StackExchangeの最近のスレッドで、ユーザーに次の問題が発生しました:
GroupID =2のテーブルの最初の人を返すクエリが必要です。GroupID=2の人がいない場合は、RoleID=2の最初の人が必要です。
今のところ、「最初」がひどく定義されているという事実を捨てましょう。実際には、ユーザーは、ランダムに、任意に、または主要な基準に加えて何らかの明示的なロジックを介して来たのかどうかにかかわらず、どの人物を取得したかを気にしませんでした。それを無視して、基本的なテーブルがあるとしましょう:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
現実の世界では、おそらく他の列、追加の制約、他のテーブルへの外部キー、そして確かに他のインデックスがあります。しかし、これを単純にして、クエリを考えてみましょう。
可能性のあるソリューション
そのテーブルデザインでは、問題の解決は簡単に思えますよね?おそらく最初に行うのは次のとおりです。
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
これはTOPを使用します および条件付きのORDER BY GroupID=2のユーザーをより高い優先度として扱います。このクエリの計画は非常に単純で、コストの大部分はソート操作で発生します。空のテーブルに対するランタイムメトリックは次のとおりです。
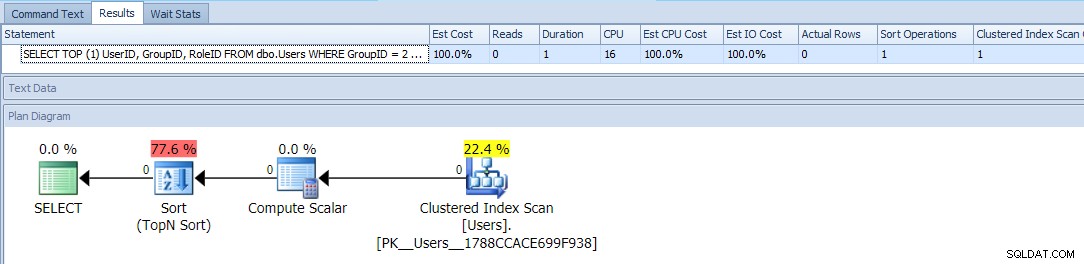
これはあなたができることとほぼ同じように見えます-テーブルを一度だけスキャンする単純な計画であり、あなたが一緒に暮らせるはずの厄介な種類を除いて、問題ありませんか?
さて、スレッドの別の答えは、このより複雑なバリエーションを提供しました:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
一見すると、このクエリは2つのクラスター化インデックススキャンを必要とするため、非常に効率が悪いと思われるかもしれません。あなたは間違いなくそれについて正しいでしょう。空のテーブルに対する計画と実行時のメトリックは次のとおりです。
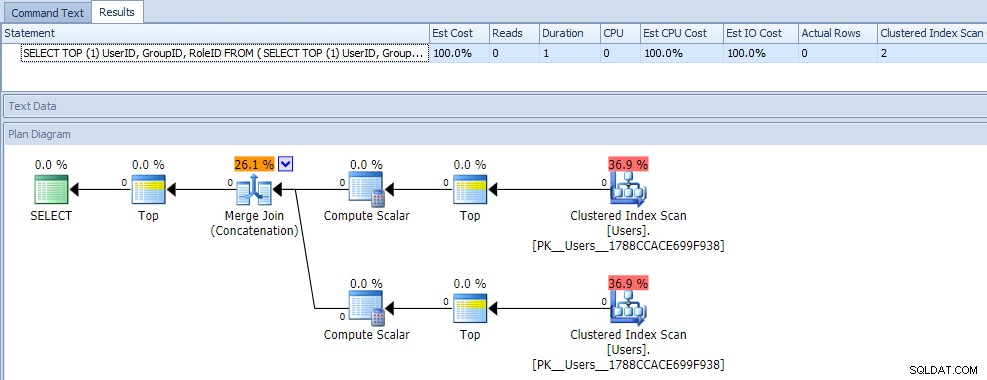
では、データを追加しましょう
これらのクエリをテストするために、いくつかの現実的なデータを使用したいと思いました。そこで、最初にsys.all_objectsから1,000行を入力し、object_idに対するモジュロ演算を使用して適切な分布を取得しました。
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
2つのクエリを実行すると、実行時の指標は次のようになります。

UNION ALLバージョンでは、I / Oがわずかに少なく(4回の読み取りと5回)、継続時間が短く、推定全体コストが低くなりますが、条件付きORDERBYバージョンでは推定CPUコストが低くなります。ここでのデータは、結論を出すにはかなり小さいです。私はただそれを地面の賭けとして欲しかったのです。次に、ほとんどの行が少なくとも1つの基準(場合によっては両方)を満たすように分布を変更しましょう。
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
今回は、条件付き順序で、CPUとI/Oの両方で推定コストが最も高くなります。

ただし、このデータサイズでは、期間と読み取りへの影響は比較的重要ではなく、推定コスト(とにかく大部分が占められています)を除けば、ここで勝者を宣言することは困難です。
では、もっと多くのデータを追加しましょう
カタログビューからサンプルデータを作成するのは楽しいですが、誰もがサンプルデータを持っているので、今回は、AdventureWorks2012のSales.SalesOrderHeaderEnlargedテーブルを使用し、JonathanKehayiasのこのスクリプトを使用して展開します。私のシステムでは、このテーブルには1,258,600行あります。次のスクリプトは、これらの行を100万行dbo.Usersテーブルに挿入します。
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
さて、クエリを実行すると、問題が発生します。ORDERBYのバリエーションが並行して実行され、読み取りとCPUの両方が消去され、期間に120倍近くの違いが生じました。
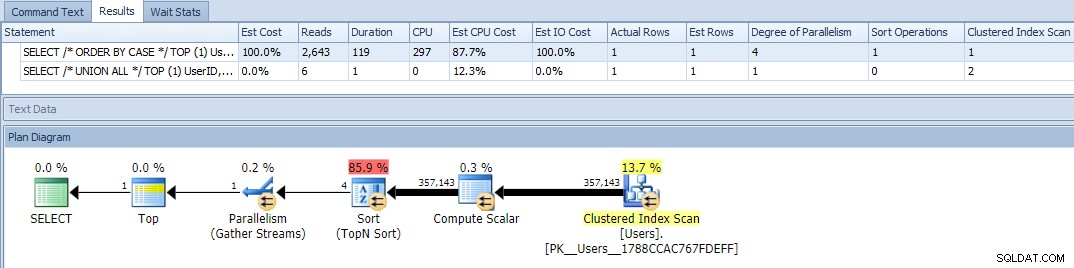
(MAXDOPを使用して)並列処理を排除しても効果はありませんでした:
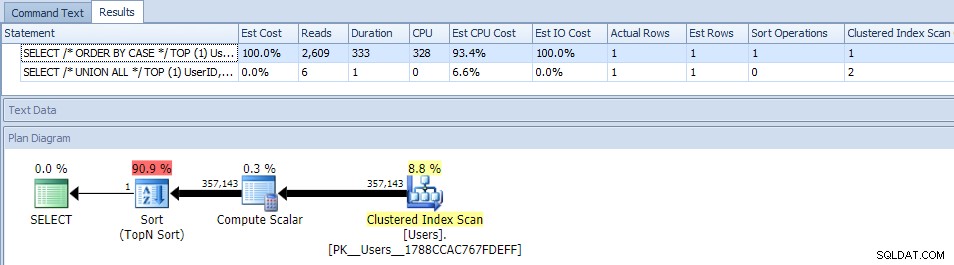
(UNION ALLプランは引き続き同じように見えます。)
また、スキューを均等に変更すると、行の95%が少なくとも1つの基準を満たします。
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
クエリは、ソートが非常に高価であることを示しています:

そして、MAXDOP =1の場合、それははるかに悪化しました(期間を見てください):

最後に、どちらの方向にも95%のスキューはありますか(たとえば、ほとんどの行がGroupID基準を満たしているか、ほとんどの行がRoleID基準を満たしています)?このスクリプトは、データの少なくとも95%がGroupID =2:
であることを確認します。-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
結果は非常に似ています(これからMAXDOPを試すのをやめます):

そして、逆にスキューすると、データの少なくとも95%がRoleID =2:
になります。-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
結果:

結論
私が製造できた単一のケースでは、「より単純な」ORDER BYクエリを実行しましたが、クラスター化インデックススキャンが1つ少なくても、より複雑なUNIONALLクエリよりも優れています。クエリセマンティクスに並べ替えなどの操作を導入するときにSQLServerが何をしなければならないかについて非常に注意する必要があり、計画の単純さだけに依存しない場合があります(以前のシナリオに基づくバイアスを気にしないでください)。
あなたの最初の本能はしばしば正しいかもしれませんが、表面上はうまくいかないように見えるより良いオプションがある場合があるに違いありません。この例のように。観察から得た仮定に疑問を投げかけることについてはかなり良くなり、「スキャンは決してうまく機能しない」や「単純なクエリは常に高速に実行される」などの包括的なステートメントを作成しません。語彙から決してそして常に単語を排除すると、それらの仮定と包括的なステートメントの多くをテストにかけ、最終的にははるかにうまくいくことに気付くかもしれません。