、サブ文字列への参照が存在するまで、最初の文字列の文字配列全体がメモリ内で保留になります。または、受信した部分文字列を標準的な方法でシリアル化してネットワーク経由で渡すと、元の配列全体がシリアル化され、ネットワーク経由で渡されるバイト数が多くなります。したがって、コードの代わりに
s =ss.substring(3)
次のコードを使用できます:
s =new String(ss.substring(3))、
このコードは、ソース文字列の文字配列への参照を格納しません。代わりに、実際に使用されている配列の部分のみをコピーします。ちなみに、文字の配列の長さに等しい長さの文字列でこのコンストラクターを呼び出すと、コピーは行われません。代わりに、元の配列への参照が使用されます。
結局のところ、文字列型の実装は、Javaの最後のバージョンで変更されました。現在、クラスにはオフセットフィールドと長さフィールドはありません。新しいhash32 代わりに(異なるハッシュアルゴリズムを使用)が導入されました。これは、文字列が永続的ではなくなったことを意味します。さて、 String.substring メソッドは毎回新しい文字列を作成します。
文字列はOnbject.Equalsを再定義します
文字列クラスは、Object.Equalsメソッドを再定義します。その結果、比較は行われますが、参照ではなく、値によって行われます。文字列の比較に==を使用するコードはメソッド呼び出しよりも深遠に見えるため、開発者は==演算子を再定義してくれたStringクラスの作成者に感謝していると思います。
if (s1 == s2)
比較
if (s1.Equals(s2))
ちなみに、Javaでは==演算子は参照で比較します。文字列を文字ごとに比較する必要がある場合は、string.equals()メソッドを使用する必要があります。
文字列インターン
最後に、文字列のインターンについて考えてみましょう。簡単な例、つまり文字列を逆にするコードを見てみましょう。
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} 明らかに、このコードはコンパイルできません。文字列の内容を変更しようとするため、コンパイラはこれらの文字列に対してエラーをスローします。 Stringクラスのメソッドは、コンテンツの変更ではなく、文字列の新しいインスタンスを返します。
文字列は変更できますが、安全でないコードを使用する必要があります。次の例を考えてみましょう:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} このコードの実行後、 elbatummi era sgnirtS 期待どおり、文字列に書き込まれます。文字列の可変性は、文字列のインターンに関連する派手なケースにつながります。
文字列インターン は、類似したリテラルがメモリ内で単一のオブジェクトとして表されるメカニズムです。
要するに、文字列インターンのポイントは次のとおりです。プロセス内(アプリケーションドメイン内ではない)に単一のハッシュされた内部テーブルがあり、文字列はそのキーであり、値はそれらへの参照です。 JITコンパイル中、リテラル文字列は順番にテーブルに配置されます(テーブル内の各文字列は1回だけ見つけることができます)。実行中に、リテラル文字列への参照がこのテーブルから割り当てられます。実行中に、 String.Internを使用して文字列を内部テーブルに配置できます。 方法。また、 String.IsInterned を使用して、内部テーブルで文字列が利用可能かどうかを確認できます。 メソッド。
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
デフォルトでは、文字列リテラルのみがインターンされることに注意してください。ハッシュ化された内部テーブルはインターン実装に使用されるため、このテーブルに対する検索はJITコンパイル中に実行されます。このプロセスには時間がかかります。したがって、すべての文字列がインターンされると、最適化がゼロになります。 ILコードへのコンパイル中に、コンパイラはすべてのリテラル文字列を連結します。これは、リテラル文字列を部分的に格納する必要がないためです。したがって、2番目の等式は trueを返します 。
それでは、ケースに戻りましょう。次のコードを検討してください:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); すべてが非常に明白であり、コードは文字列は不変ですを返す必要があるようです 。しかし、そうではありません!コードはelbatummiera sgnirtSを返します 。それはまさにインターンのために起こります。文字列を変更するときは、その内容を変更します。文字列であるため、文字列の単一のインスタンスによってインターンされ、表されます。
CompilationRelaxationsAttribute を適用すると、文字列のインターンを放棄できます。 アセンブリへの属性。この属性は、CLR環境のJITコンパイラーによって作成されるコードの精度を制御します。この属性のコンストラクターは、 CompilationRelaxationsを受け入れます 列挙型。現在、 CompilationRelaxations.NoStringInterningのみが含まれています。 。その結果、アセンブリはインターンを必要としないアセンブリとしてマークされます。
ちなみに、この属性は.NETFrameworkv1.0では処理されません。そのため、インターンを無効にすることはできませんでした。バージョン2以降、 mscorlib アセンブリはこの属性でマークされています。したがって、.NETの文字列は安全でないコードで変更される可能性があることがわかりました。
安全でないことを忘れたらどうしますか?
たまたま、安全でないコードなしで文字列の内容を変更できます。代わりに、反射メカニズムを使用できます。このトリックは、バージョン2.0まで.NETで成功していました。その後、Stringクラスの開発者は、この機会を奪いました。 .NET 2.0では、Stringクラスには2つの内部メソッドがあります。 SetChar 境界チェックとInternalSetCharNoBoundsCheck それは境界チェックをしません。これらのメソッドは、指定された文字を特定のインデックスで設定します。メソッドの実装は次のようになります。
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} したがって、次のコードを使用して、安全でないコードなしで文字列の内容を変更できます。
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
予想どおり、コードは elbatummi era sgnirtSを返します 。
バージョンの問題 :.NET Frameworkのさまざまなバージョンでは、string.Emptyを統合することも統合しないこともできます。次のコードを考えてみましょう:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); .NET Framework 1.0、.NET Framework 1.1、および.NET Framework 3.5と1(SP1)サービスパック str1 およびstr2 等しくありません。現在、 string.Empty 抑留されていません。
パフォーマンスの側面
インターンのマイナスの副作用が1つあります。重要なのは、CLRによって格納された文字列インターンオブジェクトへの参照は、アプリケーション作業の終了後、およびアプリケーションドメイン作業の終了後でも保存できるということです。したがって、大きなリテラル文字列の使用は省略することをお勧めします。それでも必要な場合は、 CompilationRelaxationsを適用してインターンを無効にする必要があります アセンブリの属性。