ゲスト作成者:Monica Rathbun(@SQLEspresso)
場合によっては、ディスクI / Oの待ち時間などのハードウェアのパフォーマンスの問題が、ハードウェアのパフォーマンスを低下させるのではなく、最適化されていないワークロードに帰着します。私を含め、多くのデータベース管理者は、ストレージの速度が遅いことをすぐに非難したいと考えています。新しいハードウェアに多額の費用をかける前に、不要なI/Oがないか常にワークロードを調べる必要があります。
調査すること
| アイテム | I/Oの影響 | 考えられる解決策 |
|---|---|---|
| 未使用のインデックス | 追加の書き込み | インデックスの削除/無効化 |
| 欠落しているインデックス | 追加の読み取り | インデックスの追加/インデックスのカバー |
| 暗黙の変換 | 追加の読み取りと書き込み | 値を評価する前にソースでフィールドを隠蔽またはキャスト |
| 機能 | 追加の読み取りと書き込み | それらを削除し、評価前にデータを変換します |
| ETL | 追加の読み取りと書き込み | SSIS、レプリケーション、変更データキャプチャ、可用性グループを使用する |
| 注文とグループ分け | 追加の読み取りと書き込み | 可能な場合はそれらを削除します |
未使用のインデックス
私たちは皆、インデックスの力を知っています。適切なインデックスを使用すると、クエリ速度に光年の違いが生じる可能性があります。しかし、インデックスの再構築と再編成を超えて、インデックスを継続的に維持している人はどれくらいいますか?インデックススクリプトを定期的に実行して、実際に使用されているインデックスを評価することが重要です。私は個人的にGlennBerryの診断クエリを使用してこれを行っています。
一部のインデックスがまったく読み取られていないことに驚かれることでしょう。これらのインデックスは、特にトランザクションの多いテーブルでは、リソースに負担をかけます。結果を見るときは、書き込み数が多く、読み取り数が少ないインデックスに注意してください。この例では、書き込みを無駄にしていることがわかります。非クラスター化インデックスは1100万回書き込まれましたが、読み取られるのは2回だけです。

このカテゴリに分類されるインデックスを無効にすることから始め、問題が発生していないことを確認した後でインデックスを削除します。この演習を定期的に実行すると、システムへの不要なI / O書き込みを大幅に減らすことができますが、インデックスの使用統計は最後の再起動時と同じであることに注意してください。したがって、償却する前に、ビジネスサイクル全体のデータを収集していることを確認してください。 「役に立たない」というインデックス。
欠落しているインデックス
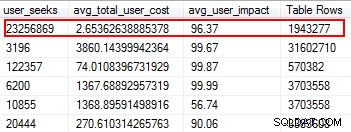
欠落しているインデックスは、修正するのが最も簡単なものの1つです。結局のところ、実行プランを実行すると、インデックスが見つからなかったかどうかがわかりますが、それは役に立ちました。ただし、この提案に基づいてインデックスを任意に追加するだけではないことを願っています。これを行うと、重複するインデックスが作成され、使用が最小限になる可能性があるインデックスが作成されるため、I/Oが無駄になります。繰り返しになりますが、Glennのスクリプトに戻ると、彼は、ユーザーのシーク、ユーザーへの影響、行数を提供することで、インデックスの有用性を評価するための優れたツールを提供してくれます。読み取りが高く、コストと影響が少ないものに注意してください。これは開始するのに最適な場所であり、読み取りI/Oを減らすのに役立ちます。
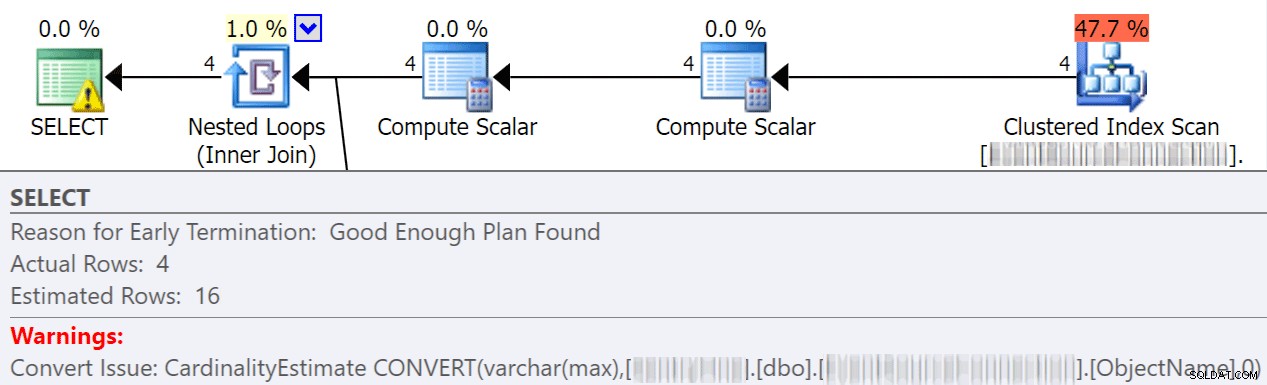
暗黙の変換
暗黙的な変換は、クエリが異なるデータ型の2つ以上の列を比較しているときによく発生します。以下の例では、varchar(max)列をnvarchar(4000)列と比較するために、システムが追加のI / Oを実行する必要があります。これにより、暗黙的な変換が行われ、最終的にはシークではなくスキャンが行われます。データ型が一致するようにテーブルを修正するか、評価前にこの値を変換するだけで、I / Oを大幅に削減し、カーディナリティ(オプティマイザーが期待する推定行数)を向上させることができます。
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayiasは、このすばらしい投稿でさらに詳しく説明しています。「列側の暗黙的な変換はどれくらいの費用がかかりますか?」
機能
I / O費用を節約するために私が遭遇した中で最も回避可能で修正が容易なことの1つは、where句から関数を削除することです。完璧な例は、以下に示すように、日付の比較です。
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
JOINステートメントにあるかWHERE句にあるかにかかわらず、これにより、評価される前に各列が変換されます。評価前にこれらの列を一時テーブルに変換するだけで、大量の不要なI/Oを排除できます。
または、さらに良いことに、変換をまったく実行しないでください(この特定のケースでは、Aaron Bertrandがwhere句の関数を回避することについてここで説明します。これは、日付への変換が仮可能であっても、依然として悪い可能性があることに注意してください)。
ETL
時間をかけて、データがどのようにロードされているかを調べてください。テーブルを切り捨ててリロードしていますか?代わりに、レプリケーション、読み取り専用のAGレプリカ、またはログ配布を実装できますか?すべてのテーブルが実際に読み取られるように書き込まれていますか?データをどのようにロードしていますか?それはストアドプロシージャまたはSSISを介したものですか?このようなことを調べると、I/Oを大幅に減らすことができます。
私の環境では、毎日48個のテーブルを切り捨てており、毎朝1億2,000万行を超えていることがわかりました。その上、1時間に960万行をロードしていました。どれだけの不要なI/Oが作成されたかを想像できます。私の場合、トランザクションレプリケーションの実装が私の選択したソリューションでした。実装すると、最初はストレージの速度が遅いことが原因であった、ロード時間中の速度低下に関するユーザーからの苦情がはるかに少なくなりました。
Order By&Group By
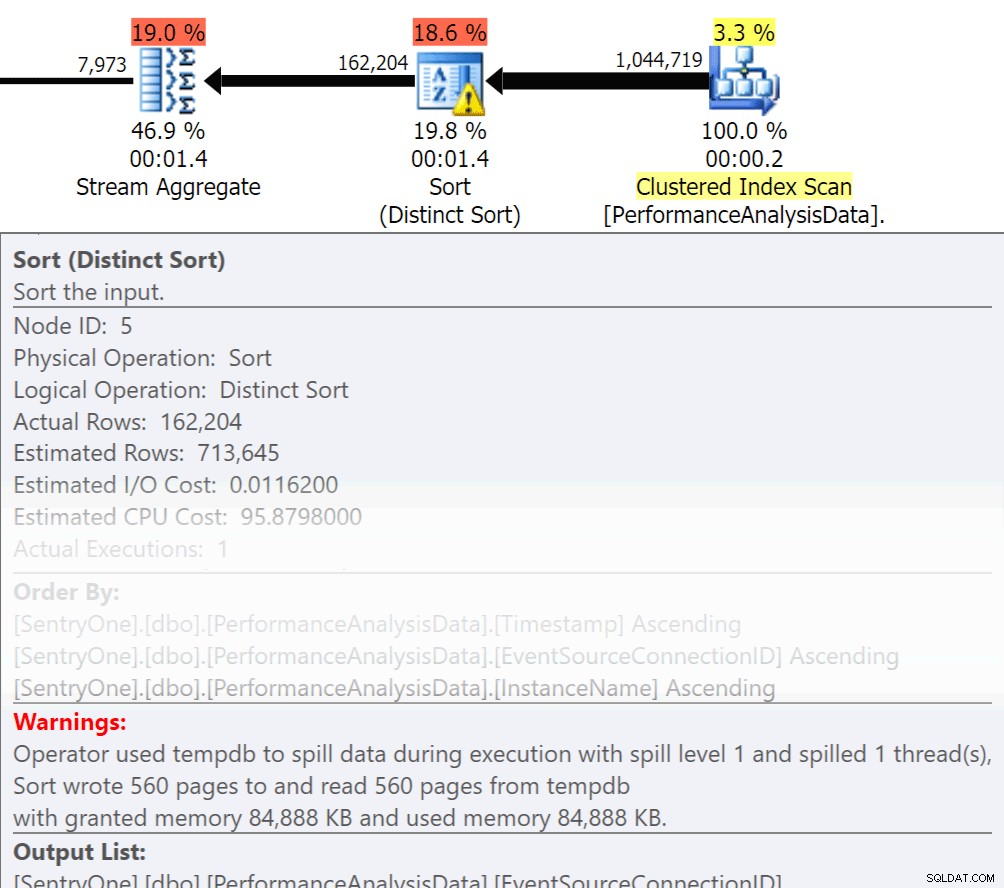 自問してみてください。そのデータは順番に返す必要がありますか?本当に手順をグループ化する必要がありますか、それともレポートやアプリケーションで処理できますか? OrderByおよびGroupBy操作により、読み取りがディスクに波及し、追加のディスクI/Oが発生する可能性があります。これらのアクションが必要な場合は、ソートまたはグループ化されている列にサポートインデックスと最新の統計があることを確認してください。これは、プランの作成中にオプティマイザを支援します。一時テーブルでOrderByとGroupByを使用することがあるためです。 TEMPDBおよびユーザーデータベースの統計の自動作成がオンになっていることを確認してください。統計が最新であるほど、オプティマイザーが取得できるカーディナリティが向上し、計画が改善され、スピルオーバーが減少し、I/Oが減少します。
自問してみてください。そのデータは順番に返す必要がありますか?本当に手順をグループ化する必要がありますか、それともレポートやアプリケーションで処理できますか? OrderByおよびGroupBy操作により、読み取りがディスクに波及し、追加のディスクI/Oが発生する可能性があります。これらのアクションが必要な場合は、ソートまたはグループ化されている列にサポートインデックスと最新の統計があることを確認してください。これは、プランの作成中にオプティマイザを支援します。一時テーブルでOrderByとGroupByを使用することがあるためです。 TEMPDBおよびユーザーデータベースの統計の自動作成がオンになっていることを確認してください。統計が最新であるほど、オプティマイザーが取得できるカーディナリティが向上し、計画が改善され、スピルオーバーが減少し、I/Oが減少します。
現在、Group Byは、大量の行を返すのではなく、データを集約するという点で間違いなくその役割を果たしています。ただし、ここで重要なのはI / Oを削減することです。集計を追加すると、I/Oが増加します。
概要
これらは氷山の一角に過ぎない種類のことですが、I/Oを削減し始めるのに最適な場所です。遅延の問題についてハードウェアのせいにする前に、ディスクの負荷を最小限に抑えるために何ができるかを見てください。
作者について
 Monica Rathbunは現在、Denny Cherry&Associates Consultingのコンサルタントであり、Microsoft DataPlatformMVPです。彼女は15年間LoneDBAであり、SQLServerとOracleのあらゆる側面に取り組んでいます。彼女はSQLSaturdaysで講演に出かけ、他のLoneDBAが多くの仕事をどのように行えるかについてのテクニックを手伝っています。モニカはハンプトンローズSQLServerユーザーグループのリーダーであり、中部大西洋岸の地域メンターです。モニカはツイッター(@SQLEspresso)でいつでも、フォロワーに役立つヒントやコツを教えてくれます。彼女が仕事で忙しくないときは、2人の娘がダンスクラスを行ったり来たりするためにタクシーの運転手をしているのがわかります。
Monica Rathbunは現在、Denny Cherry&Associates Consultingのコンサルタントであり、Microsoft DataPlatformMVPです。彼女は15年間LoneDBAであり、SQLServerとOracleのあらゆる側面に取り組んでいます。彼女はSQLSaturdaysで講演に出かけ、他のLoneDBAが多くの仕事をどのように行えるかについてのテクニックを手伝っています。モニカはハンプトンローズSQLServerユーザーグループのリーダーであり、中部大西洋岸の地域メンターです。モニカはツイッター(@SQLEspresso)でいつでも、フォロワーに役立つヒントやコツを教えてくれます。彼女が仕事で忙しくないときは、2人の娘がダンスクラスを行ったり来たりするためにタクシーの運転手をしているのがわかります。